Reward Centering

0

Sign in to get full access
Overview
- Explains a technique called "reward centering" for improving reinforcement learning agents
- Explores simple and value-based approaches to reward centering
- Discusses potential benefits and limitations of reward centering
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to make good decisions by receiving rewards or punishments for its actions. However, sometimes these reward signals can lead the agent to optimize for the wrong things, a problem known as reward over-optimization.
The paper introduces "reward centering" as a potential solution to this issue. The key idea is to shift or "center" the reward function so that the agent is incentivized to maximize a more meaningful or well-rounded objective, rather than just blindly going after the maximum reward.
The paper explores two approaches to reward centering: a simple method that subtracts a constant from the rewards, and a more sophisticated "value-based" method that uses the agent's own value function to determine how to center the rewards.
By centering the rewards, the agent is encouraged to seek a balance between different aspects of the task, rather than single-mindedly pursuing the maximum reward. This can lead to more robust and desirable behaviors, especially in complex, open-ended environments where simple reward maximization can fail.
Technical Explanation
The paper first provides a theoretical framework for understanding reward centering and its potential benefits. It shows how reward centering can help align the agent's objective with the true underlying task, rather than just the proxy rewards.
The simple reward centering approach involves subtracting a constant from the rewards, effectively shifting the agent's focus away from maximizing the raw reward signal. The value-based approach goes further by using the agent's own estimate of the long-term value of each state to determine how to center the rewards.
The authors demonstrate these techniques in the context of a simple gridworld environment and a more complex continuous control task. They show that reward centering can lead to more robust and well-rounded policies, compared to standard reward maximization.
Critical Analysis
The paper provides a solid theoretical foundation for reward centering and demonstrates its potential benefits through empirical experiments. However, the authors acknowledge that the technique may have limitations, especially in complex, open-ended environments where the true underlying task is difficult to specify.
Additionally, the value-based approach to reward centering relies on the agent having an accurate estimate of the long-term value function, which can be challenging to learn, especially in more complex settings. The authors suggest that further research is needed to explore more robust ways of determining how to center the rewards.
Overall, the paper makes a compelling case for reward centering as a promising approach for improving the alignment between reinforcement learning agents and their intended objectives. However, as with any technique, it will likely have its own set of trade-offs and limitations that will need to be carefully considered in different applications.
Conclusion
The paper introduces the concept of "reward centering" as a way to improve the alignment between reinforcement learning agents and their intended objectives. By shifting or "centering" the reward function, the agent is encouraged to seek a balance between different aspects of the task, rather than single-mindedly pursuing the maximum reward.
The authors explore both simple and value-based approaches to reward centering, and demonstrate their potential benefits in various environments. While the technique shows promise, the authors also acknowledge its limitations and suggest that further research is needed to explore more robust ways of determining how to center the rewards.
Overall, the paper contributes to the growing body of work on reinforcement learning from diverse human preferences and addressing reward over-optimization, which are critical challenges for building AI systems that reliably and robustly pursue intended objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reward Centering
Abhishek Naik, Yi Wan, Manan Tomar, Richard S. Sutton
We show that discounted methods for solving continuing reinforcement learning problems can perform significantly better if they center their rewards by subtracting out the rewards' empirical average. The improvement is substantial at commonly used discount factors and increases further as the discount factor approaches one. In addition, we show that if a problem's rewards are shifted by a constant, then standard methods perform much worse, whereas methods with reward centering are unaffected. Estimating the average reward is straightforward in the on-policy setting; we propose a slightly more sophisticated method for the off-policy setting. Reward centering is a general idea, so we expect almost every reinforcement-learning algorithm to benefit by the addition of reward centering.
Read more5/17/2024

