Robust Reward Placement under Uncertainty
2405.05433
0
0
🛠️
Abstract
We consider a problem of placing generators of rewards to be collected by randomly moving agents in a network. In many settings, the precise mobility pattern may be one of several possible, based on parameters outside our control, such as weather conditions. The placement should be robust to this uncertainty, to gain a competent total reward across possible networks. To study such scenarios, we introduce the Robust Reward Placement problem (RRP). Agents move randomly by a Markovian Mobility Model with a predetermined set of locations whose connectivity is chosen adversarially from a known set $Pi$ of candidates. We aim to select a set of reward states within a budget that maximizes the minimum ratio, among all candidates in $Pi$, of the collected total reward over the optimal collectable reward under the same candidate. We prove that RRP is NP-hard and inapproximable, and develop $Psi$-Saturate, a pseudo-polynomial time algorithm that achieves an $epsilon$-additive approximation by exceeding the budget constraint by a factor that scales as $O(ln |Pi|/epsilon)$. In addition, we present several heuristics, most prominently one inspired by a dynamic programming algorithm for the max-min 0-1 KNAPSACK problem. We corroborate our theoretical analysis with an experimental evaluation on synthetic and real data.
Create account to get full access
Overview
- This paper introduces the Robust Reward Placement (RRP) problem, which aims to find the optimal placement of rewards in a network where the precise connectivity of the network is uncertain.
- Agents move randomly on a Markovian Mobility Model with a predetermined set of locations, but the exact connectivity of the network is unknown and chosen adversarially from a set of possible candidates.
- The goal is to maximize the minimum ratio of rewards obtained over the optimal solution for each possible network candidate.
Plain English Explanation
The paper looks at a common optimization problem called reward placement. In this problem, you have a network where agents (like people or robots) move around randomly, and you want to place a number of rewards in the network to maximize the total reward the agents can collect as they move.
However, the paper considers a twist on this problem - the precise structure of the network (how the different locations are connected) might be uncertain or variable, based on factors outside your control, like weather conditions affecting transportation.
To handle this uncertainty, the researchers introduce the Robust Reward Placement (RRP) problem. In RRP, the network connectivity is not fixed, but can be chosen adversarially from a set of possible options. The goal is to find a reward placement that performs well (i.e., maximizes the minimum ratio of rewards obtained) across all possible network configurations.
This type of robust optimization problem is important in many real-world settings where the environment or system you're trying to optimize for is not fully predictable. By designing solutions that work well regardless of the specific circumstances, you can create more reliable and adaptable systems.
Technical Explanation
The paper formalizes the Robust Reward Placement (RRP) problem, where agents move randomly on a Markovian Mobility Model with a predetermined set of locations, but the precise network connectivity is unknown and chosen from a set of possible candidates, Π.
The goal is to select a set of reward states that maximizes the minimum, across all network candidates, of the ratio of rewards obtained to the optimal rewards for that candidate network. This ensures the solution is robust to the network uncertainty.
The authors first prove that RRP is NP-hard and inapproximable in general. They then develop a Ψ-Saturate algorithm that provides an ε-additive approximation by exceeding the budget constraint by a factor that scales as O(ln|Π|/ε). This algorithm runs in pseudo-polynomial time.
Additionally, the paper presents several heuristic approaches, including one inspired by a dynamic programming algorithm for the max-min 0-1 Knapsack problem. These methods are evaluated experimentally on both synthetic and real-world datasets, corroborating the theoretical findings.
Critical Analysis
The paper's focus on robust optimization in the face of network uncertainty is a valuable contribution, as many real-world optimization problems must contend with unpredictable environments or system parameters. The RRP problem formulation and the Ψ-Saturate algorithm provide a principled approach to addressing this challenge.
However, the paper acknowledges the inherent computational hardness of the RRP problem, which may limit the scalability of the exact algorithm. The heuristic approaches presented could be further explored and refined to provide more efficient solutions for larger-scale problems.
