Risk and cross validation in ridge regression with correlated samples

0

Sign in to get full access
Overview
- This paper investigates the impact of correlated samples on the performance of ridge regression and cross-validation techniques.
- The authors analyze the risk and generalization properties of ridge regression in the presence of correlated data.
- They propose an approach to accurately estimate the risk of ridge regression models and demonstrate its advantages over traditional cross-validation methods.
Plain English Explanation
The paper explores the challenges of using ridge regression, a popular machine learning technique, when the data samples are correlated. Typically, machine learning models are trained on independent data samples, but in many real-world scenarios, the data can be interdependent or correlated. This correlation can significantly impact the performance and reliability of the models.
The authors investigate how the presence of correlated data affects the risk, or expected error, of ridge regression models. They develop a method to more accurately estimate the risk of these models, which is important for selecting the best model and tuning its parameters. This is a critical step in building effective machine learning systems, as accurately estimating the model's performance is essential for making informed decisions.
The proposed approach offers advantages over traditional cross-validation techniques, which may not work as well when the data is correlated. By accounting for the correlation structure, the authors' method can provide more reliable risk estimates, leading to better model selection and ultimately, more accurate predictions.
Technical Explanation
The paper begins by discussing the related work on ridge regression and cross-validation in the presence of correlated data. The authors then present their analysis of the risk and generalization properties of ridge regression models when the samples are correlated.
They introduce a new method for accurately estimating the risk of ridge regression, which they call "generalized cross-validation" (GCV). This approach takes into account the correlation structure of the data, unlike traditional cross-validation techniques that assume independence.
The authors derive theoretical results to show the advantages of their GCV method over standard cross-validation. They demonstrate that GCV can provide more reliable risk estimates, leading to better model selection and tuning. This is particularly important when the data exhibits strong correlations, as is often the case in real-world applications.
The paper includes numerical experiments that validate the authors' theoretical findings and showcase the practical benefits of using GCV for ridge regression with correlated data.
Critical Analysis
The paper provides a thorough analysis of the challenges posed by correlated data in the context of ridge regression and cross-validation. The authors' proposed GCV method represents a significant contribution to the field, as it addresses a critical issue that can arise in many real-world machine learning applications.
One potential limitation of the research is that it focuses solely on ridge regression and does not consider other types of regularized regression models. While ridge regression is a widely used technique, it would be valuable to see if the authors' insights and methods can be extended to other regularization approaches, such as Lasso or elastic net regression.
Additionally, the paper does not explore the impact of the degree or structure of data correlation on the performance of the GCV method. It would be interesting to see how the method behaves under varying levels and patterns of correlation, as this could provide valuable guidance for practitioners on when to apply the GCV approach.
Overall, the paper makes a significant contribution to the understanding of ridge regression and cross-validation in the presence of correlated data. The authors' GCV method represents a valuable tool for improving the reliability of machine learning models in real-world scenarios where data independence cannot be assumed.
Conclusion
This paper addresses an important issue in machine learning – the impact of correlated data on the performance of ridge regression and cross-validation techniques. The authors propose a new method, generalized cross-validation (GCV), that takes into account the correlation structure of the data to provide more accurate risk estimates for ridge regression models.
The findings of this research have important implications for practitioners who work with real-world datasets that often exhibit correlation. By using the GCV approach, they can make more informed decisions about model selection and tuning, leading to improved predictive performance and better-informed decision-making.
The authors' work contributes to a deeper understanding of the challenges and considerations involved in building robust and reliable machine learning systems, particularly when dealing with complex data structures. Their insights and methods can serve as a foundation for further research in this area, ultimately advancing the field of machine learning and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Risk and cross validation in ridge regression with correlated samples
Alexander Atanasov, Jacob A. Zavatone-Veth, Cengiz Pehlevan
Recent years have seen substantial advances in our understanding of high-dimensional ridge regression, but existing theories assume that training examples are independent. By leveraging recent techniques from random matrix theory and free probability, we provide sharp asymptotics for the in- and out-of-sample risks of ridge regression when the data points have arbitrary correlations. We demonstrate that in this setting, the generalized cross validation estimator (GCV) fails to correctly predict the out-of-sample risk. However, in the case where the noise residuals have the same correlations as the data points, one can modify the GCV to yield an efficiently-computable unbiased estimator that concentrates in the high-dimensional limit, which we dub CorrGCV. We further extend our asymptotic analysis to the case where the test point has nontrivial correlations with the training set, a setting often encountered in time series forecasting. Assuming knowledge of the correlation structure of the time series, this again yields an extension of the GCV estimator, and sharply characterizes the degree to which such test points yield an overly optimistic prediction of long-time risk. We validate the predictions of our theory across a variety of high dimensional data.
