StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
2405.05691
0
0
🛸
Abstract
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
Create account to get full access
Overview
- Recent years have seen rapid progress in human motion generation due to the powerful generative capabilities of diffusion models.
- Existing diffusion-based methods use different network architectures and training strategies, but the effects of these design choices are unclear.
- The iterative denoising process in diffusion models also consumes significant computational resources, making them unsuitable for real-time applications like virtual characters and robots.
Plain English Explanation
Diffusion models are a type of machine learning model that have recently become very good at generating human motion. However, the different ways these models are designed and trained can affect their performance, and the computational complexity of the models makes them difficult to use in real-time applications.
The researchers wanted to study the different design choices in diffusion models for human motion generation and find ways to make the models more efficient and effective. They aimed to create a robust and efficient framework for generating high-quality human motion.
Technical Explanation
The researchers first conducted a comprehensive investigation into the network architectures, training strategies, and inference processes used in diffusion-based human motion generation models. They analyzed the effects of each component's design to optimize the model for efficient, high-quality motion generation.
Despite the promising performance of their tailored model, the researchers found that it still suffered from a common issue in diffusion-based solutions: foot skating, where the feet appear to slide or float above the ground. To address this, they developed a method to identify foot-ground contact and correct the foot motions during the denoising process.
By combining these well-designed components, the researchers present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experiments show that StableMoFusion outperforms current state-of-the-art methods.
Critical Analysis
The researchers thoroughly investigated the design choices in diffusion-based human motion generation models, which is a valuable contribution to the field. By focusing on improving efficiency and addressing the common issue of foot skating, they have created a more practical solution for real-world applications.
However, the paper does not provide much insight into the specific architectural or training innovations that led to the improved performance. Additionally, the researchers could have explored the use of other techniques, such as motion transfer or latent space control, to further enhance the capabilities of their framework.
Conclusion
The researchers have developed a robust and efficient framework, StableMoFusion, for generating high-quality human motion using diffusion models. By optimizing the network architecture, training strategies, and inference process, and addressing the issue of foot skating, they have created a practical solution that outperforms current state-of-the-art methods. This work represents a significant step forward in making diffusion-based human motion generation more accessible for real-time applications like virtual characters and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
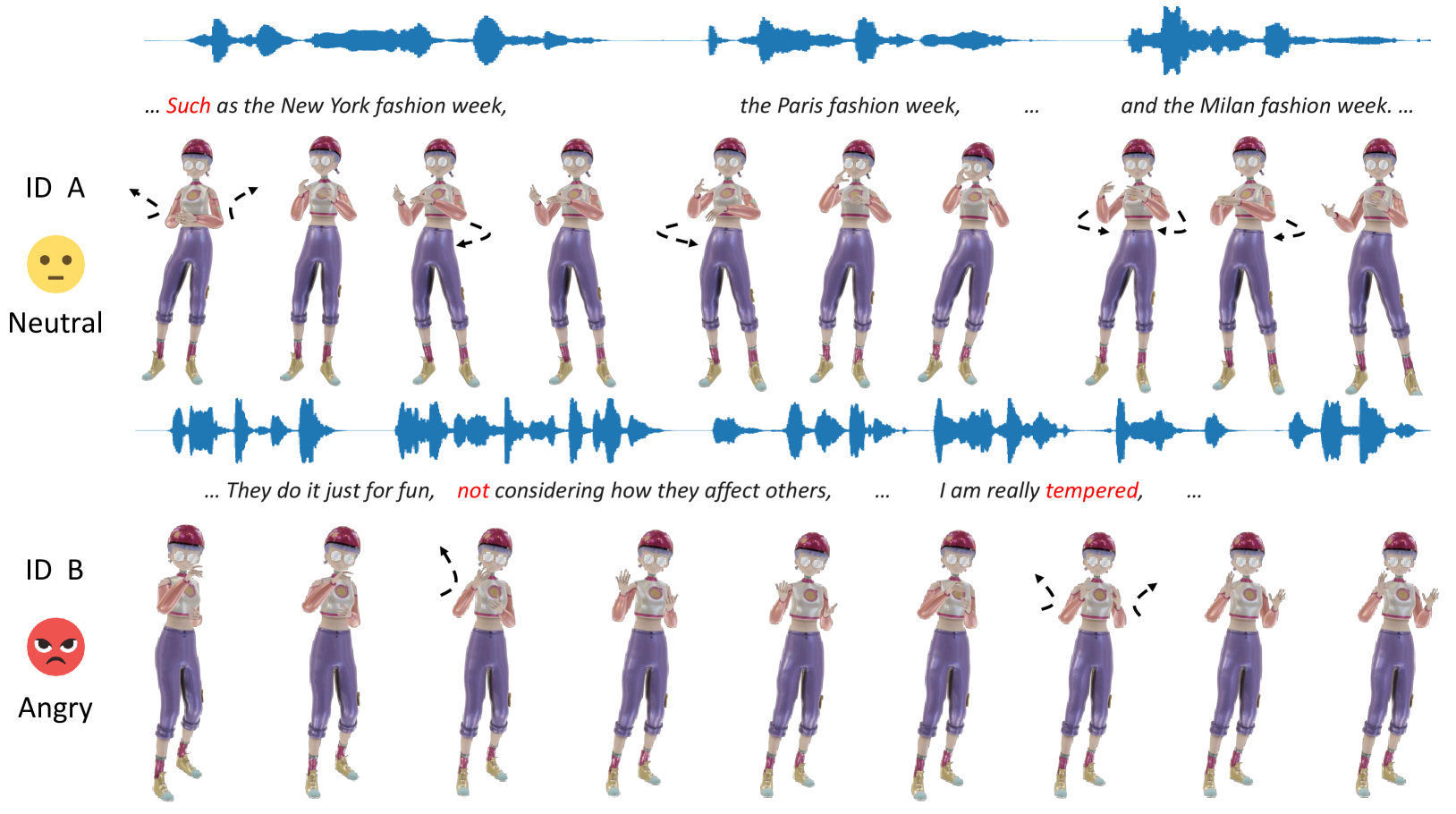
MMoFusion: Multi-modal Co-Speech Motion Generation with Diffusion Model
Sen Wang, Jiangning Zhang, Weijian Cao, Xiaobin Hu, Moran Li, Xiaozhong Ji, Xin Tan, Mengtian Li, Zhifeng Xie, Chengjie Wang, Lizhuang Ma
0
0
