Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models

0
🏷️
Sign in to get full access
Overview
- The paper introduces a new preconditioner for the popular Low-Rank Adaptation (LoRA) fine-tuning method, which can improve the convergence and reliability of the optimization process.
- The proposed preconditioner is derived from a novel Riemannian metric in the low-rank matrix field and requires only a small change to existing optimizer code.
- Experiments on large language models and text-to-image diffusion models show that the new preconditioner can significantly enhance the training process, making it more robust to hyperparameter choices.
Plain English Explanation
The paper discusses a technique called Low-Rank Adaptation (LoRA), which is a popular way to fine-tune pre-trained machine learning models without having to update all of the model's parameters. Instead, LoRA only updates a small, low-rank matrix, which can make the fine-tuning process more efficient.
The researchers in this paper have found a way to improve the LoRA training process by introducing a special preconditioner. A preconditioner is a mathematical transformation that can help stabilize the optimization process and make it converge more quickly. The new preconditioner proposed in this paper is derived from a novel Riemannian metric, which is a way of measuring distances in the space of low-rank matrices.
The researchers show that this new preconditioner can significantly improve the convergence and reliability of the optimization algorithms used in LoRA, like Stochastic Gradient Descent (SGD) and AdamW. It also makes the training process more robust to the choice of hyperparameters, such as the learning rate.
The researchers tested their new preconditioner on both large language models and text-to-image diffusion models. The results showed that the preconditioner can provide significant improvements in the training process, making it more efficient and reliable.
Technical Explanation
The paper proposes a new preconditioner for the Low-Rank Adaptation (LoRA) fine-tuning method. LoRA is a parameter-efficient fine-tuning (PEFT) technique that freezes the pre-trained model weights and updates an additive low-rank trainable matrix instead of updating all the model parameters.
The key insight of this paper is to introduce an $r \times r$ preconditioner in each gradient step, where $r$ is the LoRA rank. The researchers theoretically verify that this preconditioner stabilizes feature learning with LoRA under an infinite-width neural network setting.
Empirically, the implementation of this new preconditioner requires only a small change to existing optimizer code and creates virtually negligible storage and runtime overhead. The researchers conduct experiments on both large language models and text-to-image diffusion models. The results show that with this new preconditioner, the convergence and reliability of SGD and AdamW can be significantly enhanced. Moreover, the training process becomes much more robust to hyperparameter choices, such as the learning rate.
The new preconditioner is derived from a novel Riemannian metric in the low-rank matrix field, which provides a principled way of measuring distances in the space of low-rank matrices.
Critical Analysis
The paper introduces a novel and promising approach to improving the LoRA fine-tuning method, which is an important area of research in parameter-efficient fine-tuning (PEFT). The proposed preconditioner is theoretically grounded and empirically shown to provide significant benefits in terms of convergence, reliability, and robustness to hyperparameter choices.
One potential limitation of the work is that the theoretical analysis is based on an infinite-width neural network setting, which may not fully capture the behavior of real-world, finite-width models. Additionally, the paper does not explore the interactions between the proposed preconditioner and other PEFT techniques, such as Orthonormal LoRA or High-Rank Updating. Further research in these areas could provide additional insights and practical guidance for deploying the new preconditioner in real-world scenarios.
Overall, the paper presents a valuable contribution to the field of parameter-efficient fine-tuning and encourages readers to think critically about the trade-offs and potential applications of the proposed approach.
Conclusion
The paper introduces a new preconditioner for the Low-Rank Adaptation (LoRA) fine-tuning method, which can significantly improve the convergence and reliability of the optimization process. The proposed preconditioner is derived from a novel Riemannian metric in the low-rank matrix field and requires only a small change to existing optimizer code.
The experimental results on both large language models and text-to-image diffusion models demonstrate the effectiveness of the new preconditioner, showing that it can enhance the training process and make it more robust to hyperparameter choices. This work contributes to the ongoing research in parameter-efficient fine-tuning (PEFT), a crucial area for making large pre-trained models more accessible and applicable in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models
Fangzhao Zhang, Mert Pilanci
Low-Rank Adaptation (LoRA) emerges as a popular parameter-efficient fine-tuning (PEFT) method, which proposes to freeze pretrained model weights and update an additive low-rank trainable matrix. In this work, we study the enhancement of LoRA training by introducing an $r times r$ preconditioner in each gradient step where $r$ is the LoRA rank. We theoretically verify that the proposed preconditioner stabilizes feature learning with LoRA under infinite-width NN setting. Empirically, the implementation of this new preconditioner requires a small change to existing optimizer code and creates virtually minuscule storage and runtime overhead. Our experimental results with both large language models and text-to-image diffusion models show that with this new preconditioner, the convergence and reliability of SGD and AdamW can be significantly enhanced. Moreover, the training process becomes much more robust to hyperparameter choices such as learning rate. The new preconditioner can be derived from a novel Riemannian metric in low-rank matrix field. Code can be accessed at https://github.com/pilancilab/Riemannian_Preconditioned_LoRA.
Read more6/6/2024

