Robust Lagrangian and Adversarial Policy Gradient for Robust Constrained Markov Decision Processes
2308.11267
0
0
➖
Abstract
The robust constrained Markov decision process (RCMDP) is a recent task-modelling framework for reinforcement learning that incorporates behavioural constraints and that provides robustness to errors in the transition dynamics model through the use of an uncertainty set. Simulating RCMDPs requires computing the worst-case dynamics based on value estimates for each state, an approach which has previously been used in the Robust Constrained Policy Gradient (RCPG). Highlighting potential downsides of RCPG such as not robustifying the full constrained objective and the lack of incremental learning, this paper introduces two algorithms, called RCPG with Robust Lagrangian and Adversarial RCPG. RCPG with Robust Lagrangian modifies RCPG by taking the worst-case dynamics based on the Lagrangian rather than either the value or the constraint. Adversarial RCPG also formulates the worst-case dynamics based on the Lagrangian but learns this directly and incrementally as an adversarial policy through gradient descent rather than indirectly and abruptly through constrained optimisation on a sorted value list. A theoretical analysis first derives the Lagrangian policy gradient for the policy optimisation of both proposed algorithms and then the adversarial policy gradient to learn the adversary for Adversarial RCPG. Empirical experiments injecting perturbations in inventory management and safe navigation tasks demonstrate the competitive performance of both algorithms compared to traditional RCPG variants as well as non-robust and non-constrained ablations. In particular, Adversarial RCPG ranks among the top two performing algorithms on all tests.
Create account to get full access
Overview
- Introduces two new algorithms for reinforcement learning with behavioural constraints and robustness to model errors
- Builds on the Robust Constrained Policy Gradient (RCPG) framework
- Aims to address potential downsides of RCPG like not robustifying the full constrained objective and lack of incremental learning
Plain English Explanation
The paper introduces two new algorithms for reinforcement learning that incorporate behavioural constraints and are robust to errors in the model of the task environment.
These algorithms build on a previous approach called Robust Constrained Policy Gradient (RCPG), which computed the worst-case dynamics based on value estimates for each state. However, the paper argues that RCPG has some potential downsides, such as not fully robustifying the constrained objective and a lack of incremental learning.
The first new algorithm, called RCPG with Robust Lagrangian, modifies RCPG by basing the worst-case dynamics on the Lagrangian (a mathematical function used to optimize constrained problems) rather than the value or constraint. The second algorithm, Adversarial RCPG, also uses the Lagrangian to formulate the worst-case dynamics, but learns this directly and incrementally through an adversarial policy, rather than indirectly through constrained optimization.
The paper provides a theoretical analysis of these new algorithms and demonstrates their performance on simulated tasks like inventory management and safe navigation, where they outperform traditional RCPG variants as well as non-robust and non-constrained approaches.
Technical Explanation
The paper introduces two new algorithms for Robust Constrained Markov Decision Processes (RCMDPs), a task-modelling framework for reinforcement learning that incorporates behavioural constraints and robustness to errors in the transition dynamics model.
The first algorithm, RCPG with Robust Lagrangian, modifies the previous Robust Constrained Policy Gradient (RCPG) approach by basing the computation of worst-case dynamics on the Lagrangian of the constrained optimization problem, rather than on the value estimates or constraint function. This aims to more fully robustify the constrained objective.
The second algorithm, Adversarial RCPG, also formulates the worst-case dynamics based on the Lagrangian, but learns this adversarial policy directly and incrementally through gradient descent, rather than indirectly and abruptly through constrained optimization on a sorted value list (as in RCPG). This addresses the lack of incremental learning in the original RCPG.
The paper provides a theoretical analysis, deriving the Lagrangian policy gradient for the policy optimization in both algorithms, as well as the adversarial policy gradient for the adversary in Adversarial RCPG.
Empirical experiments on simulated inventory management and safe navigation tasks demonstrate the competitive performance of the two new algorithms compared to traditional RCPG variants, as well as non-robust and non-constrained baselines. Adversarial RCPG, in particular, ranks among the top two performing algorithms across all the tests.
Critical Analysis
The paper addresses some key limitations of the previous RCPG approach, such as not fully robustifying the constrained objective and the lack of incremental learning. The two new algorithms proposed, RCPG with Robust Lagrangian and Adversarial RCPG, aim to address these issues.
