REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models

0
👁️
Sign in to get full access
Overview
- This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by incorporating both static and dynamic features, as well as utilizing both similar and dissimilar examples during training.
- The proposed approach is the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time.
- It is also the first code search technique that trains on both positive and negative reference samples.
- The authors validate the efficacy of their approach through a series of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search.
Plain English Explanation
The researchers have developed a new way to search for code snippets that is more effective than existing methods. Their technique involves training Large Language Models on a combination of code examples that are similar and dissimilar to the search query. This allows the model to better understand the context and nuances of the code, beyond just the syntax.
Typically, code search methods only use positive examples (i.e., code that is similar to the query). The researchers found that including negative examples (i.e., code that is different from the query) during training also improves the model's performance. This is because it helps the model learn what the code is not, in addition to what it is.
Another key innovation is that the researchers' approach can encode dynamic information about how the code behaves at runtime, without actually running the code. This allows the model to consider the functional aspects of the code, not just the static structure.
The researchers' approach outperforms existing cross-language code search tools by up to 44.7%, demonstrating the value of their enhanced training method. Their findings highlight the importance of carefully curating the training data, rather than just using larger language models without fine-tuning.
Technical Explanation
The paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by incorporating both static and dynamic features, as well as utilizing both similar and dissimilar examples during training.
The authors present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time. This is achieved by extracting and encoding relevant dynamic features, such as control flow and data dependencies, directly from the code.
The researchers also introduce the first code search technique that trains on both positive and negative reference samples. By including dissimilar code examples during training, the model learns to better distinguish relevant from irrelevant code, leading to improved search performance.
To validate the efficacy of their approach, the authors perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. The evaluation shows that the effectiveness of their method is consistent across various model architectures and programming languages, outperforming the state-of-the-art cross-language search tool by up to 44.7%.
The authors' ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements, underscoring the importance of both similar and dissimilar references for effective code search. The paper also highlights the significance of well-crafted, fine-tuned models, which can outperform enhanced larger modern LLMs without fine-tuning, even when enhancing the largest available LLMs.
Critical Analysis
The researchers acknowledge several caveats and areas for further research in their paper. For instance, they note that their approach relies on the availability of a diverse corpus of code examples, which may not always be the case in real-world scenarios. Additionally, the dynamic features they extract are limited to control flow and data dependencies, and there may be other runtime characteristics that could further improve the model's performance.
While the researchers demonstrate the effectiveness of their approach across various model architectures and programming languages, it would be valuable to see how it performs on a wider range of tasks, such as code summarization or code generation, to better understand its broader applicability.
Furthermore, the researchers do not provide a detailed analysis of the computational and memory requirements of their approach, which could be an important consideration for practical deployment, especially in resource-constrained environments.
Conclusion
The paper presents a novel code-to-code search technique that enhances the performance of Large Language Models by incorporating both static and dynamic features, as well as utilizing both similar and dissimilar examples during training. The researchers' approach outperforms the state-of-the-art cross-language search tool by up to 44.7%, demonstrating the value of their enhanced training method.
The key insights from this work include the importance of capturing dynamic runtime information, the benefits of training on both positive and negative reference samples, and the significance of carefully curating the training data, rather than relying solely on larger language models without fine-tuning. These findings have important implications for the development of more effective and versatile code search tools, which can play a crucial role in software engineering and developer productivity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
REINFOREST: Reinforcing Semantic Code Similarity for Cross-Lingual Code Search Models
Anthony Saieva, Saikat Chakraborty, Gail Kaiser
This paper introduces a novel code-to-code search technique that enhances the performance of Large Language Models (LLMs) by including both static and dynamic features as well as utilizing both similar and dissimilar examples during training. We present the first-ever code search method that encodes dynamic runtime information during training without the need to execute either the corpus under search or the search query at inference time and the first code search technique that trains on both positive and negative reference samples. To validate the efficacy of our approach, we perform a set of studies demonstrating the capability of enhanced LLMs to perform cross-language code-to-code search. Our evaluation demonstrates that the effectiveness of our approach is consistent across various model architectures and programming languages. We outperform the state-of-the-art cross-language search tool by up to 44.7%. Moreover, our ablation studies reveal that even a single positive and negative reference sample in the training process results in substantial performance improvements demonstrating both similar and dissimilar references are important parts of code search. Importantly, we show that enhanced well-crafted, fine-tuned models consistently outperform enhanced larger modern LLMs without fine tuning, even when enhancing the largest available LLMs highlighting the importance for open-sourced models. To ensure the reproducibility and extensibility of our research, we present an open-sourced implementation of our tool and training procedures called REINFOREST.
