Simplification of Risk Averse POMDPs with Performance Guarantees
2406.03000
0
0

Abstract
Risk averse decision making under uncertainty in partially observable domains is a fundamental problem in AI and essential for reliable autonomous agents. In our case, the problem is modeled using partially observable Markov decision processes (POMDPs), when the value function is the conditional value at risk (CVaR) of the return. Calculating an optimal solution for POMDPs is computationally intractable in general. In this work we develop a simplification framework to speedup the evaluation of the value function, while providing performance guarantees. We consider as simplification a computationally cheaper belief-MDP transition model, that can correspond, e.g., to cheaper observation or transition models. Our contributions include general bounds for CVaR that allow bounding the CVaR of a random variable X, using a random variable Y, by assuming bounds between their cumulative distributions. We then derive bounds for the CVaR value function in a POMDP setting, and show how to bound the value function using the computationally cheaper belief-MDP transition model and without accessing the computationally expensive model in real-time. Then, we provide theoretical performance guarantees for the estimated bounds. Our results apply for a general simplification of a belief-MDP transition model and support simplification of both the observation and state transition models simultaneously.
Create account to get full access
Overview
- This paper proposes a framework for simplifying risk-averse Partially Observable Markov Decision Processes (POMDPs) while providing performance guarantees.
- The researchers develop a method to reduce the complexity of risk-averse POMDPs by leveraging the specific structure of risk measures, such as Conditional Value-at-Risk (CVaR).
- The simplified POMDP models can be solved more efficiently, allowing for better decision-making in uncertain environments.
- The authors also provide theoretical performance guarantees for their approach, ensuring that the simplified models maintain the desired risk-sensitive behavior.
Plain English Explanation
In many real-world decision-making situations, we need to consider not just the expected outcome, but also the potential risks involved. This is particularly true in partially observable environments, where we have incomplete information about the current state. Partially Observable Markov Decision Processes (POMDPs) are a mathematical framework used to model such scenarios.
However, POMDPs can quickly become very complex, making them difficult to solve in a timely and reliable manner. This paper presents a way to simplify risk-averse POMDPs, which means they take into account the potential risks of different actions. The researchers develop a method that leverages the specific structure of risk measures, such as Conditional Value-at-Risk (CVaR), to reduce the complexity of the POMDP model.
By simplifying the POMDP, the authors can solve it more efficiently, allowing for better decision-making in uncertain environments. Importantly, they also provide theoretical guarantees that the simplified model will still maintain the desired risk-sensitive behavior, ensuring that the simplification does not come at the cost of compromising the original goals.
Technical Explanation
The paper introduces a framework for simplifying risk-averse POMDPs while providing performance guarantees. The authors leverage the specific structure of risk measures, such as Conditional Value-at-Risk (CVaR), to reduce the complexity of the POMDP model.
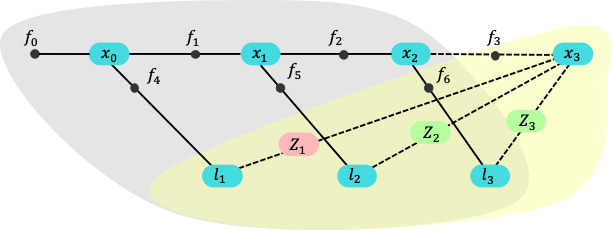
The key idea is to exploit the dynamic programming decomposition of static risk measures in POMDPs. This allows the researchers to systematically simplify the POMDP model without compromising the desired risk-sensitive behavior.
The authors provide theoretical performance guarantees for their approach, ensuring that the simplified POMDP models maintain the risk-sensitive properties of the original problem. This is achieved by bounding the difference between the value functions of the original and simplified POMDPs.
Additionally, the paper presents a sound heuristic search value iteration algorithm for solving the simplified risk-averse POMDPs, building on previous work on undiscounted POMDPs.
Critical Analysis
The paper presents a novel and promising approach to simplifying risk-averse POMDPs while providing performance guarantees. The researchers leverage the specific structure of risk measures, such as CVaR, to systematically reduce the complexity of the POMDP model.
One potential limitation of the approach is that it may not be applicable to all types of risk measures, as the authors rely on the dynamic programming decomposition of static risk measures. It would be interesting to see if the framework could be extended to handle a wider range of risk measures, including those that do not have a similar decomposition structure.
Additionally, the authors focus on theoretical performance guarantees, but it would be valuable to see empirical evaluations of the simplified POMDP models on real-world or benchmark problems. This could provide insights into the practical implications and the actual performance improvements achieved by the proposed simplification method.
Further research could also explore the potential trade-offs between the level of simplification and the fidelity of the risk-sensitive behavior. Investigating how to balance these considerations could lead to more flexible and practical applications of the framework.