Read more8/13/2024
0
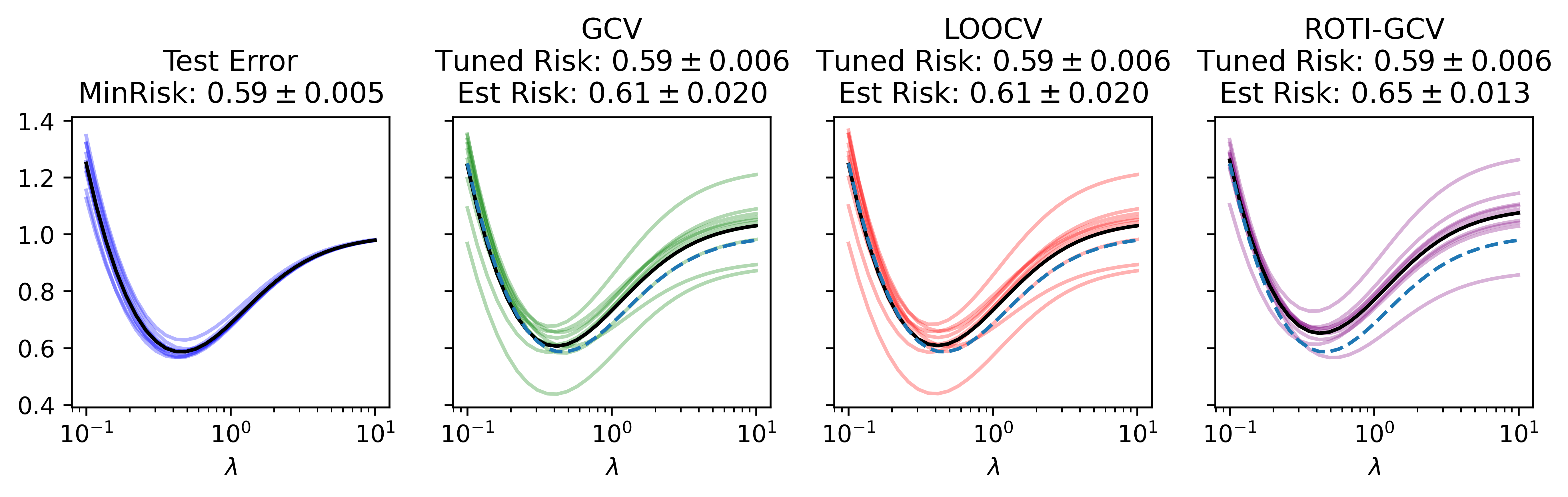
ROTI-GCV: Generalized Cross-Validation for right-ROTationally Invariant Data
Kevin Luo, Yufan Li, Pragya Sur
Two key tasks in high-dimensional regularized regression are tuning the regularization strength for good predictions and estimating the out-of-sample risk. It is known that the standard approach -- $k$-fold cross-validation -- is inconsistent in modern high-dimensional settings. While leave-one-out and generalized cross-validation remain consistent in some high-dimensional cases, they become inconsistent when samples are dependent or contain heavy-tailed covariates. To model structured sample dependence and heavy tails, we use right-rotationally invariant covariate distributions - a crucial concept from compressed sensing. In the common modern proportional asymptotics regime where the number of features and samples grow comparably, we introduce a new framework, ROTI-GCV, for reliably performing cross-validation. Along the way, we propose new estimators for the signal-to-noise ratio and noise variance under these challenging conditions. We conduct extensive experiments that demonstrate the power of our approach and its superiority over existing methods.
