Robust Reward Design for Markov Decision Processes

0
Sign in to get full access
Overview
- This paper presents a new approach to designing robust rewards for Markov Decision Processes (MDPs) under uncertainty.
- The key idea is to optimize the reward function to be resilient to changes in the underlying MDP dynamics.
- The authors propose a method to learn a reward function that can perform well across a range of possible MDP environments, rather than relying on a single, potentially fragile reward function.
Plain English Explanation
The paper tackles the challenge of designing effective reward functions for reinforcement learning agents operating in complex, uncertain environments. In a Markov Decision Process (MDP), an agent must learn to make decisions that maximize a numerical reward signal provided by the environment. However, the true dynamics of the environment are often unknown or can change over time, making it difficult to design a single, optimal reward function.
The authors' key insight is that the reward function itself can be optimized to be robust to these uncertainties. Rather than relying on a single, potentially fragile reward function, they propose a method to learn a reward function that can perform well across a range of possible MDP environments. This "robust reward design" approach is inspired by ideas from distributionally robust optimization and risk-sensitive reinforcement learning.
The key advantage of this approach is that it can produce agents that are more reliable and adaptable in the face of real-world uncertainty, compared to agents trained on a single, potentially brittle reward function. This could be particularly valuable in safety-critical applications, where we want our AI systems to behave predictably and reliably, even as the environment changes over time.
Technical Explanation
The paper formulates the problem of robust reward design as an optimization problem, where the goal is to find a reward function that maximizes the agent's performance across a set of possible MDP environments. Specifically, the authors consider a scenario where the true dynamics of the MDP are not known, but can be sampled from a set of possible transition functions.
The authors propose a novel algorithm, called Robust Reward Optimization (RRO), to solve this problem. RRO alternates between two steps: (1) learning a robust reward function that performs well across the set of possible MDPs, and (2) optimizing the agent's policy for this reward function. This allows the reward function and the agent's policy to co-evolve in a way that is resilient to uncertainty in the MDP dynamics.
The authors evaluate their approach on a range of simulated MDP environments, including classic control tasks and simulated robotic manipulation problems. They show that agents trained using RRO can significantly outperform agents trained on a single, fixed reward function, especially in scenarios where the true MDP dynamics differ from the assumptions used during training.
Critical Analysis
The paper presents a compelling approach to the important problem of robust reward design in reinforcement learning. By explicitly optimizing the reward function to be resilient to uncertainty in the underlying MDP, the authors demonstrate significant performance improvements compared to more traditional reward design methods.
One potential limitation of the approach is that it relies on the ability to sample from a set of possible MDP dynamics during training. In real-world applications, this set of possible dynamics may not be known a priori, and may be difficult to estimate accurately. The authors acknowledge this limitation and suggest extensions to their method that could address this, such as using adversarial techniques to generate a worst-case set of dynamics.
Additionally, the paper focuses primarily on evaluating the approach in simulated environments. While these experiments provide valuable insights, it would be important to validate the method's performance in real-world applications, where the uncertainties and dynamics may be even more complex and challenging to model.
Overall, this paper represents an important step forward in the field of robust reinforcement learning, and the authors' approach could have significant implications for the development of reliable and adaptable AI systems in the future.
Conclusion
This paper presents a novel method for robust reward design in Markov Decision Processes, where the goal is to optimize the reward function to be resilient to uncertainty in the underlying environmental dynamics. By framing this as an optimization problem and proposing the Robust Reward Optimization (RRO) algorithm, the authors demonstrate significant performance improvements over traditional reward design approaches.
The key contribution of this work is the insight that the reward function itself can be a source of robustness, rather than relying solely on a resilient policy. This could have important implications for safety-critical applications of reinforcement learning, where we want our AI systems to behave predictably and reliably, even as the environment changes over time.
While the paper focuses on simulated experiments, the authors' approach represents an important step forward in the field of robust reinforcement learning, and could inspire further research into developing more adaptable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Reward Design for Markov Decision Processes
Shuo Wu, Haoxiang Ma, Jie Fu, Shuo Han
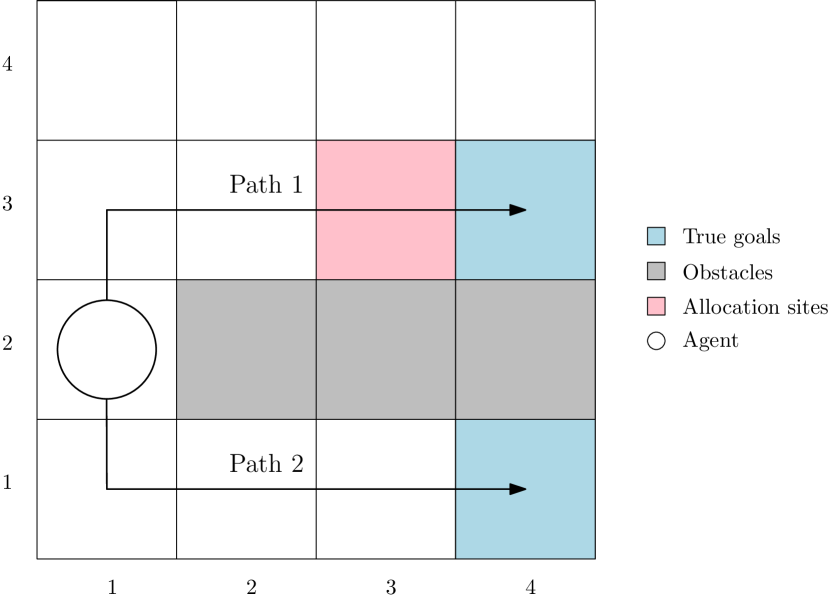
The problem of reward design examines the interaction between a leader and a follower, where the leader aims to shape the follower's behavior to maximize the leader's payoff by modifying the follower's reward function. Current approaches to reward design rely on an accurate model of how the follower responds to reward modifications, which can be sensitive to modeling inaccuracies. To address this issue of sensitivity, we present a solution that offers robustness against uncertainties in modeling the follower, including 1) how the follower breaks ties in the presence of nonunique best responses, 2) inexact knowledge of how the follower perceives reward modifications, and 3) bounded rationality of the follower. Our robust solution is guaranteed to exist under mild conditions and can be obtained numerically by solving a mixed-integer linear program. Numerical experiments on multiple test cases demonstrate that our solution improves robustness compared to the standard approach without incurring significant additional computing costs.
