TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning

0
Sign in to get full access
Overview
- This paper introduces a novel approach called TeaMs-RL, which teaches large language models (LLMs) to teach themselves better instructions using reinforcement learning.
- The goal is to enable LLMs to autonomously improve their own instruction-following capabilities, leading to more robust and capable AI systems.
- The authors explore the use of reinforcement learning to train an LLM to generate higher-quality task instructions, which are then used to guide the training of the main LLM.
Plain English Explanation
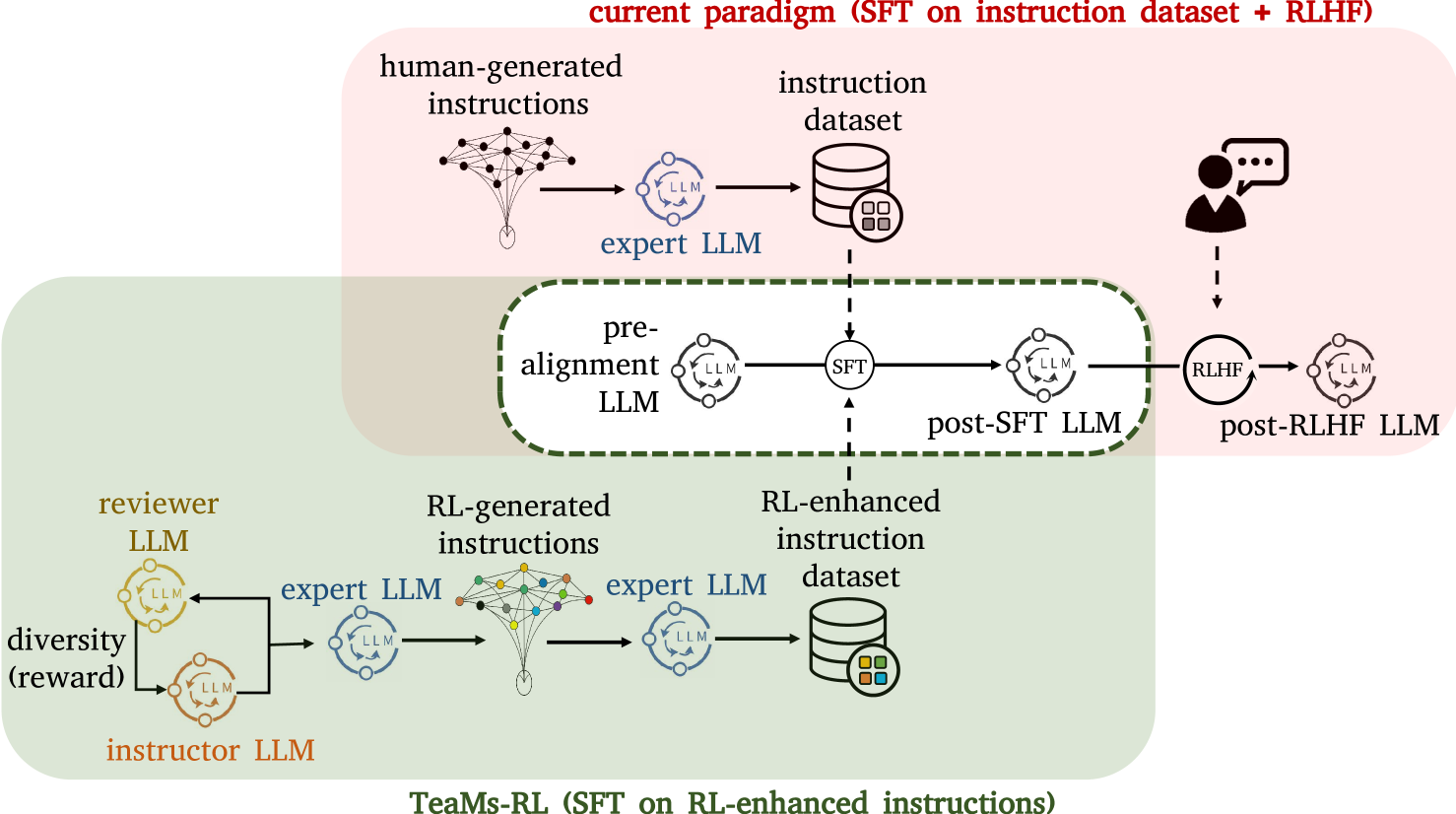
The paper presents a technique called TeaMs-RL, which aims to help large language models (LLMs) become better at following and generating instructions. The key idea is to train a separate model, using reinforcement learning, to create high-quality task instructions. These instructions are then used to guide the training of the main LLM, allowing it to learn how to follow instructions more effectively.
