ScanFormer: Referring Expression Comprehension by Iteratively Scanning

0

Sign in to get full access
Overview
• This paper presents a novel approach called ScanFormer for referring expression comprehension, which involves identifying the object in an image that corresponds to a given textual description.
• The key innovation of ScanFormer is an iterative scanning mechanism that allows the model to focus on different regions of the image in a step-by-step manner, gradually refining its understanding of the referred object.
• ScanFormer achieves state-of-the-art performance on several standard referring expression comprehension benchmarks, demonstrating the effectiveness of its iterative scanning approach.
Plain English Explanation
ScanFormer is a new technique for helping computers understand and locate the objects in an image that match a given textual description, also known as referring expression comprehension. The core idea behind ScanFormer is that it breaks down this task into a series of steps, where the model first looks at the entire image, then focuses on specific regions, and gradually refines its understanding until it can accurately identify the object being referred to.
This iterative scanning approach is more effective than having the model try to process the entire image and text description all at once. By breaking the problem down into smaller, more manageable steps, the model can better concentrate on the relevant details and ultimately arrive at a more accurate and robust understanding of the referred object.
The researchers who developed ScanFormer have shown that it outperforms other state-of-the-art methods on standard benchmark datasets for referring expression comprehension. This suggests that the iterative scanning approach is a promising direction for improving the ability of AI systems to understand and interact with the visual world in a more natural and human-like way.
Technical Explanation
The core innovation of ScanFormer is its iterative scanning mechanism, which allows the model to focus on different regions of the image in a step-by-step manner. This is achieved through the use of a transformer-based architecture that iteratively updates its attention over the image and text inputs.
At each step of the iterative scanning process, ScanFormer attends to a specific region of the image based on the current state of the model and the referring expression. The model then updates its internal representation of the referred object by incorporating the information from this focused image region. By repeating this process multiple times, ScanFormer is able to gradually refine its understanding of the referred object, ultimately identifying the correct region in the image.
The researchers evaluated ScanFormer on several standard referring expression comprehension benchmarks, including RefCOCO, RefCOCO+, and RefCOCOg. Their results demonstrate that ScanFormer outperforms previous state-of-the-art methods, highlighting the effectiveness of its iterative scanning approach.
Critical Analysis
The paper presents a well-designed and thorough evaluation of ScanFormer, including comparisons with a range of existing methods on multiple benchmark datasets. The researchers have done a commendable job in demonstrating the superiority of their approach.
However, one potential limitation of ScanFormer is its computational complexity, as the iterative scanning process may be more resource-intensive than single-shot approaches. The paper does not provide a detailed analysis of the model's inference time or memory requirements, which could be an area for further investigation.
Additionally, the paper does not address the generalization capabilities of ScanFormer to more diverse or challenging referring expressions, such as those involving complex spatial relationships or abstract concepts. Further research could explore the model's performance in these more challenging scenarios.
Conclusion
The ScanFormer approach represents a significant advancement in the field of referring expression comprehension, demonstrating the benefits of an iterative scanning mechanism for gradually refining the model's understanding of the referred object. By breaking down the task into a series of steps, ScanFormer is able to outperform previous state-of-the-art methods on standard benchmarks.
The success of ScanFormer highlights the potential for incorporating more human-like, step-by-step reasoning into AI systems for visual understanding tasks. As the field of computer vision continues to evolve, approaches like ScanFormer may pave the way for more natural and intuitive interactions between humans and machines.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ScanFormer: Referring Expression Comprehension by Iteratively Scanning
Wei Su, Peihan Miao, Huanzhang Dou, Xi Li
Referring Expression Comprehension (REC) aims to localize the target objects specified by free-form natural language descriptions in images. While state-of-the-art methods achieve impressive performance, they perform a dense perception of images, which incorporates redundant visual regions unrelated to linguistic queries, leading to additional computational overhead. This inspires us to explore a question: can we eliminate linguistic-irrelevant redundant visual regions to improve the efficiency of the model? Existing relevant methods primarily focus on fundamental visual tasks, with limited exploration in vision-language fields. To address this, we propose a coarse-to-fine iterative perception framework, called ScanFormer. It can iteratively exploit the image scale pyramid to extract linguistic-relevant visual patches from top to bottom. In each iteration, irrelevant patches are discarded by our designed informativeness prediction. Furthermore, we propose a patch selection strategy for discarded patches to accelerate inference. Experiments on widely used datasets, namely RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, verify the effectiveness of our method, which can strike a balance between accuracy and efficiency.
