Reward-Punishment Reinforcement Learning with Maximum Entropy

0

Sign in to get full access
Overview
- This paper introduces a new reinforcement learning (RL) algorithm called Reward-Punishment Reinforcement Learning with Maximum Entropy (RPRL-ME).
- The algorithm aims to learn optimal policies in environments with sparse rewards by incorporating both reward and punishment signals, while using a maximum entropy objective to encourage exploration.
- The authors demonstrate the effectiveness of RPRL-ME on a Turtlebot 3 robot navigation task, showing improved performance compared to other RL methods.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent, like a robot, learns to make good decisions by interacting with its environment and receiving rewards or punishments. In many real-world scenarios, the rewards the agent receives are sparse or infrequent, making it challenging to learn an optimal policy.
The RPRL-ME algorithm proposed in this paper addresses this challenge by incorporating both reward and punishment signals. The idea is that not only should the agent be rewarded for good actions, but it should also be punished for bad actions. This provides the agent with more feedback to learn from, helping it discover the optimal policy more efficiently.
Additionally, RPRL-ME uses a maximum entropy objective, which encourages the agent to explore a wider range of actions, rather than just exploiting what it has learned so far. This can help the agent discover better solutions that might have been missed otherwise.
The authors test the RPRL-ME algorithm on a robot navigation task, where a Turtlebot 3 robot has to navigate through an environment. They show that RPRL-ME outperforms other reinforcement learning methods in this task, demonstrating the benefits of using both reward and punishment signals, as well as the maximum entropy objective.
Technical Explanation
The RPRL-ME algorithm is built upon the Maximum Entropy GFlowNets and Sample-Efficient Constrained Reinforcement Learning approaches, which use a maximum entropy objective and constrained optimization, respectively.
In RPRL-ME, the agent learns a policy that maximizes a combination of rewards and punishments, with the goal of finding an optimal policy that balances both. The authors introduce a novel reward-punishment objective function that encourages the agent to take actions that maximize the expected long-term reward while minimizing the expected long-term punishment.
The algorithm also incorporates a maximum entropy regularization term, which helps the agent explore a wider range of actions and avoid getting stuck in local optima. This is similar to the approach used in Achieving Zero Constraint Violation in Constrained Reinforcement Learning.
The authors evaluate the RPRL-ME algorithm on a Turtlebot 3 robot navigation task, where the robot must navigate through an environment to reach a goal location. They compare the performance of RPRL-ME to other reinforcement learning methods, including Trajectory-Oriented Policy Optimization for Sparse Rewards and Differentially Private Reinforcement Learning, and show that RPRL-ME achieves superior performance.
Critical Analysis
The authors provide a thorough theoretical and experimental analysis of the RPRL-ME algorithm, and the results demonstrate its effectiveness in solving the robot navigation task. However, there are a few potential limitations and areas for further research:
-
Scalability to more complex environments: The authors only evaluate the algorithm on a relatively simple robot navigation task. It would be interesting to see how RPRL-ME performs in more complex environments with higher-dimensional state spaces and action spaces.
-
Sensitivity to hyperparameter tuning: As with many reinforcement learning algorithms, RPRL-ME may be sensitive to the choice of hyperparameters, such as the relative weighting of the reward and punishment signals. The authors should investigate the robustness of the algorithm to these hyperparameter settings.
-
Generalization to other domains: While the authors showcase the benefits of RPRL-ME on the robot navigation task, it would be valuable to test the algorithm on a wider range of reinforcement learning problems, such as continuous control tasks or multi-agent scenarios, to better understand its broader applicability.
-
Interpretability and explainability: As with many deep reinforcement learning approaches, the inner workings of the RPRL-ME algorithm may be opaque. It could be worthwhile to investigate methods for improving the interpretability and explainability of the learned policies, which could help build trust and facilitate real-world deployment.
Overall, the RPRL-ME algorithm presents a promising approach to reinforcement learning in sparse reward environments, and the authors have made a valuable contribution to the field. Further research to address the potential limitations and explore the algorithm's broader applicability would be a valuable next step.
Conclusion
The RPRL-ME algorithm introduced in this paper offers a novel approach to reinforcement learning by incorporating both reward and punishment signals, along with a maximum entropy objective. The authors demonstrate the effectiveness of this method on a robot navigation task, showing improved performance compared to other RL techniques.
The key insights of this work include the benefits of using both reward and punishment feedback, as well as the advantages of encouraging exploration through a maximum entropy objective. These findings have the potential to improve the performance and sample efficiency of reinforcement learning agents in a wide range of real-world applications, from robotics and autonomous systems to game AI and beyond.
While the authors have provided a strong initial evaluation, further research is needed to assess the scalability, robustness, and broader applicability of the RPRL-ME algorithm. Nonetheless, this paper represents an important step forward in the field of reinforcement learning, and its ideas are likely to inspire future advancements in this exciting and rapidly evolving area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reward-Punishment Reinforcement Learning with Maximum Entropy
Jiexin Wang, Eiji Uchibe
We introduce the ``soft Deep MaxPain'' (softDMP) algorithm, which integrates the optimization of long-term policy entropy into reward-punishment reinforcement learning objectives. Our motivation is to facilitate a smoother variation of operators utilized in the updating of action values beyond traditional ``max'' and ``min'' operators, where the goal is enhancing sample efficiency and robustness. We also address two unresolved issues from the previous Deep MaxPain method. Firstly, we investigate how the negated (``flipped'') pain-seeking sub-policy, derived from the punishment action value, collaborates with the ``min'' operator to effectively learn the punishment module and how softDMP's smooth learning operator provides insights into the ``flipping'' trick. Secondly, we tackle the challenge of data collection for learning the punishment module to mitigate inconsistencies arising from the involvement of the ``flipped'' sub-policy (pain-avoidance sub-policy) in the unified behavior policy. We empirically explore the first issue in two discrete Markov Decision Process (MDP) environments, elucidating the crucial advancements of the DMP approach and the necessity for soft treatments on the hard operators. For the second issue, we propose a probabilistic classifier based on the ratio of the pain-seeking sub-policy to the sum of the pain-seeking and goal-reaching sub-policies. This classifier assigns roll-outs to separate replay buffers for updating reward and punishment action-value functions, respectively. Our framework demonstrates superior performance in Turtlebot 3's maze navigation tasks under the ROS Gazebo simulation.
Read more5/21/2024
🏅
0
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
Chen-Hao Chao, Chien Feng, Wei-Fang Sun, Cheng-Kuang Lee, Simon See, Chun-Yi Lee
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
Read more5/24/2024

