RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning

2

Sign in to get full access
Overview
- RLEF is a method that uses reinforcement learning to ground large language models (LLMs) in execution feedback when generating code.
- It aims to improve the performance of LLMs on code-related tasks by training them to consider the actual execution and behavior of the code they generate.
- The key idea is to provide the LLM with feedback on the execution of the code it generates, and then use reinforcement learning to fine-tune the model to generate better code over time.
Plain English Explanation
The paper proposes a method called RLEF (Reinforcement Learning with Execution Feedback) to improve the performance of large language models (LLMs) on code-related tasks. LLMs are powerful models that can generate human-like text, but they don't always produce high-quality code.
The key insight behind RLEF is that by providing the LLM with feedback on the actual execution and behavior of the code it generates, the model can learn to generate better code over time. The process works like this:
- The LLM generates some code based on a given task or prompt.
- The code is then executed, and the LLM receives feedback on how well the code performed. This feedback could be things like whether the code ran without errors, how efficient it was, or whether it produced the desired output.
- The LLM then uses this feedback to fine-tune its parameters using reinforcement learning. This means the model adjusts its internal parameters to generate code that performs better based on the feedback it receives.
Over many iterations of this process, the LLM learns to generate code that is more reliable, efficient, and effective, ultimately improving its performance on a variety of code-related tasks.
Technical Explanation
The RLEF method consists of the following key components:
- Code Generation: The LLM is given a task or prompt and generates some code as output.
- Code Execution: The generated code is executed, and the execution feedback is captured. This feedback could include metrics like runtime, memory usage, or whether the code ran successfully without errors.
- Reinforcement Learning: The LLM is then fine-tuned using reinforcement learning, where the execution feedback is used as the reward signal. This encourages the model to generate code that performs better according to the feedback.
The authors tested RLEF on several code-related tasks, such as generating SQL queries, JavaScript functions, and Python scripts. They found that RLEF significantly improved the performance of the LLM compared to models trained without execution feedback.
The key insight is that by grounding the LLM's code generation in the actual execution of the code, the model can learn to generate more reliable and effective code. This is in contrast to traditional approaches that only train the LLM on the textual representation of code, without considering its actual behavior.
Critical Analysis
The RLEF method appears to be a promising approach for improving the code generation capabilities of LLMs. However, the paper does not address some potential limitations and areas for further research:
- Scalability: The paper focuses on relatively small-scale tasks, such as generating short SQL queries or JavaScript functions. It's unclear how well RLEF would scale to more complex, real-world code generation problems, which may require much longer code snippets and more sophisticated execution feedback.
- Interpretability: The reinforcement learning approach used in RLEF is inherently opaque, making it difficult to understand why the LLM is generating certain code snippets. More work may be needed to improve the interpretability of the model's decision-making process.
- Robustness: The paper does not explore the robustness of RLEF to changes in the execution environment or the types of tasks the LLM is asked to perform. Further research is needed to understand how well the method generalizes to a wider range of code generation scenarios.
Despite these potential limitations, the RLEF method represents an important step towards grounding LLMs in the actual execution and behavior of the code they generate, which could lead to significant improvements in their code-related capabilities.
Conclusion
The RLEF method proposed in this paper is a novel approach to improving the code generation capabilities of large language models. By providing the model with feedback on the execution of the code it generates and fine-tuning it using reinforcement learning, RLEF helps the LLM learn to generate more reliable, efficient, and effective code.