Read more6/27/2024

0
PlaceFormer: Transformer-based Visual Place Recognition using Multi-Scale Patch Selection and Fusion
Shyam Sundar Kannan, Byung-Cheol Min
Visual place recognition is a challenging task in the field of computer vision, and autonomous robotics and vehicles, which aims to identify a location or a place from visual inputs. Contemporary methods in visual place recognition employ convolutional neural networks and utilize every region within the image for the place recognition task. However, the presence of dynamic and distracting elements in the image may impact the effectiveness of the place recognition process. Therefore, it is meaningful to focus on task-relevant regions of the image for improved recognition. In this paper, we present PlaceFormer, a novel transformer-based approach for visual place recognition. PlaceFormer employs patch tokens from the transformer to create global image descriptors, which are then used for image retrieval. To re-rank the retrieved images, PlaceFormer merges the patch tokens from the transformer to form multi-scale patches. Utilizing the transformer's self-attention mechanism, it selects patches that correspond to task-relevant areas in an image. These selected patches undergo geometric verification, generating similarity scores across different patch sizes. Subsequently, spatial scores from each patch size are fused to produce a final similarity score. This score is then used to re-rank the images initially retrieved using global image descriptors. Extensive experiments on benchmark datasets demonstrate that PlaceFormer outperforms several state-of-the-art methods in terms of accuracy and computational efficiency, requiring less time and memory.
Read more5/29/2024

0
Calibration & Reconstruction: Deep Integrated Language for Referring Image Segmentation
Yichen Yan, Xingjian He, Sihan Chen, Jing Liu
Referring image segmentation aims to segment an object referred to by natural language expression from an image. The primary challenge lies in the efficient propagation of fine-grained semantic information from textual features to visual features. Many recent works utilize a Transformer to address this challenge. However, conventional transformer decoders can distort linguistic information with deeper layers, leading to suboptimal results. In this paper, we introduce CRFormer, a model that iteratively calibrates multi-modal features in the transformer decoder. We start by generating language queries using vision features, emphasizing different aspects of the input language. Then, we propose a novel Calibration Decoder (CDec) wherein the multi-modal features