Conclusion
This paper presents a novel framework for simplifying risk-averse POMDPs while providing performance guarantees. By leveraging the specific structure of risk measures, such as CVaR, the authors develop a method to reduce the complexity of POMDP models without compromising their risk-sensitive properties.
The theoretical guarantees and the sound heuristic search algorithm for solving the simplified POMDPs suggest that this approach could be a valuable tool for decision-making in uncertain environments, where managing risk is a critical concern. While the current limitations provide opportunities for future research, this work represents an important step forward in the field of risk-aware planning and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Measurement Simplification in rho-POMDP with Performance Guarantees
Tom Yotam, Vadim Indelman
0
0
Decision making under uncertainty is at the heart of any autonomous system acting with imperfect information. The cost of solving the decision making problem is exponential in the action and observation spaces, thus rendering it unfeasible for many online systems. This paper introduces a novel approach to efficient decision-making, by partitioning the high-dimensional observation space. Using the partitioned observation space, we formulate analytical bounds on the expected information-theoretic reward, for general belief distributions. These bounds are then used to plan efficiently while keeping performance guarantees. We show that the bounds are adaptive, computationally efficient, and that they converge to the original solution. We extend the partitioning paradigm and present a hierarchy of partitioned spaces that allows greater efficiency in planning. We then propose a specific variant of these bounds for Gaussian beliefs and show a theoretical performance improvement of at least a factor of 4. Finally, we compare our novel method to other state of the art algorithms in active SLAM scenarios, in simulation and in real experiments. In both cases we show a significant speed-up in planning with performance guarantees.
6/18/2024
Robust Risk-Sensitive Reinforcement Learning with Conditional Value-at-Risk
Xinyi Ni, Lifeng Lai
0
0
Robust Markov Decision Processes (RMDPs) have received significant research interest, offering an alternative to standard Markov Decision Processes (MDPs) that often assume fixed transition probabilities. RMDPs address this by optimizing for the worst-case scenarios within ambiguity sets. While earlier studies on RMDPs have largely centered on risk-neutral reinforcement learning (RL), with the goal of minimizing expected total discounted costs, in this paper, we analyze the robustness of CVaR-based risk-sensitive RL under RMDP. Firstly, we consider predetermined ambiguity sets. Based on the coherency of CVaR, we establish a connection between robustness and risk sensitivity, thus, techniques in risk-sensitive RL can be adopted to solve the proposed problem. Furthermore, motivated by the existence of decision-dependent uncertainty in real-world problems, we study problems with state-action-dependent ambiguity sets. To solve this, we define a new risk measure named NCVaR and build the equivalence of NCVaR optimization and robust CVaR optimization. We further propose value iteration algorithms and validate our approach in simulation experiments.
5/6/2024
👀
Recursively-Constrained Partially Observable Markov Decision Processes
Qi Heng Ho, Tyler Becker, Benjamin Kraske, Zakariya Laouar, Martin S. Feather, Federico Rossi, Morteza Lahijanian, Zachary N. Sunberg
0
0
Many sequential decision problems involve optimizing one objective function while imposing constraints on other objectives. Constrained Partially Observable Markov Decision Processes (C-POMDP) model this case with transition uncertainty and partial observability. In this work, we first show that C-POMDPs violate the optimal substructure property over successive decision steps and thus may exhibit behaviors that are undesirable for some (e.g., safety critical) applications. Additionally, online re-planning in C-POMDPs is often ineffective due to the inconsistency resulting from this violation. To address these drawbacks, we introduce the Recursively-Constrained POMDP (RC-POMDP), which imposes additional history-dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm for RC-POMDPs. Evaluations on benchmark problems demonstrate the efficacy of our algorithm and show that policies for RC-POMDPs produce more desirable behaviors than policies for C-POMDPs.
6/6/2024
🌐
On Dynamic Programming Decompositions of Static Risk Measures in Markov Decision Processes
Jia Lin Hau, Erick Delage, Mohammad Ghavamzadeh, Marek Petrik
0
0
Optimizing static risk-averse objectives in Markov decision processes is difficult because they do not admit standard dynamic programming equations common in Reinforcement Learning (RL) algorithms. Dynamic programming decompositions that augment the state space with discrete risk levels have recently gained popularity in the RL community. Prior work has shown that these decompositions are optimal when the risk level is discretized sufficiently. However, we show that these popular decompositions for Conditional-Value-at-Risk (CVaR) and Entropic-Value-at-Risk (EVaR) are inherently suboptimal regardless of the discretization level. In particular, we show that a saddle point property assumed to hold in prior literature may be violated. However, a decomposition does hold for Value-at-Risk and our proof demonstrates how this risk measure differs from CVaR and EVaR. Our findings are significant because risk-averse algorithms are used in high-stake environments, making their correctness much more critical.
4/24/2024