While the paper focuses on relatively small-scale tasks, the underlying principles of RLEF could have broader implications for the development of more powerful and versatile code generation systems. As LLMs continue to play an increasingly important role in software development and other code-related domains, methods like RLEF may become increasingly important for ensuring these models can generate high-quality, dependable code.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
New!RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Taco Cohen, Gabriel Synnaeve
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
Read more10/4/2024
0
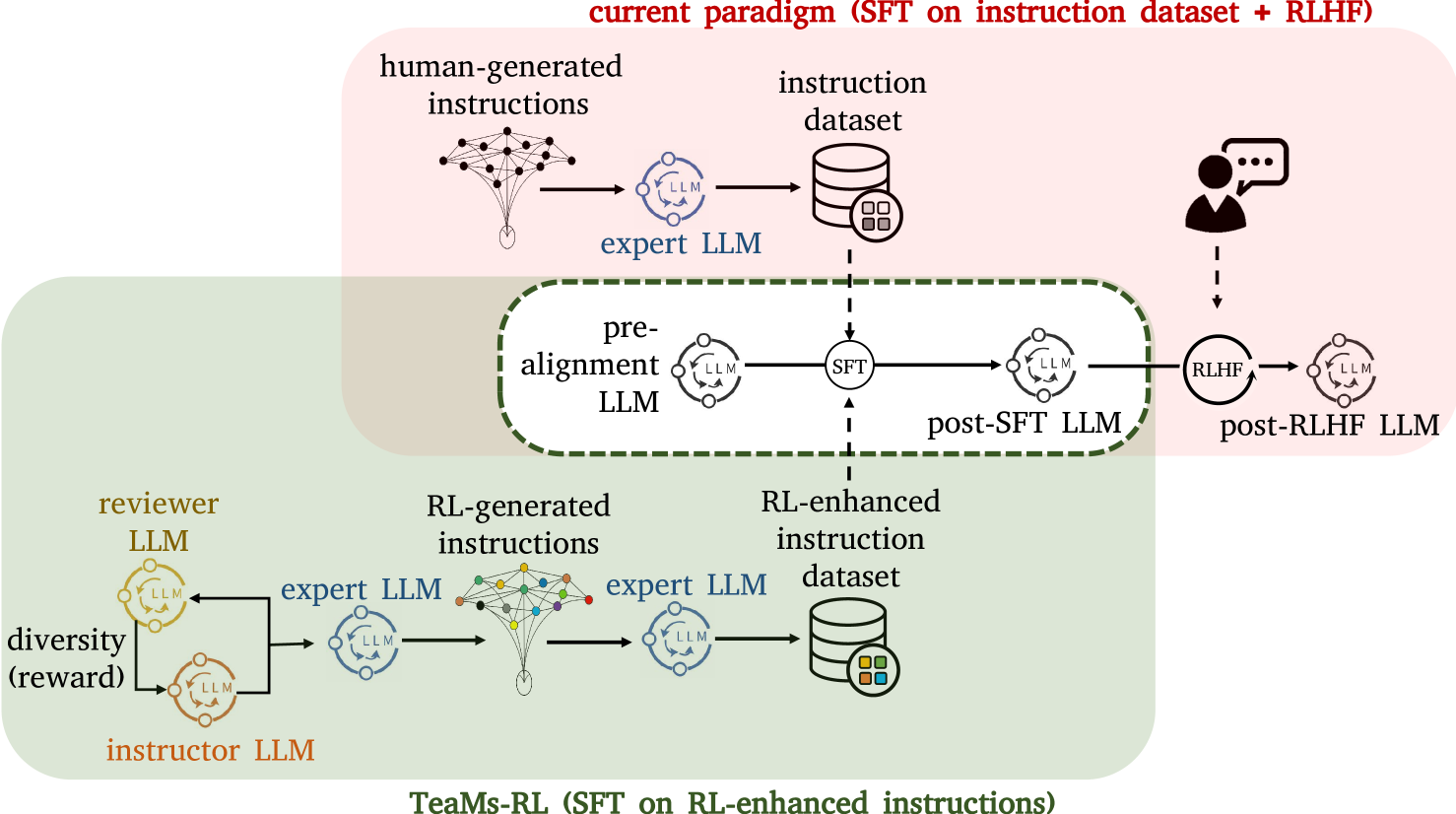
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of the strong baseline's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection. Code is available at the link: https://github.com/SafeRL-Lab/TeaMs-RL
Read more8/20/2024
💬
0
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
Read more4/23/2024
🛠️
0
Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration
Yang Zhang, Shixin Yang, Chenjia Bai, Fei Wu, Xiu Li, Zhen Wang, Xuelong Li
Grounding the reasoning ability of large language models (LLMs) for embodied tasks is challenging due to the complexity of the physical world. Especially, LLM planning for multi-agent collaboration requires communication of agents or credit assignment as the feedback to re-adjust the proposed plans and achieve effective coordination. However, existing methods that overly rely on physical verification or self-reflection suffer from excessive and inefficient querying of LLMs. In this paper, we propose a novel framework for multi-agent collaboration that introduces Reinforced Advantage feedback (ReAd) for efficient self-refinement of plans. Specifically, we perform critic regression to learn a sequential advantage function from LLM-planned data, and then treat the LLM planner as an optimizer to generate actions that maximize the advantage function. It endows the LLM with the foresight to discern whether the action contributes to accomplishing the final task. We provide theoretical analysis by extending advantage-weighted regression in reinforcement learning to multi-agent systems. Experiments on Overcooked-AI and a difficult variant of RoCoBench show that ReAd surpasses baselines in success rate, and also significantly decreases the interaction steps of agents and query rounds of LLMs, demonstrating its high efficiency for grounding LLMs. More results are given at https://read-llm.github.io/.
Read more5/28/2024