Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models

0
Sign in to get full access
Overview
- This paper presents a method for predicting missing modalities in unpaired multimodal learning tasks.
- The proposed approach uses a joint embedding of unimodal models to capture the relationships between different modalities, enabling the prediction of missing modalities.
- The method is designed to work in the absence of paired multimodal data, which is often a challenge in real-world applications.
Plain English Explanation
In many machine learning tasks, data can come from multiple sources or "modalities," such as text, images, audio, and video. When training models to work with this kind of multimodal data, it's often the case that some of the modalities may be missing or unavailable during the training process. This paper introduces a new method to deal with this problem.
The key idea is to use the relationships between the different modalities, even when they are not paired together in the training data. The researchers build individual models for each modality, and then find a way to connect these models to each other. This allows the system to "predict" the missing modality, based on the information available from the other modalities.
For example, imagine you have a dataset with images and text, but some of the images are missing their corresponding text descriptions. This approach could be used to generate plausible text descriptions for those missing images, by leveraging the learned relationships between the image and text modalities.
The advantage of this method is that it doesn't require the training data to have all modalities paired together, which is often a practical challenge. Instead, it can work with "unpaired" multimodal data, making it more flexible and applicable to real-world scenarios where data may be incomplete or fragmented.
Technical Explanation
The paper introduces a novel method for "missing modality prediction" in the context of unpaired multimodal learning. The key idea is to leverage the joint embedding of unimodal models to capture the relationships between different modalities, enabling the prediction of missing modalities.
The method consists of three main steps:
- Unimodal Encoding: The researchers train individual models to encode each modality (e.g., image, text, audio) into a fixed-size representation or "embedding."
- Joint Embedding: These unimodal embeddings are then projected into a shared latent space, where the relationships between modalities can be learned.
- Missing Modality Prediction: Given an input with one or more missing modalities, the model can use the joint embedding to predict the missing information, based on the available modalities.
The paper demonstrates the effectiveness of this approach on several multimodal benchmarks, showing that it can outperform alternative methods for handling missing modalities, especially in the case of unpaired multimodal data. The authors also explore extensions to this work, such as using the method for multimodal image synthesis with missing modalities.
Critical Analysis
The paper presents a well-designed and technically sound approach for addressing the challenge of missing modalities in multimodal learning. The joint embedding strategy is a clever way to capture the relationships between modalities, even when they are not paired together in the training data.
One potential limitation is that the method relies on the availability of unimodal models that can provide meaningful embeddings for each modality. In scenarios where such models are not readily available, the performance of the approach may be affected.
Additionally, the paper does not explore the impact of the quality and characteristics of the unimodal models on the overall performance of the missing modality prediction. It would be interesting to see how the method behaves when using different types of unimodal models, or when the available modalities have varying levels of information content.
Further research could also investigate the application of this technique to more complex multimodal tasks, such as sentiment analysis with missing modalities, or its use in real-world scenarios involving multimodal data from egocentric video sources.
Conclusion
This paper presents a novel approach for predicting missing modalities in unpaired multimodal learning tasks. By leveraging the joint embedding of unimodal models, the method can capture the relationships between different modalities and use this information to estimate the missing data.
The key strength of this approach is its ability to work with incomplete or fragmented multimodal data, which is a common challenge in real-world applications. The results demonstrate the effectiveness of the method, and the potential for further development and application in diverse multimodal learning domains.
Overall, this paper contributes a valuable technique to the field of multimodal machine learning, offering a solution to the ubiquitous problem of missing data in such settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
Donggeun Kim, Taesup Kim
Multimodal learning typically relies on the assumption that all modalities are fully available during both the training and inference phases. However, in real-world scenarios, consistently acquiring complete multimodal data presents significant challenges due to various factors. This often leads to the issue of missing modalities, where data for certain modalities are absent, posing considerable obstacles not only for the availability of multimodal pretrained models but also for their fine-tuning and the preservation of robustness in downstream tasks. To address these challenges, we propose a novel framework integrating parameter-efficient fine-tuning of unimodal pretrained models with a self-supervised joint-embedding learning method. This framework enables the model to predict the embedding of a missing modality in the representation space during inference. Our method effectively predicts the missing embedding through prompt tuning, leveraging information from available modalities. We evaluate our approach on several multimodal benchmark datasets and demonstrate its effectiveness and robustness across various scenarios of missing modalities.