Additionally, the paper does not delve deeply into the potential practical applications or implications of the RRP problem and its solutions. It would be interesting to see more discussion on how this research could be leveraged in various domains, such as transportation planning, network resource allocation, or even multi-agent reinforcement learning.
Further research could also investigate the performance of the proposed methods under different types of network uncertainty, such as distributional robustness or long-run average reward settings, to broaden the applicability and understanding of the RRP problem.
Conclusion
This paper introduces the Robust Reward Placement (RRP) problem, which addresses the challenge of optimizing reward placement in a network with uncertain connectivity. The authors provide a formal problem definition, prove the computational hardness of RRP, and develop a pseudo-polynomial time algorithm with approximation guarantees.
The focus on robust optimization in the face of environmental uncertainty is a valuable contribution to the field. The proposed solutions and insights could be further explored and extended to tackle a wider range of practical applications, potentially leading to more adaptable and reliable optimization strategies across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
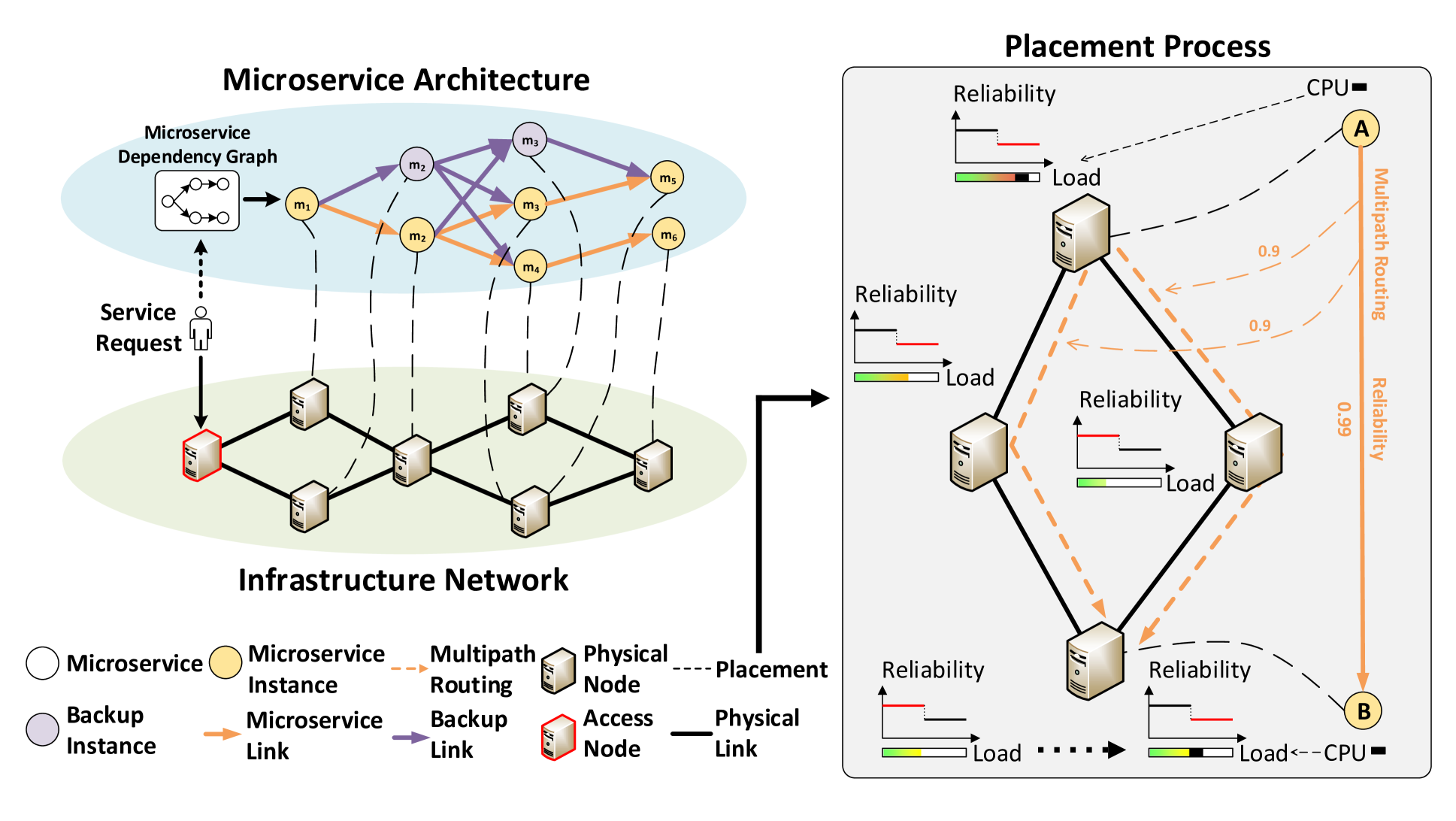
Network-Aware Reliability Modeling and Optimization for Microservice Placement
Fangyu Zhang, Yuang Chen, Hancheng Lu, Yongsheng Huang
0
0
Optimizing microservice placement to enhance the reliability of services is crucial for improving the service level of microservice architecture-based mobile networks and Internet of Things (IoT) networks. Despite extensive research on service reliability, the impact of network load and routing on service reliability remains understudied, leading to suboptimal models and unsatisfactory performance. To address this issue, we propose a novel network-aware service reliability model that effectively captures the correlation between network state changes and reliability. Based