Robust performance metrics for imbalanced classification problems
2404.07661
0
0
🚀
Abstract
We show that established performance metrics in binary classification, such as the F-score, the Jaccard similarity coefficient or Matthews' correlation coefficient (MCC), are not robust to class imbalance in the sense that if the proportion of the minority class tends to $0$, the true positive rate (TPR) of the Bayes classifier under these metrics tends to $0$ as well. Thus, in imbalanced classification problems, these metrics favour classifiers which ignore the minority class. To alleviate this issue we introduce robust modifications of the F-score and the MCC for which, even in strongly imbalanced settings, the TPR is bounded away from $0$. We numerically illustrate the behaviour of the various performance metrics in simulations as well as on a credit default data set. We also discuss connections to the ROC and precision-recall curves and give recommendations on how to combine their usage with performance metrics.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Established performance metrics like F-score, Jaccard similarity, and Matthews' correlation coefficient (MCC) are not robust to class imbalance
- These metrics favor classifiers that ignore the minority class, even if the Bayes classifier has a high true positive rate (TPR)
- Researchers introduce robust modifications of the F-score and MCC that maintain a high TPR even in strongly imbalanced settings
Plain English Explanation
When working with binary classification problems, there are standard ways to measure how well a model performs. These include the F-score, Jaccard similarity, and Matthews' correlation coefficient (MCC).
The problem: The researchers found that these common performance metrics are not reliable when the classes are severely imbalanced - that is, when one class is much rarer than the other. In these cases, the metrics will favor classifiers that simply ignore the minority class, even if a more sophisticated "Bayes classifier" could actually identify the minority class with high accuracy.
The solution: To address this issue, the researchers developed new versions of the F-score and MCC that are more robust to class imbalance. Even when one class is very rare, these modified metrics will still reward classifiers that can accurately identify the minority class.
Technical Explanation
The researchers show mathematically that as the proportion of the minority class approaches 0, the true positive rate (TPR) of the Bayes classifier under standard performance metrics like F-score and MCC also approaches 0. This means these metrics will favor simple classifiers that ignore the minority class entirely, rather than more complex models that can accurately identify the rare cases.
To fix this, the researchers introduce new "robust" versions of the F-score and MCC. These modified metrics ensure the TPR remains bounded away from 0, even in highly imbalanced settings. The researchers validate these improvements through numerical simulations as well as experiments on a real-world credit default dataset.
They also discuss connections between these performance metrics and other tools like ROC and precision-recall curves. The paper provides guidance on how to effectively combine these different evaluation techniques to get a more complete picture of model performance.
Critical Analysis
The researchers acknowledge that their robust metrics still have limitations - for example, they may not fully capture the "difficulty" of a classification task in the way that measures like classification difficulty can. There may also be other factors beyond just class imbalance that impact the reliability of standard performance metrics.
Additionally, the paper does not explore how these issues around class imbalance may play out in more complex, multi-class classification scenarios. Further research would be needed to understand the implications in those settings.
Overall, though, this work highlights an important and under-appreciated problem with common model evaluation techniques. The new robust metrics proposed provide a useful tool for researchers and practitioners working on imbalanced classification problems.
Conclusion
This paper demonstrates that standard performance metrics like F-score and MCC can be misleading when dealing with highly imbalanced datasets. The researchers introduce improved versions of these metrics that remain reliable even when one class is extremely rare. These robust metrics can help ensure that machine learning models are properly evaluated and optimized, especially in real-world applications where class imbalance is a common challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multiclass ROC
Liang Wang, Luis Carvalho
0
0
Model evaluation is of crucial importance in modern statistics application. The construction of ROC and calculation of AUC have been widely used for binary classification evaluation. Recent research generalizing the ROC/AUC analysis to multi-class classification has problems in at least one of the four areas: 1. failure to provide sensible plots 2. being sensitive to imbalanced data 3. unable to specify mis-classification cost and 4. unable to provide evaluation uncertainty quantification. Borrowing from a binomial matrix factorization model, we provide an evaluation metric summarizing the pair-wise multi-class True Positive Rate (TPR) and False Positive Rate (FPR) with one-dimensional vector representation. Visualization on the representation vector measures the relative speed of increment between TPR and FPR across all the classes pairs, which in turns provides a ROC plot for the multi-class counterpart. An integration over those factorized vector provides a binary AUC-equivalent summary on the classifier performance. Mis-clasification weights specification and bootstrapped confidence interval are also enabled to accommodate a variety of of evaluation criteria. To support our findings, we conducted extensive simulation studies and compared our method to the pair-wise averaged AUC statistics on benchmark datasets.
4/23/2024
🎲
Sharp error bounds for imbalanced classification: how many examples in the minority class?