Read more4/17/2024
0
Rewriting the Code: A Simple Method for Large Language Model Augmented Code Search
Haochen Li, Xin Zhou, Zhiqi Shen
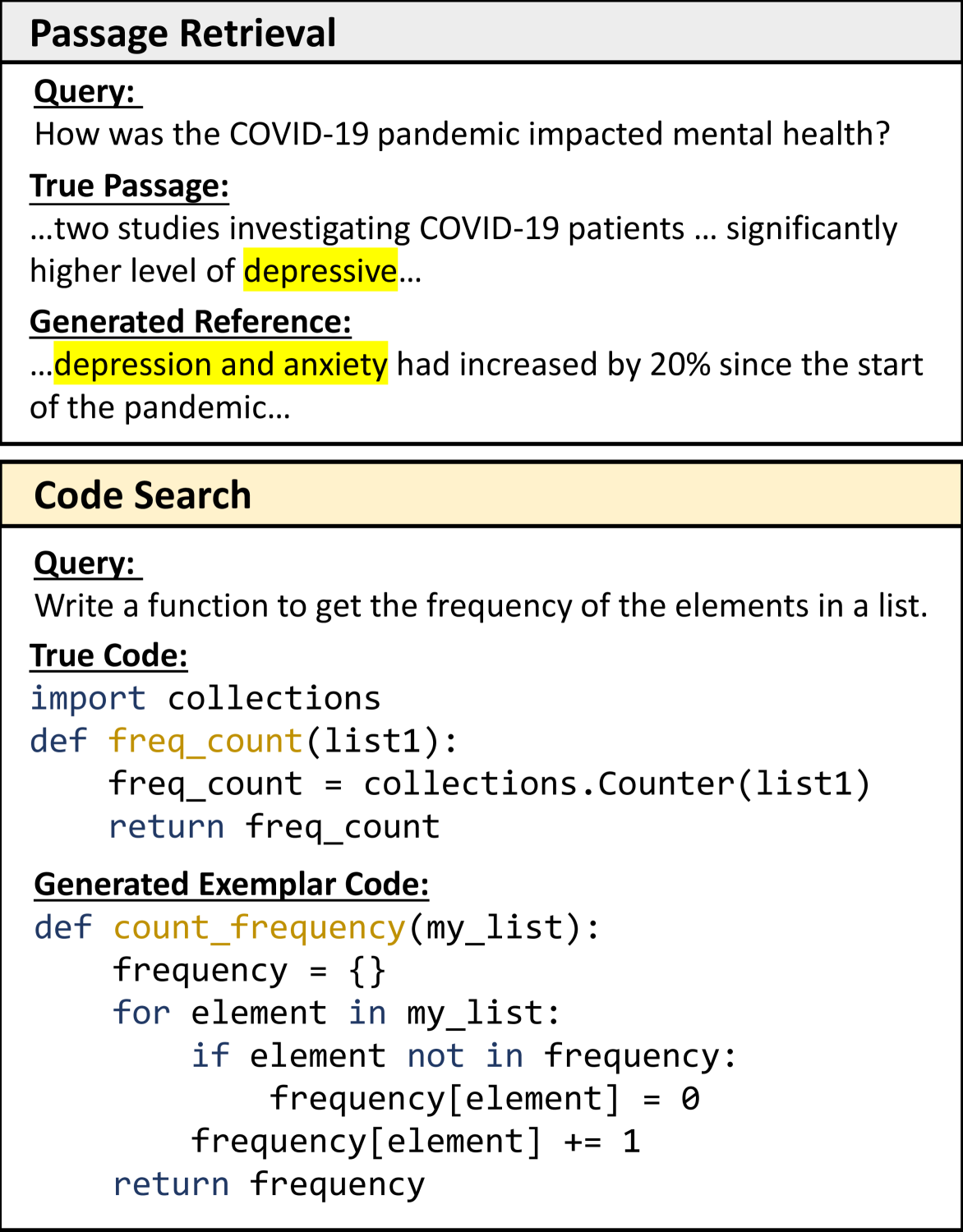
In code search, the Generation-Augmented Retrieval (GAR) framework, which generates exemplar code snippets to augment queries, has emerged as a promising strategy to address the principal challenge of modality misalignment between code snippets and natural language queries, particularly with the demonstrated code generation capabilities of Large Language Models (LLMs). Nevertheless, our preliminary investigations indicate that the improvements conferred by such an LLM-augmented framework are somewhat constrained. This limitation could potentially be ascribed to the fact that the generated codes, albeit functionally accurate, frequently display a pronounced stylistic deviation from the ground truth code in the codebase. In this paper, we extend the foundational GAR framework and propose a simple yet effective method that additionally Rewrites the Code (ReCo) within the codebase for style normalization. Experimental results demonstrate that ReCo significantly boosts retrieval accuracy across sparse (up to 35.7%), zero-shot dense (up to 27.6%), and fine-tuned dense (up to 23.6%) retrieval settings in diverse search scenarios. To further elucidate the advantages of ReCo and stimulate research in code style normalization, we introduce Code Style Similarity, the first metric tailored to quantify stylistic similarities in code. Notably, our empirical findings reveal the inadequacy of existing metrics in capturing stylistic nuances. The source code and data are available at url{https://github.com/Alex-HaochenLi/ReCo}.