on this model, we formulate the microservice placement problem as an integer nonlinear programming problem, aiming to maximize service reliability. Subsequently, a service reliability-aware placement (SRP) algorithm is proposed to solve the problem efficiently. To reduce bandwidth consumption, we further discuss the microservice placement problem with the shared backup path mechanism and propose a placement algorithm based on the SRP algorithm using shared path reliability calculation, known as the SRP-S algorithm. Extensive simulations demonstrate that the SRP algorithm reduces service failures by up to 29% compared to the benchmark algorithms. By introducing the shared backup path mechanism, the SRP-S algorithm reduces bandwidth consumption by up to 62% compared to the SRP algorithm with the fully protected path mechanism. It also reduces service failures by up to 21% compared to the SRP algorithm with the shared backup mechanism.
5/29/2024
Robust Reward Design for Markov Decision Processes
Shuo Wu, Haoxiang Ma, Jie Fu, Shuo Han
0
0
The problem of reward design examines the interaction between a leader and a follower, where the leader aims to shape the follower's behavior to maximize the leader's payoff by modifying the follower's reward function. Current approaches to reward design rely on an accurate model of how the follower responds to reward modifications, which can be sensitive to modeling inaccuracies. To address this issue of sensitivity, we present a solution that offers robustness against uncertainties in modeling the follower, including 1) how the follower breaks ties in the presence of nonunique best responses, 2) inexact knowledge of how the follower perceives reward modifications, and 3) bounded rationality of the follower. Our robust solution is guaranteed to exist under mild conditions and can be obtained numerically by solving a mixed-integer linear program. Numerical experiments on multiple test cases demonstrate that our solution improves robustness compared to the standard approach without incurring significant additional computing costs.