However, the paper does not discuss the potential computational complexity or scalability challenges of the new algorithms, especially the Adversarial RCPG approach, which involves learning an adversarial policy. The theoretical analysis provides important insights, but more empirical evaluation on larger-scale or more complex tasks would be helpful to understand the practical limitations and trade-offs of these methods.
Additionally, the paper does not explore the potential negative societal impacts of these robust and constrained reinforcement learning algorithms, such as unintended consequences or biases that could arise from the way the constraints and robustness are defined and optimized. Further research is needed to understand the broader implications of these techniques.
Conclusion
This paper introduces two new algorithms, RCPG with Robust Lagrangian and Adversarial RCPG, that build upon the Robust Constrained Markov Decision Process framework to enhance reinforcement learning with behavioural constraints and robustness to model errors.
The key innovations are the use of the Lagrangian function to compute worst-case dynamics, and the direct, incremental learning of the adversarial policy in Adversarial RCPG. These approaches aim to address limitations of the previous RCPG method, such as not fully robustifying the constrained objective and the lack of incremental learning.
The empirical results demonstrate the competitive performance of these new algorithms, particularly Adversarial RCPG, on simulated tasks with perturbed environments. However, further research is needed to understand the scalability, computational complexity, and broader societal implications of these robust and constrained reinforcement learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
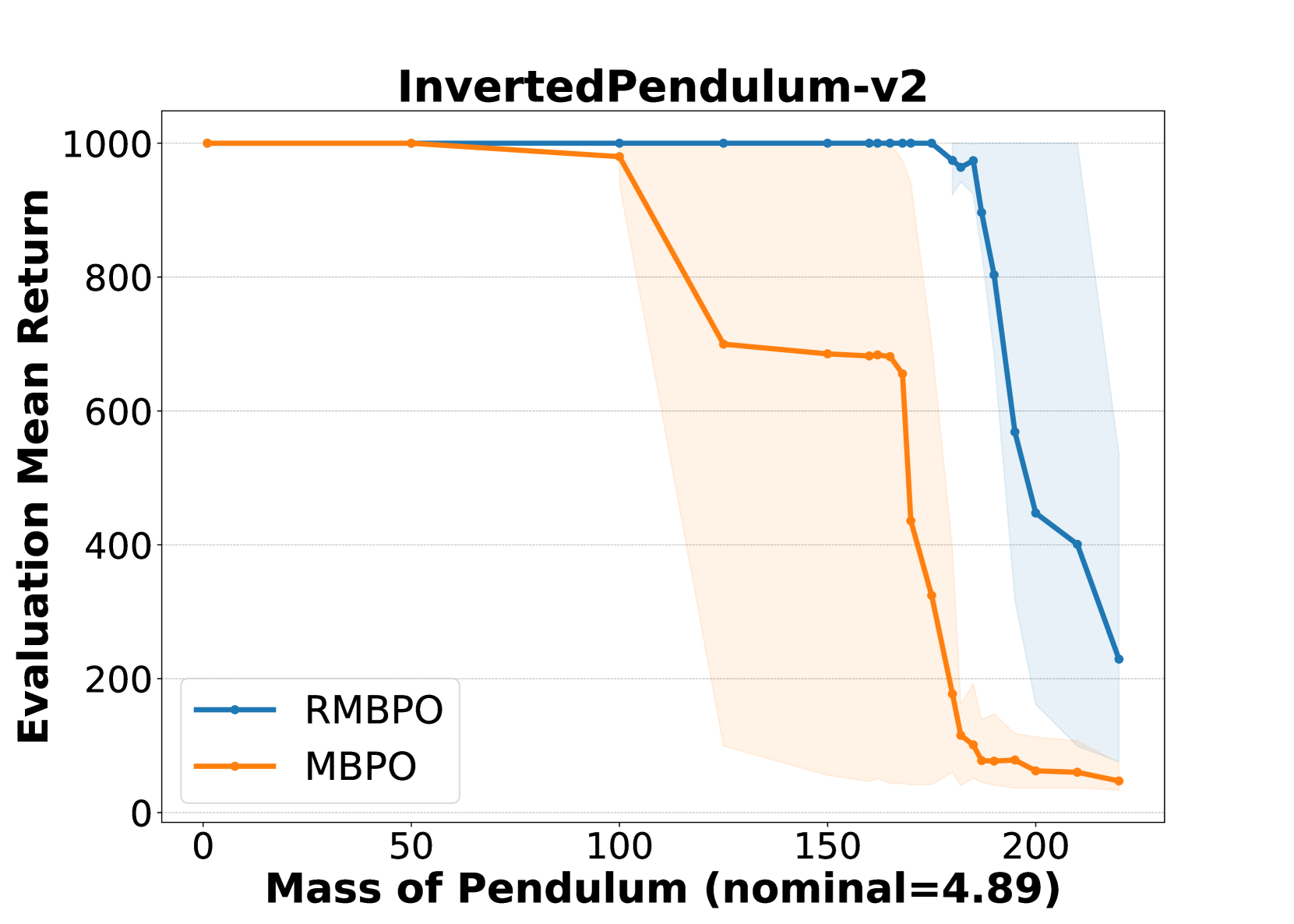
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
7/2/2024
💬
A safe exploration approach to constrained Markov decision processes
Tingting Ni, Maryam Kamgarpour
0
0
We consider discounted infinite horizon constrained Markov decision processes (CMDPs) where the goal is to find an optimal policy that maximizes the expected cumulative reward subject to expected cumulative constraints. Motivated by the application of CMDPs in online learning of safety-critical systems, we focus on developing a model-free and simulator-free algorithm that ensures constraint satisfaction during learning. To this end, we develop an interior point approach based on the log barrier function of the CMDP. Under the commonly assumed conditions of Fisher non-degeneracy and bounded transfer error of the policy parameterization, we establish the theoretical properties of the algorithm. In particular, in contrast to existing CMDP approaches that ensure policy feasibility only upon convergence, our algorithm guarantees the feasibility of the policies during the learning process and converges to the $varepsilon$-optimal policy with a sample complexity of $tilde{mathcal{O}}(varepsilon^{-6})$. In comparison to the state-of-the-art policy gradient-based algorithm, C-NPG-PDA, our algorithm requires an additional $mathcal{O}(varepsilon^{-2})$ samples to ensure policy feasibility during learning with the same Fisher non-degenerate parameterization.