0
New!Average-Reward Maximum Entropy Reinforcement Learning for Underactuated Double Pendulum Tasks
Jean Seong Bjorn Choe, Bumkyu Choi, Jong-kook Kim
This report presents a solution for the swing-up and stabilisation tasks of the acrobot and the pendubot, developed for the AI Olympics competition at IROS 2024. Our approach employs the Average-Reward Entropy Advantage Policy Optimization (AR-EAPO), a model-free reinforcement learning (RL) algorithm that combines average-reward RL and maximum entropy RL. Results demonstrate that our controller achieves improved performance and robustness scores compared to established baseline methods in both the acrobot and pendubot scenarios, without the need for a heavily engineered reward function or system model. The current results are applicable exclusively to the simulation stage setup.
Read more9/16/2024
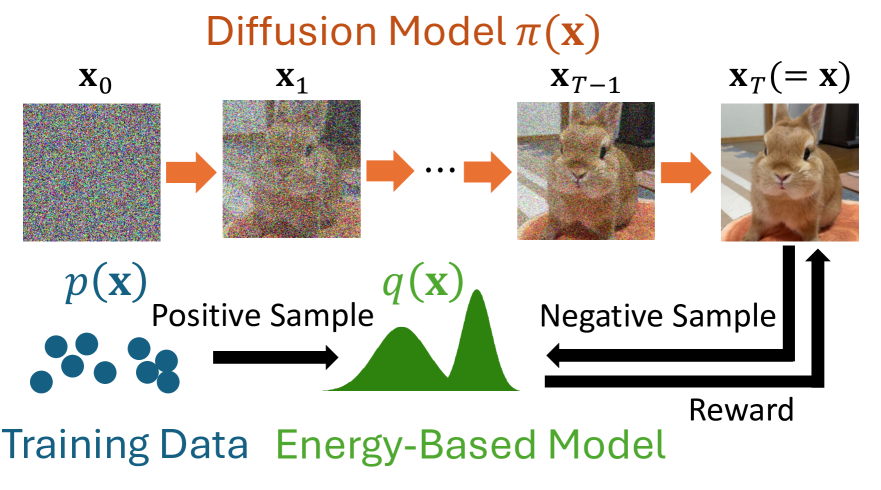
0
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
Sangwoong Yoon, Himchan Hwang, Dohyun Kwon, Yung-Kyun Noh, Frank C. Park
We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few as 4 and 10 steps. Additionally, DxMI enables the training of an EBM without MCMC, stabilizing EBM training dynamics and enhancing anomaly detection performance.
Read more7/2/2024