Read more6/4/2024
0
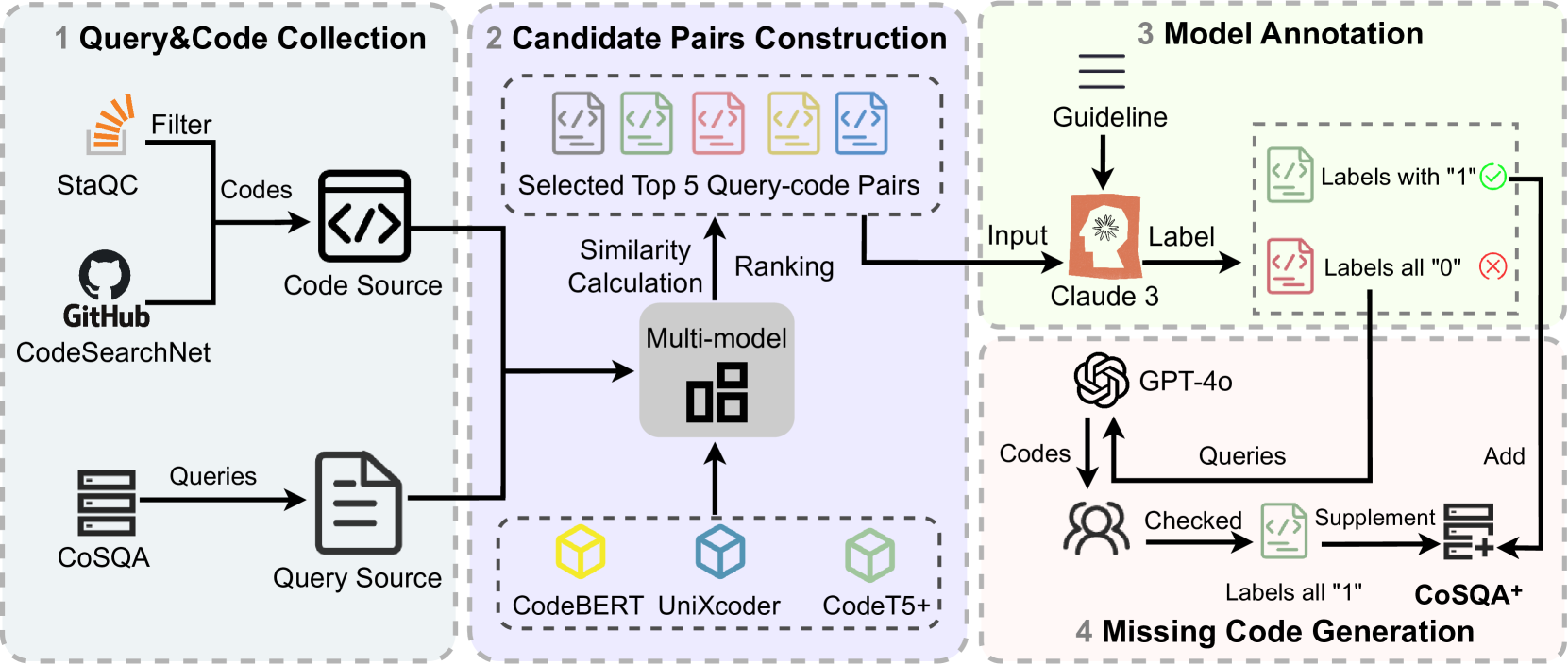
CoSQA+: Enhancing Code Search Dataset with Matching Code
Jing Gong, Yanghui Wu, Linxi Liang, Zibin Zheng, Yanlin Wang
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets are problematic: either using unrealistic queries, or with mismatched codes, and typically using one-to-one query-code pairing, which fails to reflect the reality that a query might have multiple valid code matches. This paper introduces CoSQA+, pairing high-quality queries (reused from CoSQA) with multiple suitable codes. We collect code candidates from diverse sources and form candidate pairs by pairing queries with these codes. Utilizing the power of large language models (LLMs), we automate pair annotation, filtering, and code generation for queries without suitable matches. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. Furthermore, we propose a new metric Mean Multi-choice Reciprocal Rank (MMRR), to assess one-to-N code search performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
Read more8/27/2024

0
Large Language Models for cross-language code clone detection
Micheline B'en'edicte Moumoula, Abdoul Kader Kabore, Jacques Klein, Tegawend'e Bissyande