Read more6/18/2024
0
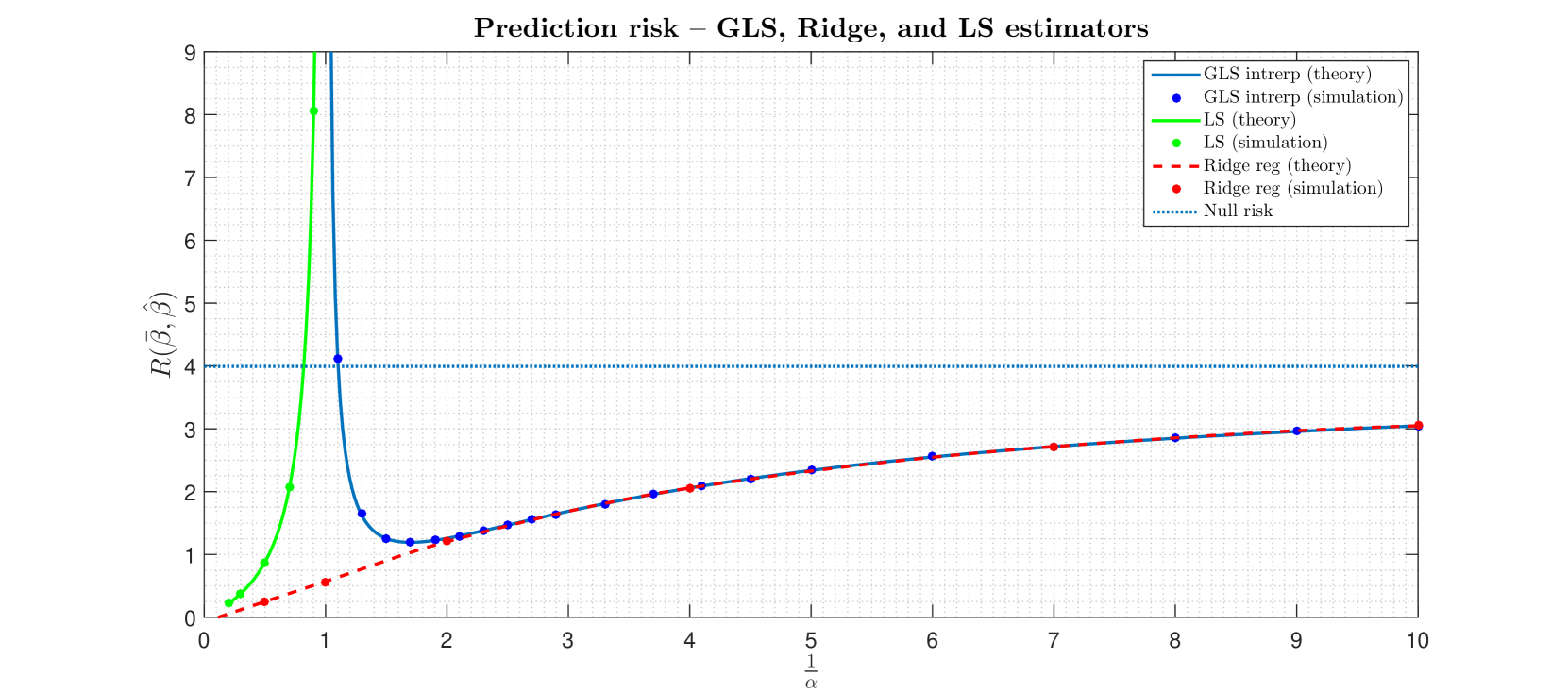
Precise analysis of ridge interpolators under heavy correlations -- a Random Duality Theory view
Mihailo Stojnic
We consider fully row/column-correlated linear regression models and study several classical estimators (including minimum norm interpolators (GLS), ordinary least squares (LS), and ridge regressors). We show that emph{Random Duality Theory} (RDT) can be utilized to obtain precise closed form characterizations of all estimators related optimizing quantities of interest, including the emph{prediction risk} (testing or generalization error). On a qualitative level out results recover the risk's well known non-monotonic (so-called double-descent) behavior as the number of features/sample size ratio increases. On a quantitative level, our closed form results show how the risk explicitly depends on all key model parameters, including the problem dimensions and covariance matrices. Moreover, a special case of our results, obtained when intra-sample (or time-series) correlations are not present, precisely match the corresponding ones obtained via spectral methods in [6,16,17,24].
Read more6/14/2024
0
Scaling and renormalization in high-dimensional regression
Alexander Atanasov, Jacob A. Zavatone-Veth, Cengiz Pehlevan
This paper presents a succinct derivation of the training and generalization performance of a variety of high-dimensional ridge regression models using the basic tools of random matrix theory and free probability. We provide an introduction and review of recent results on these topics, aimed at readers with backgrounds in physics and deep learning. Analytic formulas for the training and generalization errors are obtained in a few lines of algebra directly from the properties of the $S$-transform of free probability. This allows for a straightforward identification of the sources of power-law scaling in model performance. We compute the generalization error of a broad class of random feature models. We find that in all models, the $S$-transform corresponds to the train-test generalization gap, and yields an analogue of the generalized-cross-validation estimator. Using these techniques, we derive fine-grained bias-variance decompositions for a very general class of random feature models with structured covariates. These novel results allow us to discover a scaling regime for random feature models where the variance due to the features limits performance in the overparameterized setting. We also demonstrate how anisotropic weight structure in random feature models can limit performance and lead to nontrivial exponents for finite-width corrections in the overparameterized setting. Our results extend and provide a unifying perspective on earlier models of neural scaling laws.
Read more6/27/2024