The motivation behind this approach is to enable LLMs to autonomously improve their own abilities, rather than relying solely on human-provided instructions. By allowing the models to teach themselves, the researchers hope to develop more robust and capable AI systems that can handle a wider range of tasks and instructions.
The paper on reinforcement learning for problem-solving in large language models and the analysis of reinforcement learning from human feedback (RLHF) provide relevant context for understanding the approach taken in this research.
Technical Explanation
The TeaMs-RL system consists of two main components: a
The paper on using LLMs as policy teachers provides a relevant framework for this approach, where the instruction generator acts as a "policy teacher" to the task-solving LLM.
During training, the instruction generator receives a task description as input and generates a set of instructions. The task-solving LLM then attempts to execute the task based on these instructions. The performance of the task-solving LLM is used as a reward signal to fine-tune the instruction generator, encouraging it to generate more effective instructions over time.
The paper on reflective reinforcement learning for LLMs discusses similar approaches to enabling LLMs to improve their own capabilities through self-reflection and reinforcement.
Critical Analysis
While the TeaMs-RL approach is a promising direction for improving the instruction-following capabilities of LLMs, the paper does not provide a thorough evaluation of its performance compared to other methods. Additionally, the authors do not address potential issues with the stability and scalability of the reinforcement learning process, which can be challenging to deploy in real-world settings.
Furthermore, the paper on generalizable agents in text-based educational environments highlights the importance of developing LLMs that can generalize their instruction-following skills across a wide range of tasks and environments. The TeaMs-RL approach may need to be extended to address this challenge.
Conclusion
The TeaMs-RL method represents an interesting step towards enabling LLMs to autonomously improve their instruction-following capabilities through reinforcement learning. By training a separate model to generate high-quality task instructions, the authors aim to develop more robust and capable AI systems that can adapt to a variety of tasks and environments.
While the paper provides a proof-of-concept for this approach, further research is needed to address its limitations and explore its potential for real-world applications. Incorporating insights from related work on reinforcement learning and self-improvement in LLMs could help strengthen the TeaMs-RL framework and unlock new possibilities for advancing the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of the strong baseline's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection. Code is available at the link: https://github.com/SafeRL-Lab/TeaMs-RL
Read more8/20/2024
💬
0
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
Read more4/23/2024
0
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
Read more4/30/2024

0
LLMs Could Autonomously Learn Without External Supervision
Ke Ji, Junying Chen, Anningzhe Gao, Wenya Xie, Xiang Wan, Benyou Wang
In the quest for super-human performance, Large Language Models (LLMs) have traditionally been tethered to human-annotated datasets and predefined training objectives-a process that is both labor-intensive and inherently limited. This paper presents a transformative approach: Autonomous Learning for LLMs, a self-sufficient learning paradigm that frees models from the constraints of human supervision. This method endows LLMs with the ability to self-educate through direct interaction with text, akin to a human reading and comprehending literature. Our approach eliminates the reliance on annotated data, fostering an Autonomous Learning environment where the model independently identifies and reinforces its knowledge gaps. Empirical results from our comprehensive experiments, which utilized a diverse array of learning materials and were evaluated against standard public quizzes, reveal that Autonomous Learning outstrips the performance of both Pre-training and Supervised Fine-Tuning (SFT), as well as retrieval-augmented methods. These findings underscore the potential of Autonomous Learning to not only enhance the efficiency and effectiveness of LLM training but also to pave the way for the development of more advanced, self-reliant AI systems.
Read more6/10/2024