CodeRAG-Bench: Can Retrieval Augment Code Generation?
2406.14497
0
0

Abstract
While language models (LMs) have proven remarkably adept at generating code, many programs are challenging for LMs to generate using their parametric knowledge alone. Providing external contexts such as library documentation can facilitate generating accurate and functional code. Despite the success of retrieval-augmented generation (RAG) in various text-oriented tasks, its potential for improving code generation remains under-explored. In this work, we conduct a systematic, large-scale analysis by asking: in what scenarios can retrieval benefit code generation models? and what challenges remain? We first curate a comprehensive evaluation benchmark, CodeRAG-Bench, encompassing three categories of code generation tasks, including basic programming, open-domain, and repository-level problems. We aggregate documents from five sources for models to retrieve contexts: competition solutions, online tutorials, library documentation, StackOverflow posts, and GitHub repositories. We examine top-performing models on CodeRAG-Bench by providing contexts retrieved from one or multiple sources. While notable gains are made in final code generation by retrieving high-quality contexts across various settings, our analysis reveals room for improvement -- current retrievers still struggle to fetch useful contexts especially with limited lexical overlap, and generators fail to improve with limited context lengths or abilities to integrate additional contexts. We hope CodeRAG-Bench serves as an effective testbed to encourage further development of advanced code-oriented RAG methods.
Create account to get full access
Overview
- The paper introduces CodeRAG-Bench, a new benchmark for evaluating the effectiveness of retrieval-augmented code generation.
- CodeRAG-Bench consists of a diverse set of coding tasks and a corresponding dataset to assess how well retrieval-based methods can complement traditional code generation models.
- The authors conduct extensive experiments to understand the potential benefits and limitations of retrieval-augmented code generation, providing insights for future research in this area.
Plain English Explanation
The paper is about a new testing system called CodeRAG-Bench that helps researchers and developers understand how well AI models can generate code by combining traditional code generation with information retrieval.
The key idea is that instead of just generating code from scratch, the model can also search for and retrieve relevant code snippets from a database. By combining the generated code with the retrieved code, the model may be able to produce more accurate and useful code for the given task.
CodeRAG-Bench provides a diverse set of coding tasks and data to evaluate how well these retrieval-augmented code generation models perform. The authors run many experiments to see the advantages and drawbacks of this approach, with the goal of guiding future research and development in this important area of AI-powered coding assistance.
Technical Explanation
The paper introduces the CodeRAG-Bench, a new benchmark designed to assess the effectiveness of retrieval-augmented code generation. CodeRAG-Bench consists of a diverse set of coding tasks and a corresponding dataset, enabling researchers to evaluate how well retrieval-based methods can complement traditional code generation models.
The authors conduct extensive experiments to understand the potential benefits and limitations of retrieval-augmented code generation. They explore different retrieval strategies, including sparse retrieval and incorporating retrieval information, and analyze their impact on code generation performance across a range of coding tasks.
Critical Analysis
The paper provides a comprehensive evaluation of retrieval-augmented code generation, highlighting both the potential benefits and the limitations of this approach. The authors acknowledge that the effectiveness of retrieval-augmented methods can vary depending on the specific coding task and the quality of the retrieved code snippets.
One potential limitation is that the CodeRAG-Bench dataset may not fully capture the diversity and complexity of real-world coding tasks. Additionally, the experiments focus on relatively short code snippets, and it remains to be seen how well the retrieval-augmented approach would scale to larger, more complex code projects.
Further research is needed to address these challenges and explore more advanced techniques for effectively integrating retrieval and generation in the context of code development.
Conclusion
The CodeRAG-Bench paper presents a comprehensive evaluation of retrieval-augmented code generation, a promising approach that combines traditional code generation with information retrieval to improve the quality and relevance of generated code.
The authors' extensive experiments provide valuable insights into the potential benefits and limitations of this approach, offering a roadmap for future research and development in this important area of AI-powered coding assistance. As the demand for efficient and effective code generation tools continues to grow, the insights from this work can help guide the evolution of these technologies and their real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Repoformer: Selective Retrieval for Repository-Level Code Completion
Di Wu, Wasi Uddin Ahmad, Dejiao Zhang, Murali Krishna Ramanathan, Xiaofei Ma
0
0
Recent advances in retrieval-augmented generation (RAG) have initiated a new era in repository-level code completion. However, the invariable use of retrieval in existing methods exposes issues in both efficiency and robustness, with a large proportion of the retrieved contexts proving unhelpful or harmful to code language models (code LMs). In this paper, we propose a selective RAG framework to avoid retrieval when unnecessary. To power this framework, we design a self-supervised learning approach to enable a code LM to accurately self-evaluate whether retrieval can improve its output quality and robustly leverage the potentially noisy retrieved contexts. Using this LM as both the selective RAG policy and the generation model, our framework achieves state-of-the-art repository-level code completion performance on diverse benchmarks including RepoEval, CrossCodeEval, and CrossCodeLongEval, a new long-form code completion benchmark. Meanwhile, our analyses show that selectively retrieving brings as much as 70% inference speedup in the online serving setting without harming the performance. We further demonstrate that our framework is able to accommodate different generation models, retrievers, and programming languages. These advancements position our framework as an important step towards more accurate and efficient repository-level code completion.