Read more7/18/2024
0
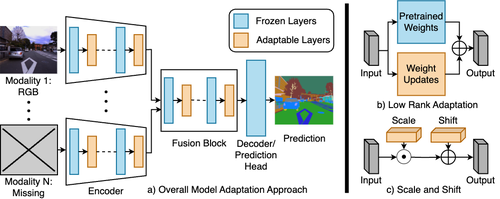
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation
Md Kaykobad Reza, Ashley Prater-Bennette, M. Salman Asif
Multimodal learning seeks to utilize data from multiple sources to improve the overall performance of downstream tasks. It is desirable for redundancies in the data to make multimodal systems robust to missing or corrupted observations in some correlated modalities. However, we observe that the performance of several existing multimodal networks significantly deteriorates if one or multiple modalities are absent at test time. To enable robustness to missing modalities, we propose a simple and parameter-efficient adaptation procedure for pretrained multimodal networks. In particular, we exploit modulation of intermediate features to compensate for the missing modalities. We demonstrate that such adaptation can partially bridge performance drop due to missing modalities and outperform independent, dedicated networks trained for the available modality combinations in some cases. The proposed adaptation requires extremely small number of parameters (e.g., fewer than 1% of the total parameters) and applicable to a wide range of modality combinations and tasks. We conduct a series of experiments to highlight the missing modality robustness of our proposed method on five different multimodal tasks across seven datasets. Our proposed method demonstrates versatility across various tasks and datasets, and outperforms existing methods for robust multimodal learning with missing modalities.
Read more7/30/2024
0
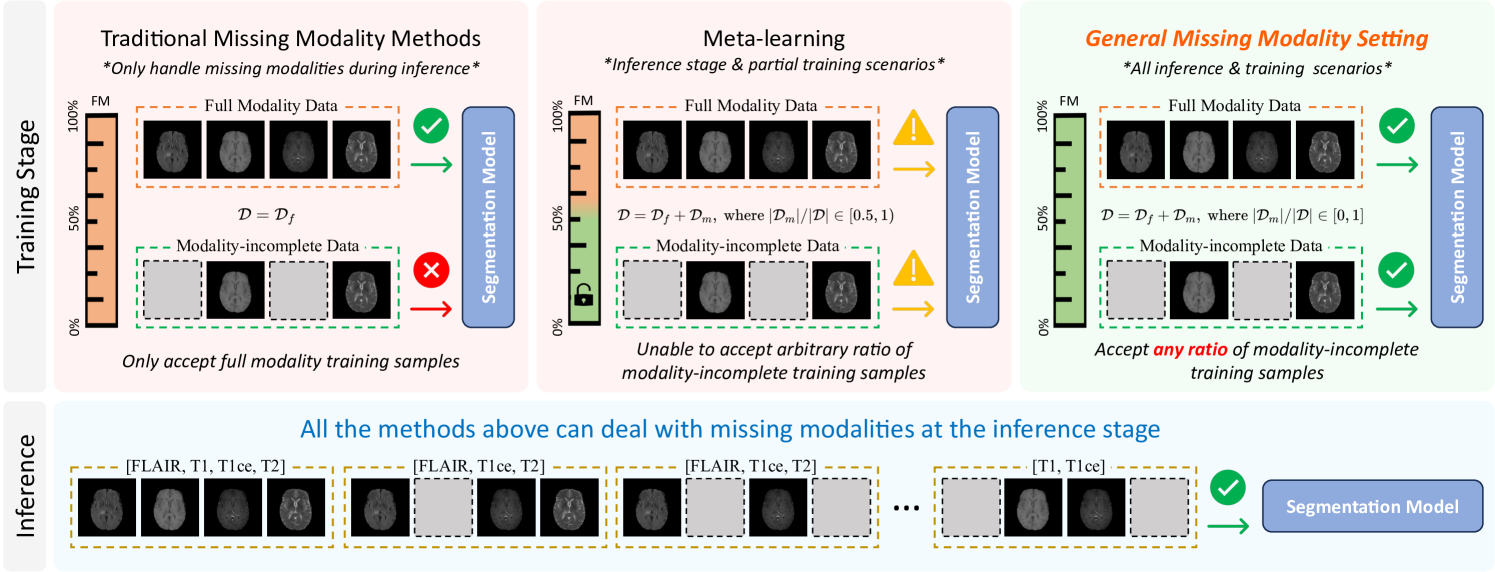
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Read more6/5/2024

0
Multimodal Prompt Learning with Missing Modalities for Sentiment Analysis and Emotion Recognition
Zirun Guo, Tao Jin, Zhou Zhao
The development of multimodal models has significantly advanced multimodal sentiment analysis and emotion recognition. However, in real-world applications, the presence of various missing modality cases often leads to a degradation in the model's performance. In this work, we propose a novel multimodal Transformer framework using prompt learning to address the issue of missing modalities. Our method introduces three types of prompts: generative prompts, missing-signal prompts, and missing-type prompts. These prompts enable the generation of missing modality features and facilitate the learning of intra- and inter-modality information. Through prompt learning, we achieve a substantial reduction in the number of trainable parameters. Our proposed method outperforms other methods significantly across all evaluation metrics. Extensive experiments and ablation studies are conducted to demonstrate the effectiveness and robustness of our method, showcasing its ability to effectively handle missing modalities.
Read more7/9/2024