can iteratively calibrated by the input language features. In the Calibration Decoder, we use the output of each decoder layer and the original language features to generate new queries for continuous calibration, which gradually updates the language features. Based on CDec, we introduce a Language Reconstruction Module and a reconstruction loss. This module leverages queries from the final layer of the decoder to reconstruct the input language and compute the reconstruction loss. This can further prevent the language information from being lost or distorted. Our experiments consistently show the superior performance of our approach across RefCOCO, RefCOCO+, and G-Ref datasets compared to state-of-the-art methods.
Read more4/15/2024
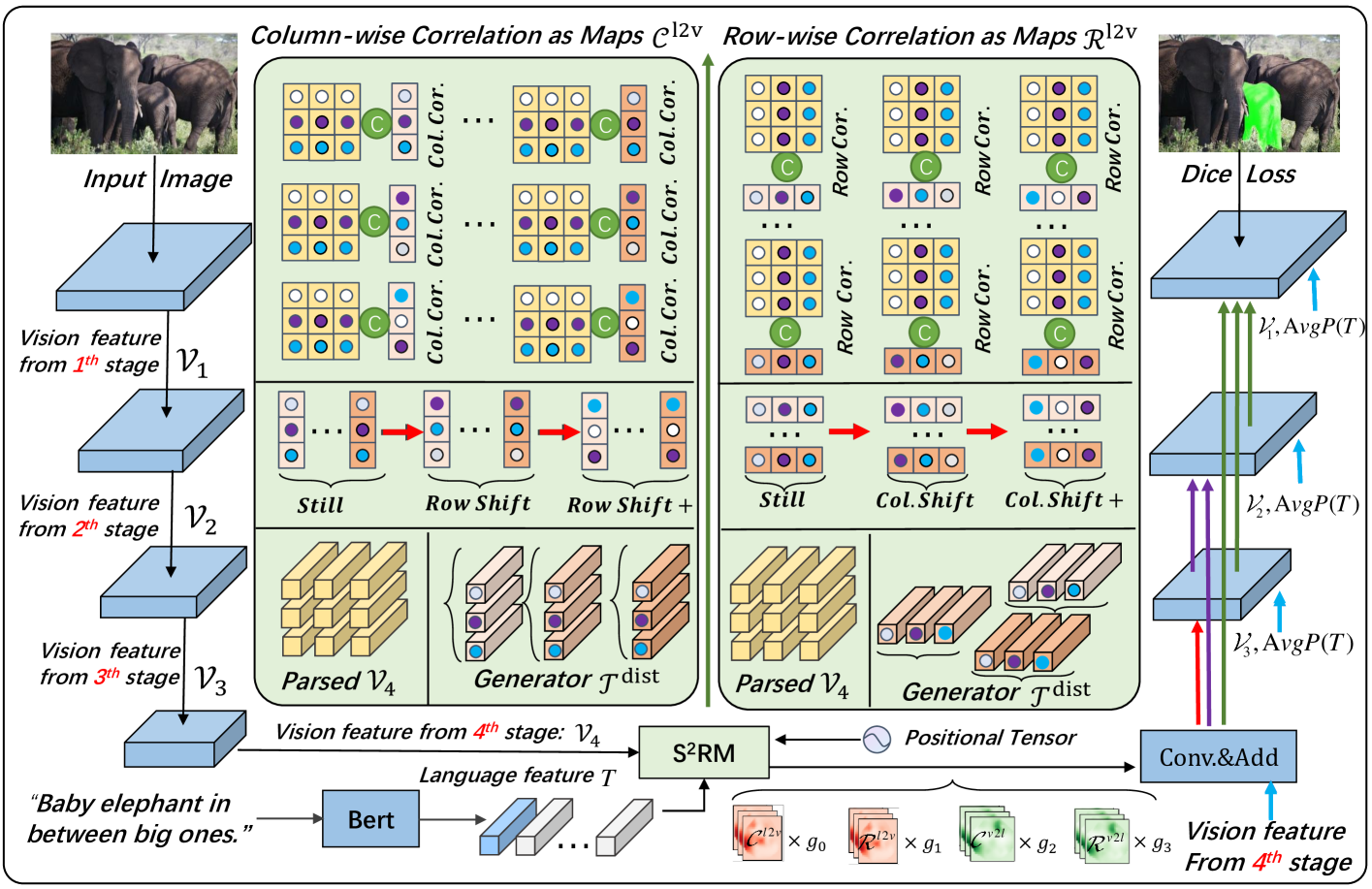
0
Spatial Semantic Recurrent Mining for Referring Image Segmentation
Jiaxing Yang, Lihe Zhang, Jiayu Sun, Huchuan Lu
Referring Image Segmentation (RIS) consistently requires language and appearance semantics to more understand each other. The need becomes acute especially under hard situations. To achieve, existing works tend to resort to various trans-representing mechanisms to directly feed forward language semantic along main RGB branch, which however will result in referent distribution weakly-mined in space and non-referent semantic contaminated along channel. In this paper, we propose Spatial Semantic Recurrent Mining (Stextsuperscript{2}RM) to achieve high-quality cross-modality fusion. It follows a working strategy of trilogy: distributing language feature, spatial semantic recurrent coparsing, and parsed-semantic balancing. During fusion, Stextsuperscript{2}RM will first generate a constraint-weak yet distribution-aware language feature, then bundle features of each row and column from rotated features of one modality context to recurrently correlate relevant semantic contained in feature from other modality context, and finally resort to self-distilled weights to weigh on the contributions of different parsed semantics. Via coparsing, Stextsuperscript{2}RM transports information from the near and remote slice layers of generator context to the current slice layer of parsed context, capable of better modeling global relationship bidirectional and structured. Besides, we also propose a Cross-scale Abstract Semantic Guided Decoder (CASG) to emphasize the foreground of the referent, finally integrating different grained features at a comparatively low cost. Extensive experimental results on four current challenging datasets show that our proposed method performs favorably against other state-of-the-art algorithms.
Read more5/16/2024