With the involvement of multiple programming languages in modern software development, cross-lingual code clone detection has gained traction with the software engineering community. Numerous studies have explored this topic, proposing various promising approaches. Inspired by the significant advances in machine learning in recent years, particularly Large Language Models (LLMs), which have demonstrated their ability to tackle various tasks, this paper revisits cross-lingual code clone detection. We investigate the capabilities of four (04) LLMs and eight (08) prompts for the identification of cross-lingual code clones. Additionally, we evaluate a pre-trained embedding model to assess the effectiveness of the generated representations for classifying clone and non-clone pairs. Both studies (based on LLMs and Embedding models) are evaluated using two widely used cross-lingual datasets, XLCoST and CodeNet. Our results show that LLMs can achieve high F1 scores, up to 0.98, for straightforward programming examples (e.g., from XLCoST). However, they not only perform less well on programs associated with complex programming challenges but also do not necessarily understand the meaning of code clones in a cross-lingual setting. We show that embedding models used to represent code fragments from different programming languages in the same representation space enable the training of a basic classifier that outperforms all LLMs by ~2 and ~24 percentage points on the XLCoST and CodeNet datasets, respectively. This finding suggests that, despite the apparent capabilities of LLMs, embeddings provided by embedding models offer suitable representations to achieve state-of-the-art performance in cross-lingual code clone detection.
Read more8/13/2024