Read more6/10/2024
🌐
0
Synthesis of Reward Machines for Multi-Agent Equilibrium Design (Full Version)
Muhammad Najib, Giuseppe Perelli
Mechanism design is a well-established game-theoretic paradigm for designing games to achieve desired outcomes. This paper addresses a closely related but distinct concept, equilibrium design. Unlike mechanism design, the designer's authority in equilibrium design is more constrained; she can only modify the incentive structures in a given game to achieve certain outcomes without the ability to create the game from scratch. We study the problem of equilibrium design using dynamic incentive structures, known as reward machines. We use weighted concurrent game structures for the game model, with goals (for the players and the designer) defined as mean-payoff objectives. We show how reward machines can be used to represent dynamic incentives that allocate rewards in a manner that optimises the designer's goal. We also introduce the main decision problem within our framework, the payoff improvement problem. This problem essentially asks whether there exists a dynamic incentive (represented by some reward machine) that can improve the designer's payoff by more than a given threshold value. We present two variants of the problem: strong and weak. We demonstrate that both can be solved in polynomial time using a Turing machine equipped with an NP oracle. Furthermore, we also establish that these variants are either NP-hard or coNP-hard. Finally, we show how to synthesise the corresponding reward machine if it exists.
Read more8/20/2024
🛠️
0
Robust Reward Placement under Uncertainty
Petros Petsinis, Kaichen Zhang, Andreas Pavlogiannis, Jingbo Zhou, Panagiotis Karras
We consider a problem of placing generators of rewards to be collected by randomly moving agents in a network. In many settings, the precise mobility pattern may be one of several possible, based on parameters outside our control, such as weather conditions. The placement should be robust to this uncertainty, to gain a competent total reward across possible networks. To study such scenarios, we introduce the Robust Reward Placement problem (RRP). Agents move randomly by a Markovian Mobility Model with a predetermined set of locations whose connectivity is chosen adversarially from a known set $Pi$ of candidates. We aim to select a set of reward states within a budget that maximizes the minimum ratio, among all candidates in $Pi$, of the collected total reward over the optimal collectable reward under the same candidate. We prove that RRP is NP-hard and inapproximable, and develop $Psi$-Saturate, a pseudo-polynomial time algorithm that achieves an $epsilon$-additive approximation by exceeding the budget constraint by a factor that scales as $O(ln |Pi|/epsilon)$. In addition, we present several heuristics, most prominently one inspired by a dynamic programming algorithm for the max-min 0-1 KNAPSACK problem. We corroborate our theoretical analysis with an experimental evaluation on synthetic and real data.
Read more6/4/2024
🏅
0
Stackelberg POMDP: A Reinforcement Learning Approach for Economic Design
Gianluca Brero, Alon Eden, Darshan Chakrabarti, Matthias Gerstgrasser, Amy Greenwald, Vincent Li, David C. Parkes
We introduce a reinforcement learning framework for economic design where the interaction between the environment designer and the participants is modeled as a Stackelberg game. In this game, the designer (leader) sets up the rules of the economic system, while the participants (followers) respond strategically. We integrate algorithms for determining followers' response strategies into the leader's learning environment, providing a formulation of the leader's learning problem as a POMDP that we call the Stackelberg POMDP. We prove that the optimal leader's strategy in the Stackelberg game is the optimal policy in our Stackelberg POMDP under a limited set of possible policies, establishing a connection between solving POMDPs and Stackelberg games. We solve our POMDP under a limited set of policy options via the centralized training with decentralized execution framework. For the specific case of followers that are modeled as no-regret learners, we solve an array of increasingly complex settings, including problems of indirect mechanism design where there is turn-taking and limited communication by agents. We demonstrate the effectiveness of our training framework through ablation studies. We also give convergence results for no-regret learners to a Bayesian version of a coarse-correlated equilibrium, extending known results to correlated types.
Read more7/22/2024