The body movements accompanying speech aid speakers in expressing their ideas. Co-speech motion generation is one of the important approaches for synthesizing realistic avatars. Due to the intricate correspondence between speech and motion, generating realistic and diverse motion is a challenging task. In this paper, we propose MMoFusion, a Multi-modal co-speech Motion generation framework based on the diffusion model to ensure both the authenticity and diversity of generated motion. We propose a progressive fusion strategy to enhance the interaction of inter-modal and intra-modal, efficiently integrating multi-modal information. Specifically, we employ a masked style matrix based on emotion and identity information to control the generation of different motion styles. Temporal modeling of speech and motion is partitioned into style-guided specific feature encoding and shared feature encoding, aiming to learn both inter-modal and intra-modal features. Besides, we propose a geometric loss to enforce the joints' velocity and acceleration coherence among frames. Our framework generates vivid, diverse, and style-controllable motion of arbitrary length through inputting speech and editing identity and emotion. Extensive experiments demonstrate that our method outperforms current co-speech motion generation methods including upper body and challenging full body.
5/20/2024
🔄
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
0
0
In recent years, the emergence of generative models has spurred development of human motion generation, among which the generation of stylized human motion has consistently been a focal point of research. The conventional approach for stylized human motion generation involves transferring the style from given style examples to new motions. Despite decades of research in human motion style transfer, it still faces three main challenges: 1) difficulties in decoupling the motion content and style; 2) generalization to unseen motion style. 3) requirements of dedicated motion style dataset; To address these issues, we propose an on-the-fly human motion style transfer learning method based on the diffusion model, which can learn a style transfer model in a few minutes of fine-tuning to transfer an unseen style to diverse content motions. The key idea of our method is to consider the denoising process of the diffusion model as a motion translation process that learns the difference between the style-neutral motion pair, thereby avoiding the challenge of style and content decoupling. Specifically, given an unseen style example, we first generate the corresponding neutral motion through the proposed Style-Neutral Motion Pair Generation module. We then add noise to the generated neutral motion and denoise it to be close to the style example to fine-tune the style transfer diffusion model. We only need one style example and a text-to-motion dataset with predominantly neutral motion (e.g. HumanML3D). The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
5/14/2024

Shape Conditioned Human Motion Generation with Diffusion Model
Kebing Xue, Hyewon Seo
0
0
Human motion synthesis is an important task in computer graphics and computer vision. While focusing on various conditioning signals such as text, action class, or audio to guide the generation process, most existing methods utilize skeleton-based pose representation, requiring additional skinning to produce renderable meshes. Given that human motion is a complex interplay of bones, joints, and muscles, considering solely the skeleton for generation may neglect their inherent interdependency, which can limit the variability and precision of the generated results. To address this issue, we propose a Shape-conditioned Motion Diffusion model (SMD), which enables the generation of motion sequences directly in mesh format, conditioned on a specified target mesh. In SMD, the input meshes are transformed into spectral coefficients using graph Laplacian, to efficiently represent meshes. Subsequently, we propose a Spectral-Temporal Autoencoder (STAE) to leverage cross-temporal dependencies within the spectral domain. Extensive experimental evaluations show that SMD not only produces vivid and realistic motions but also achieves competitive performance in text-to-motion and action-to-motion tasks when compared to state-of-the-art methods.
5/14/2024
🏋️
Video Diffusion Models are Training-free Motion Interpreter and Controller
Zeqi Xiao, Yifan Zhou, Shuai Yang, Xingang Pan
0
0
Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
5/24/2024