6/5/2024
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has recently gained traction in natural language processing. Numerous studies and real-world applications are leveraging its ability to enhance generative models through external information retrieval. Evaluating these RAG systems, however, poses unique challenges due to their hybrid structure and reliance on dynamic knowledge sources. To better understand these challenges, we conduct A Unified Evaluation Process of RAG (Auepora) and aim to provide a comprehensive overview of the evaluation and benchmarks of RAG systems. Specifically, we examine and compare several quantifiable metrics of the Retrieval and Generation components, such as relevance, accuracy, and faithfulness, within the current RAG benchmarks, encompassing the possible output and ground truth pairs. We then analyze the various datasets and metrics, discuss the limitations of current benchmarks, and suggest potential directions to advance the field of RAG benchmarks.
7/4/2024
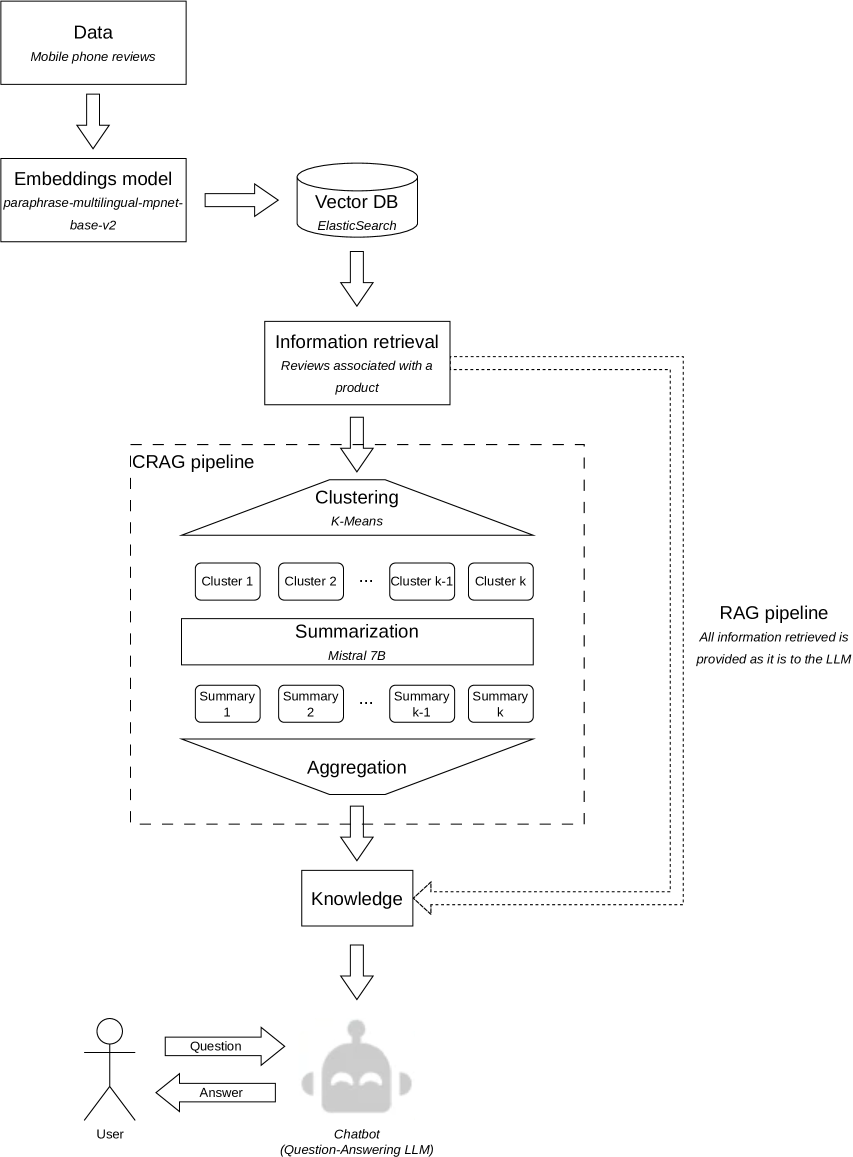
Clustered Retrieved Augmented Generation (CRAG)
Simon Akesson, Frances A. Santos
0
0
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46%, achieving more than 90% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.
6/4/2024
🛸
New!Retrieval-augmented generation in multilingual settings
Nadezhda Chirkova, David Rau, Herv'e D'ejean, Thibault Formal, St'ephane Clinchant, Vassilina Nikoulina
0
0
Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
7/2/2024