6/10/2024
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
0
0
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
5/10/2024
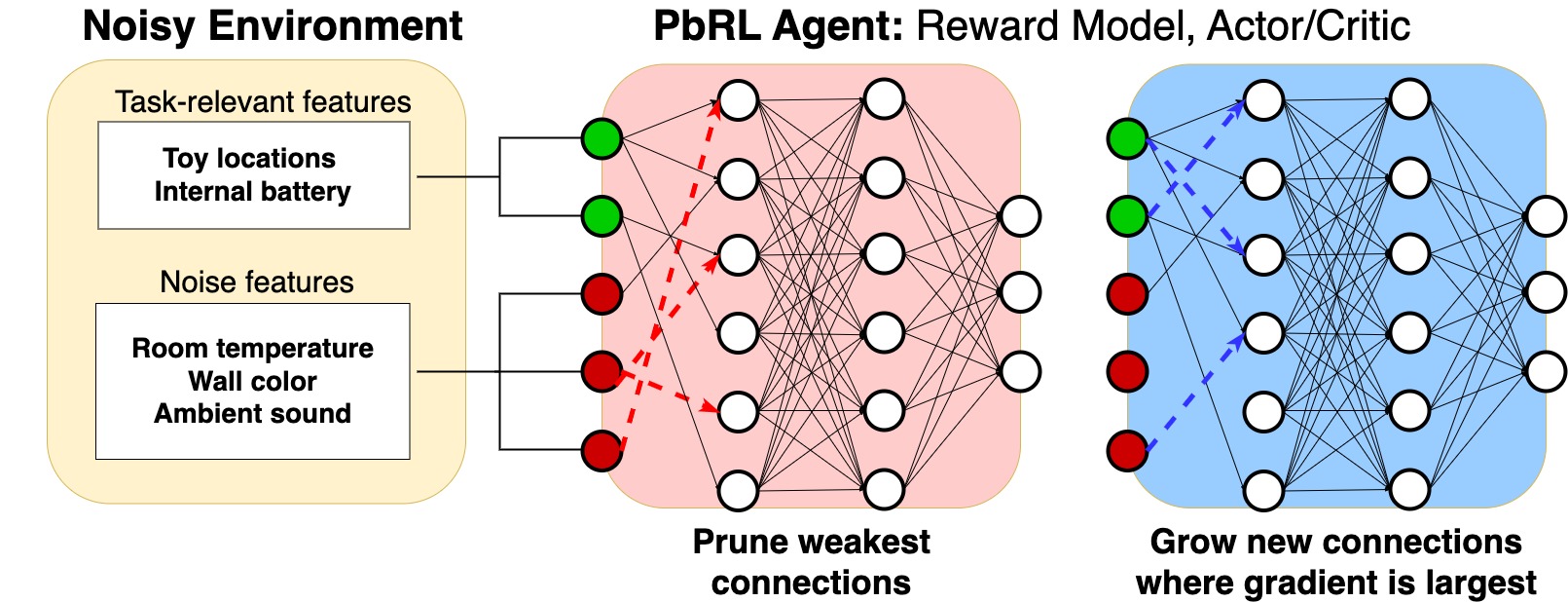
Boosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity
Calarina Muslimani, Bram Grooten, Deepak Ranganatha Sastry Mamillapalli, Mykola Pechenizkiy, Decebal Constantin Mocanu, Matthew E. Taylor
0
0
For autonomous agents to successfully integrate into human-centered environments, agents should be able to learn from and adapt to humans in their native settings. Preference-based reinforcement learning (PbRL) is a promising approach that learns reward functions from human preferences. This enables RL agents to adapt their behavior based on human desires. However, humans live in a world full of diverse information, most of which is not relevant to completing a particular task. It becomes essential that agents learn to focus on the subset of task-relevant environment features. Unfortunately, prior work has largely ignored this aspect; primarily focusing on improving PbRL algorithms in standard RL environments that are carefully constructed to contain only task-relevant features. This can result in algorithms that may not effectively transfer to a more noisy real-world setting. To that end, this work proposes R2N (Robust-to-Noise), the first PbRL algorithm that leverages principles of dynamic sparse training to learn robust reward models that can focus on task-relevant features. We study the effectiveness of R2N in the Extremely Noisy Environment setting, an RL problem setting where up to 95% of the state features are irrelevant distractions. In experiments with a simulated teacher, we demonstrate that R2N can adapt the sparse connectivity of its neural networks to focus on task-relevant features, enabling R2N to significantly outperform several state-of-the-art PbRL algorithms in multiple locomotion and control environments.
6/11/2024