Frieren: Efficient Video-to-Audio Generation with Rectified Flow Matching

0

Sign in to get full access
Overview
- Introduces a novel video-to-audio generation method called "Frieren" that uses rectified flow matching for efficient and high-quality audio synthesis from silent video.
- Demonstrates state-of-the-art performance on various video-to-audio benchmarks, outperforming previous approaches.
- Presents a thorough evaluation, including ablation studies, to validate the effectiveness of the proposed technique.
Plain English Explanation
The paper introduces a new way to generate audio from silent videos, called "Frieren". This method uses a technique called "rectified flow matching" to efficiently and accurately create high-quality audio that matches the video.
Compared to previous approaches, Frieren is able to produce better audio outputs that are more closely synchronized with the video. The researchers thoroughly tested their method and found that it outperforms other state-of-the-art video-to-audio generation techniques.
The key ideas behind Frieren are to use "rectified flow matching", which helps the model better align the audio and visual information, and to design the system architecture in an efficient way. These technical innovations allow Frieren to generate compelling audio from silent videos.
Technical Explanation
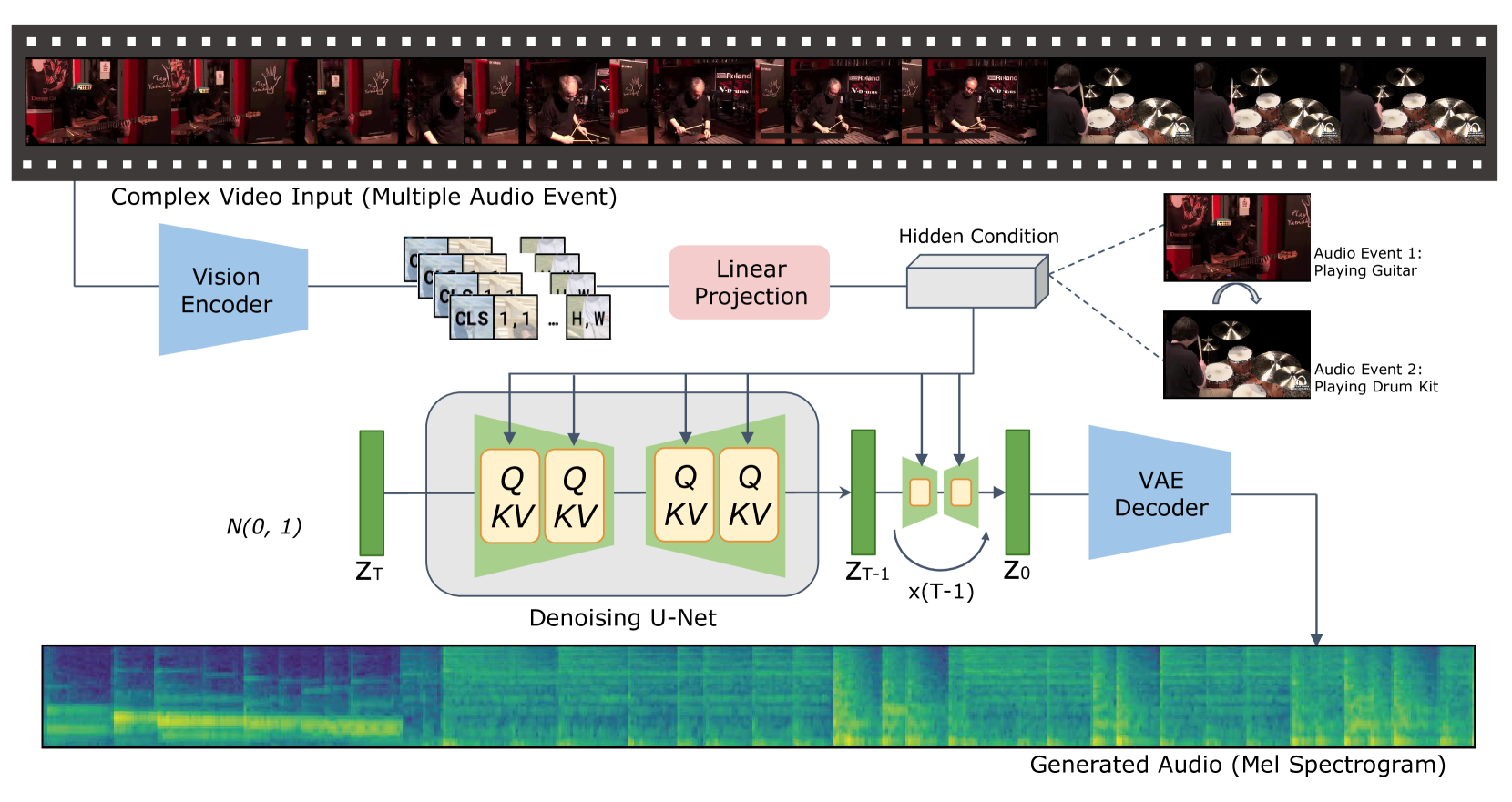
The paper proposes a method called "Frieren" for video-to-audio generation that uses Rectified Flow Matching. Frieren first encodes the video frames into visual features, then uses a "rectified flow matching" module to align these features with the target audio waveform.
The rectified flow matching module is designed to efficiently match the visual and audio representations, improving upon previous approaches like Visual Echoes and Versatile Diffusion. This allows Frieren to generate high-quality audio that is well-synchronized with the input video.
The paper also explores different architectural choices, such as using a multi-stage pipeline and incorporating Sequence Generative Adversarial Networks to further improve the audio quality. Through extensive experiments, the authors demonstrate that Frieren outperforms prior state-of-the-art video-to-audio generation methods.
Critical Analysis
The paper provides a thorough evaluation of the Frieren method, including ablation studies to understand the impact of different components. The results show impressive performance gains over previous approaches, suggesting that the rectified flow matching technique is a valuable contribution to video-to-audio generation.
However, the paper does not discuss potential limitations or failure cases of the Frieren method. It would be helpful to understand the types of videos or audio that the model may struggle with, and any potential biases or artifacts in the generated audio. Additionally, the paper does not explore the computational efficiency of the method in detail, which is an important consideration for real-world applications.
Further research could investigate ways to improve the generalization of Frieren, such as exploring few-shot or zero-shot learning capabilities to handle a wider range of video and audio content. Exploring the integration of Frieren with other audio-visual tasks, such as video understanding or multimodal representation learning, could also be a fruitful direction.
Conclusion