5/24/2024
Robust Risk-Sensitive Reinforcement Learning with Conditional Value-at-Risk
Xinyi Ni, Lifeng Lai
0
0
Robust Markov Decision Processes (RMDPs) have received significant research interest, offering an alternative to standard Markov Decision Processes (MDPs) that often assume fixed transition probabilities. RMDPs address this by optimizing for the worst-case scenarios within ambiguity sets. While earlier studies on RMDPs have largely centered on risk-neutral reinforcement learning (RL), with the goal of minimizing expected total discounted costs, in this paper, we analyze the robustness of CVaR-based risk-sensitive RL under RMDP. Firstly, we consider predetermined ambiguity sets. Based on the coherency of CVaR, we establish a connection between robustness and risk sensitivity, thus, techniques in risk-sensitive RL can be adopted to solve the proposed problem. Furthermore, motivated by the existence of decision-dependent uncertainty in real-world problems, we study problems with state-action-dependent ambiguity sets. To solve this, we define a new risk measure named NCVaR and build the equivalence of NCVaR optimization and robust CVaR optimization. We further propose value iteration algorithms and validate our approach in simulation experiments.
5/6/2024
↗️
Learning Constrained Markov Decision Processes With Non-stationary Rewards and Constraints
Francesco Emanuele Stradi, Anna Lunghi, Matteo Castiglioni, Alberto Marchesi, Nicola Gatti
0
0
In constrained Markov decision processes (CMDPs) with adversarial rewards and constraints, a well-known impossibility result prevents any algorithm from attaining both sublinear regret and sublinear constraint violation, when competing against a best-in-hindsight policy that satisfies constraints on average. In this paper, we show that this negative result can be eased in CMDPs with non-stationary rewards and constraints, by providing algorithms whose performances smoothly degrade as non-stationarity increases. Specifically, we propose algorithms attaining $tilde{mathcal{O}} (sqrt{T} + C)$ regret and positive constraint violation under bandit feedback, where $C$ is a corruption value measuring the environment non-stationarity. This can be $Theta(T)$ in the worst case, coherently with the impossibility result for adversarial CMDPs. First, we design an algorithm with the desired guarantees when $C$ is known. Then, in the case $C$ is unknown, we show how to obtain the same results by embedding such an algorithm in a general meta-procedure. This is of independent interest, as it can be applied to any non-stationary constrained online learning setting.
5/24/2024