0
LoRA-GA: Low-Rank Adaptation with Gradient Approximation
Shaowen Wang, Linxi Yu, Jian Li
Fine-tuning large-scale pretrained models is prohibitively expensive in terms of computational and memory costs. LoRA, as one of the most popular Parameter-Efficient Fine-Tuning (PEFT) methods, offers a cost-effective alternative by fine-tuning an auxiliary low-rank model that has significantly fewer parameters. Although LoRA reduces the computational and memory requirements significantly at each iteration, extensive empirical evidence indicates that it converges at a considerably slower rate compared to full fine-tuning, ultimately leading to increased overall compute and often worse test performance. In our paper, we perform an in-depth investigation of the initialization method of LoRA and show that careful initialization (without any change of the architecture and the training algorithm) can significantly enhance both efficiency and performance. In particular, we introduce a novel initialization method, LoRA-GA (Low Rank Adaptation with Gradient Approximation), which aligns the gradients of low-rank matrix product with those of full fine-tuning at the first step. Our extensive experiments demonstrate that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning (hence being significantly faster than vanilla LoRA as well as various recent improvements) while simultaneously attaining comparable or even better performance. For example, on the subset of the GLUE dataset with T5-Base, LoRA-GA outperforms LoRA by 5.69% on average. On larger models such as Llama 2-7B, LoRA-GA shows performance improvements of 0.34, 11.52%, and 5.05% on MT-bench, GSM8K, and Human-eval, respectively. Additionally, we observe up to 2-4 times convergence speed improvement compared to vanilla LoRA, validating its effectiveness in accelerating convergence and enhancing model performance. Code is available at https://github.com/Outsider565/LoRA-GA.
Read more7/17/2024

0
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
Minyoung Huh, Brian Cheung, Jeremy Bernstein, Phillip Isola, Pulkit Agrawal
The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model finetuning, its application in model pre-training remains largely unexplored. This paper explores extending LoRA to model pre-training, identifying the inherent constraints and limitations of standard LoRA in this context. We introduce LoRA-the-Explorer (LTE), a novel bi-level optimization algorithm designed to enable parallel training of multiple low-rank heads across computing nodes, thereby reducing the need for frequent synchronization. Our approach includes extensive experimentation on vision transformers using various vision datasets, demonstrating that LTE is competitive with standard pre-training.
Read more7/30/2024
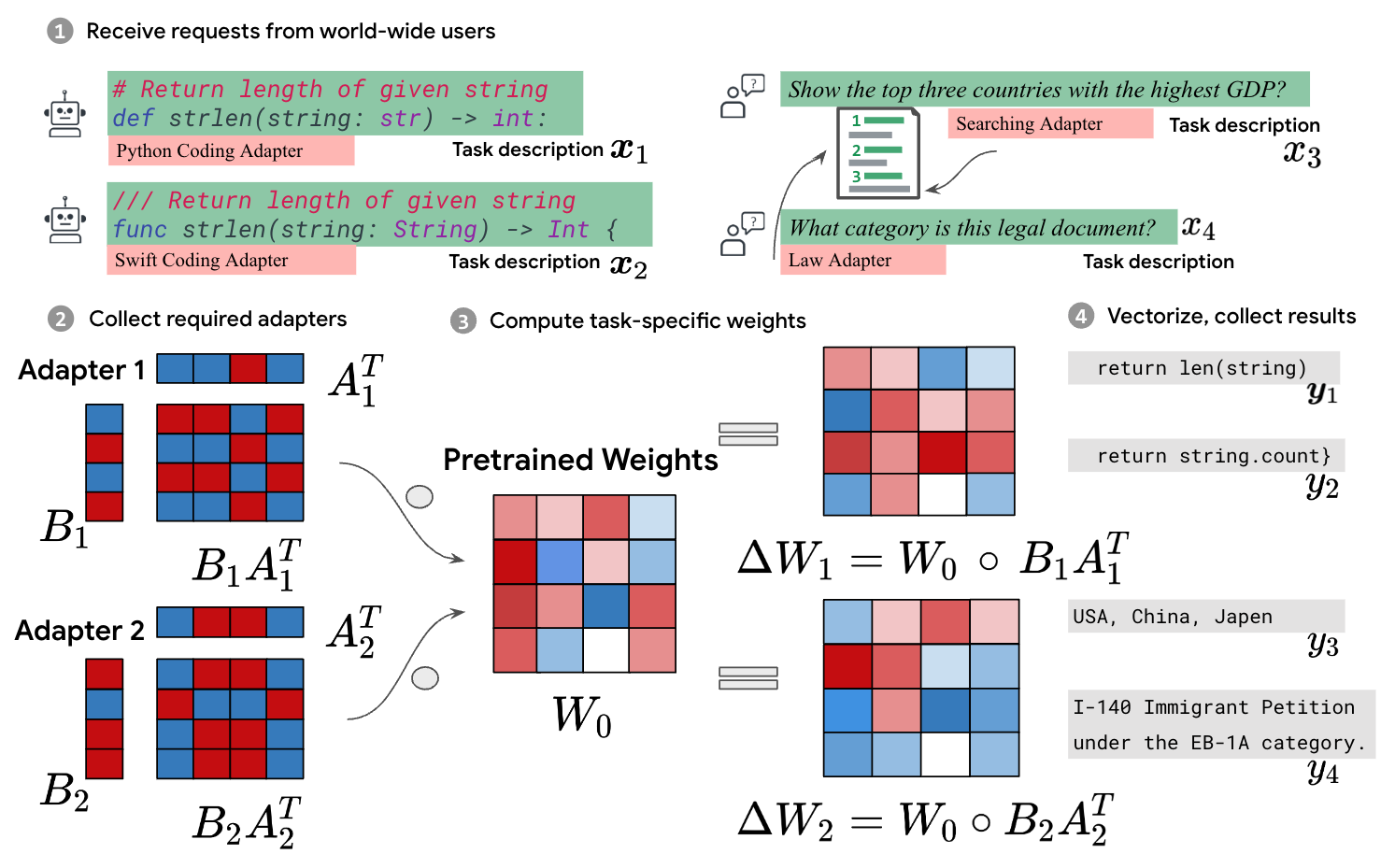
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024