0
Analyzing and Bridging the Gap between Maximizing Total Reward and Discounted Reward in Deep Reinforcement Learning
Shuyu Yin, Fei Wen, Peilin Liu, Tao Luo
In deep reinforcement learning applications, maximizing discounted reward is often employed instead of maximizing total reward to ensure the convergence and stability of algorithms, even though the performance metric for evaluating the policy remains the total reward. However, the optimal policies corresponding to these two objectives may not always be consistent. To address this issue, we analyzed the suboptimality of the policy obtained through maximizing discounted reward in relation to the policy that maximizes total reward and identified the influence of hyperparameters. Additionally, we proposed sufficient conditions for aligning the optimal policies of these two objectives under various settings. The primary contributions are as follows: We theoretically analyzed the factors influencing performance when using discounted reward as a proxy for total reward, thereby enhancing the theoretical understanding of this scenario. Furthermore, we developed methods to align the optimal policies of the two objectives in certain situations, which can improve the performance of reinforcement learning algorithms.
Read more7/19/2024
🏅
0
Constrained Reinforcement Learning with Average Reward Objective: Model-Based and Model-Free Algorithms
Vaneet Aggarwal, Washim Uddin Mondal, Qinbo Bai
Reinforcement Learning (RL) serves as a versatile framework for sequential decision-making, finding applications across diverse domains such as robotics, autonomous driving, recommendation systems, supply chain optimization, biology, mechanics, and finance. The primary objective in these applications is to maximize the average reward. Real-world scenarios often necessitate adherence to specific constraints during the learning process. This monograph focuses on the exploration of various model-based and model-free approaches for Constrained RL within the context of average reward Markov Decision Processes (MDPs). The investigation commences with an examination of model-based strategies, delving into two foundational methods - optimism in the face of uncertainty and posterior sampling. Subsequently, the discussion transitions to parametrized model-free approaches, where the primal-dual policy gradient-based algorithm is explored as a solution for constrained MDPs. The monograph provides regret guarantees and analyzes constraint violation for each of the discussed setups. For the above exploration, we assume the underlying MDP to be ergodic. Further, this monograph extends its discussion to encompass results tailored for weakly communicating MDPs, thereby broadening the scope of its findings and their relevance to a wider range of practical scenarios.
Read more7/18/2024
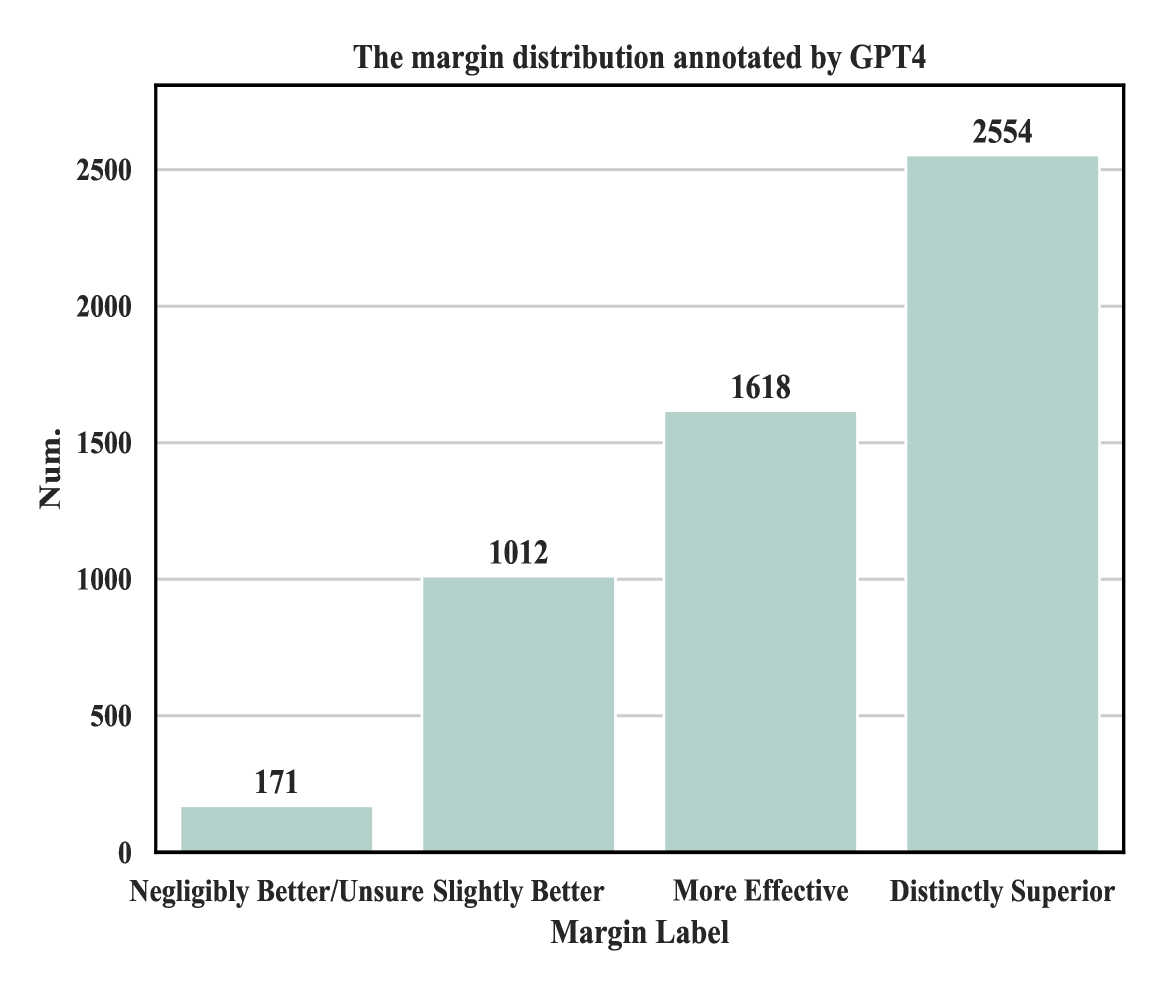
0
Towards Understanding the Influence of Reward Margin on Preference Model Performance
Bowen Qin, Duanyu Feng, Xi Yang
Reinforcement Learning from Human Feedback (RLHF) is a widely used framework for the training of language models. However, the process of using RLHF to develop a language model that is well-aligned presents challenges, especially when it comes to optimizing the reward model. Our research has found that existing reward models, when trained using the traditional ranking objective based on human preference data, often struggle to effectively distinguish between responses that are more or less favorable in real-world scenarios. To bridge this gap, our study introduces a novel method to estimate the preference differences without the need for detailed, exhaustive labels from human annotators. Our experimental results provide empirical evidence that incorporating margin values into the training process significantly improves the effectiveness of reward models. This comparative analysis not only demonstrates the superiority of our approach in terms of reward prediction accuracy but also highlights its effectiveness in practical applications.
Read more4/9/2024