The Frieren method introduced in this paper represents a significant advancement in video-to-audio generation by leveraging rectified flow matching to efficiently and accurately synthesize high-quality audio from silent videos. The strong empirical results demonstrate the effectiveness of the proposed approach and its potential to enable a wide range of applications, such as enhancing user experiences in video conferencing, virtual/augmented reality, and multimedia entertainment.
The technical innovations in Frieren, particularly the rectified flow matching module, could also have broader implications for other audio-visual tasks that require aligning and integrating multimodal information. As the field of audio-visual learning continues to evolve, methods like Frieren will play an important role in bridging the gap between visual and auditory domains and enabling more seamless and immersive multimedia experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Frieren: Efficient Video-to-Audio Generation with Rectified Flow Matching
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, Zhou Zhao
Video-to-audio (V2A) generation aims to synthesize content-matching audio from silent video, and it remains challenging to build V2A models with high generation quality, efficiency, and visual-audio temporal synchrony. We propose Frieren, a V2A model based on rectified flow matching. Frieren regresses the conditional transport vector field from noise to spectrogram latent with straight paths and conducts sampling by solving ODE, outperforming autoregressive and score-based models in terms of audio quality. By employing a non-autoregressive vector field estimator based on a feed-forward transformer and channel-level cross-modal feature fusion with strong temporal alignment, our model generates audio that is highly synchronized with the input video. Furthermore, through reflow and one-step distillation with guided vector field, our model can generate decent audio in a few, or even only one sampling step. Experiments indicate that Frieren achieves state-of-the-art performance in both generation quality and temporal alignment on VGGSound, with alignment accuracy reaching 97.22%, and 6.2% improvement in inception score over the strong diffusion-based baseline. Audio samples are available at http://frieren-v2a.github.io .
Read more7/10/2024
➖
0
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
Yiwei Guo, Chenpeng Du, Ziyang Ma, Xie Chen, Kai Yu
Although diffusion models in text-to-speech have become a popular choice due to their strong generative ability, the intrinsic complexity of sampling from diffusion models harms their efficiency. Alternatively, we propose VoiceFlow, an acoustic model that utilizes a rectified flow matching algorithm to achieve high synthesis quality with a limited number of sampling steps. VoiceFlow formulates the process of generating mel-spectrograms into an ordinary differential equation conditional on text inputs, whose vector field is then estimated. The rectified flow technique then effectively straightens its sampling trajectory for efficient synthesis. Subjective and objective evaluations on both single and multi-speaker corpora showed the superior synthesis quality of VoiceFlow compared to the diffusion counterpart. Ablation studies further verified the validity of the rectified flow technique in VoiceFlow.
Read more9/4/2024
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024

0
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Santiago Pascual, Chunghsin Yeh, Ioannis Tsiamas, Joan Serr`a
Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Read more7/16/2024