Anass Aghbalou, Franc{c}ois Portier, Anne Sabourin
0
0
When dealing with imbalanced classification data, reweighting the loss function is a standard procedure allowing to equilibrate between the true positive and true negative rates within the risk measure. Despite significant theoretical work in this area, existing results do not adequately address a main challenge within the imbalanced classification framework, which is the negligible size of one class in relation to the full sample size and the need to rescale the risk function by a probability tending to zero. To address this gap, we present two novel contributions in the setting where the rare class probability approaches zero: (1) a non asymptotic fast rate probability bound for constrained balanced empirical risk minimization, and (2) a consistent upper bound for balanced nearest neighbors estimates. Our findings provide a clearer understanding of the benefits of class-weighting in realistic settings, opening new avenues for further research in this field.
4/17/2024
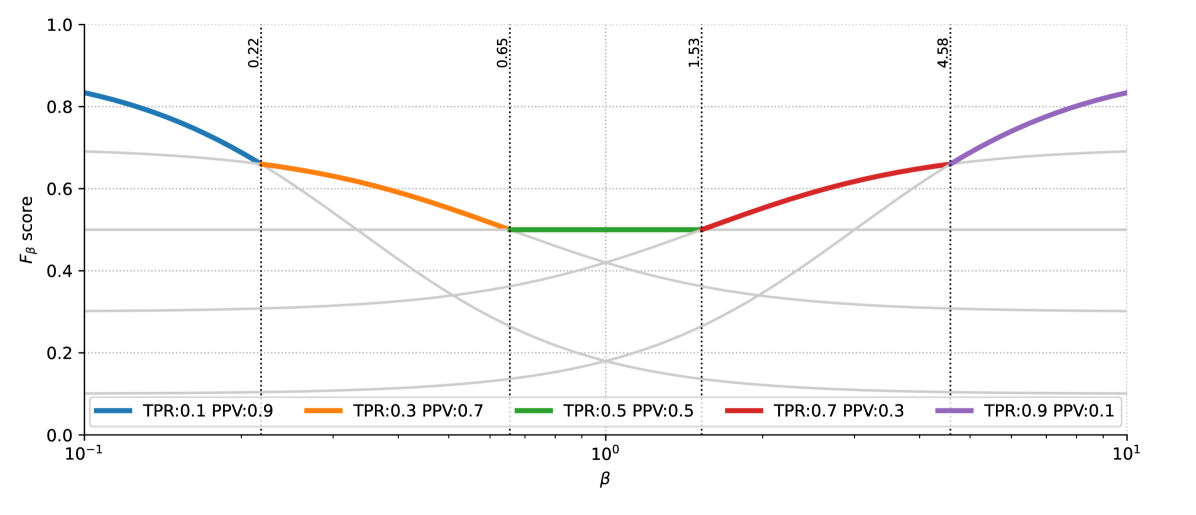
$F_beta$-plot -- a visual tool for evaluating imbalanced data classifiers
Szymon Wojciechowski, Micha{l} Wo'zniak
0
0
One of the significant problems associated with imbalanced data classification is the lack of reliable metrics. This runs primarily from the fact that for most real-life (as well as commonly used benchmark) problems, we do not have information from the user on the actual form of the loss function that should be minimized. Although it is pretty common to have metrics indicating the classification quality within each class, for the end user, the analysis of several such metrics is then required, which in practice causes difficulty in interpreting the usefulness of a given classifier. Hence, many aggregate metrics have been proposed or adopted for the imbalanced data classification problem, but there is still no consensus on which should be used. An additional disadvantage is their ambiguity and systematic bias toward one class. Moreover, their use in analyzing experimental results in recognition of those classification models that perform well for the chosen aggregated metrics is burdened with the drawbacks mentioned above. Hence, the paper proposes a simple approach to analyzing the popular parametric metric $F_beta$. We point out that it is possible to indicate for a given pool of analyzed classifiers when a given model should be preferred depending on user requirements.
4/16/2024
A Closer Look at AUROC and AUPRC under Class Imbalance
Matthew B. A. McDermott (Harvard Medical School), Lasse Hyldig Hansen (Aarhus University), Haoran Zhang (Massachusetts Institute of Technology), Giovanni Angelotti (IRCCS Humanitas Research Hospital), Jack Gallifant (Massachusetts Institute of Technology)
0
0
In machine learning (ML), a widespread adage is that the area under the precision-recall curve (AUPRC) is a superior metric for model comparison to the area under the receiver operating characteristic (AUROC) for binary classification tasks with class imbalance. This paper challenges this notion through novel mathematical analysis, illustrating that AUROC and AUPRC can be concisely related in probabilistic terms. We demonstrate that AUPRC, contrary to popular belief, is not superior in cases of class imbalance and might even be a harmful metric, given its inclination to unduly favor model improvements in subpopulations with more frequent positive labels. This bias can inadvertently heighten algorithmic disparities. Prompted by these insights, a thorough review of existing ML literature was conducted, utilizing large language models to analyze over 1.5 million papers from arXiv. Our investigation focused on the prevalence and substantiation of the purported AUPRC superiority. The results expose a significant deficit in empirical backing and a trend of misattributions that have fuelled the widespread acceptance of AUPRC's supposed advantages. Our findings represent a dual contribution: a significant technical advancement in understanding metric behaviors and a stark warning about unchecked assumptions in the ML community. All experiments are accessible at https://github.com/mmcdermott/AUC_is_all_you_need.
4/19/2024