On the Role of Summary Content Units in Text Summarization Evaluation
2404.01701
0
0
Abstract
At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Create account to get full access
Overview
- This paper examines the role of summary content units (SCUs) in evaluating text summarization systems.
- SCUs are the basic units of meaning that capture the key information in a reference summary.
- The authors investigate how the number and quality of SCUs in system-generated summaries impact human evaluation of those summaries.
Plain English Explanation
The paper looks at a crucial component of evaluating text summarization systems - summary content units (SCUs). SCUs are the fundamental building blocks that capture the important information in a reference summary written by humans.
The researchers wanted to understand how the number and quality of SCUs in computer-generated summaries affect how humans judge the quality of those summaries. In other words, they investigated what role SCUs play in the human evaluation process for text summarization.
This is an important question because summary evaluation is essential for improving summarization technology. By understanding the factors that influence human judgments, the researchers can provide guidance on how to design better evaluation methods for text summarization.
Technical Explanation
The paper reports on a study that manipulated the content of system-generated summaries to investigate the role of SCUs. The authors created four different versions of each summary:
- The original system-generated summary.
- A version with more SCUs than the original.
- A version with fewer SCUs than the original.
- A version with the same number of SCUs as the original, but of lower quality.
They then had human judges evaluate the quality of these different summary versions. The results showed that the number and quality of SCUs had a significant impact on the human ratings. Summaries with more high-quality SCUs were rated higher, while those with fewer or lower-quality SCUs were rated lower.
These findings suggest that SCUs are a crucial component of summary evaluation. The authors argue that designing evaluation metrics that accurately capture SCU-level quality and quantity is essential for reliably assessing text summarization systems.
Critical Analysis
The paper provides valuable insights into the role of SCUs in summary evaluation, but it also has some limitations. The study used a relatively small dataset, so the generalizability of the results may be limited. Additionally, the authors acknowledge that their manipulation of SCUs in the summaries may not fully reflect real-world summarization system outputs.
Further research could explore how these findings apply to different domains, text genres, and summarization approaches. It would also be interesting to investigate how SCU-based evaluation compares to other summary evaluation methods, such as ROUGE, and how they can be combined for a more comprehensive assessment.
Conclusion
This paper highlights the importance of summary content units (SCUs) in the evaluation of text summarization systems. The results demonstrate that the number and quality of SCUs in system-generated summaries have a significant impact on human judgments of summary quality.
These insights can inform the development of more robust and reliable summary evaluation methods, which is crucial for advancing text summarization technology. By focusing on SCU-level quality, researchers and practitioners can design evaluation approaches that better capture the underlying strengths and weaknesses of summarization systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
0
0
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
7/2/2024
🧠
Which Information Matters? Dissecting Human-written Multi-document Summaries with Partial Information Decomposition
Laura Mascarell, Yan L'Homme, Majed El Helou
0
0
Understanding the nature of high-quality summaries is crucial to further improve the performance of multi-document summarization. We propose an approach to characterize human-written summaries using partial information decomposition, which decomposes the mutual information provided by all source documents into union, redundancy, synergy, and unique information. Our empirical analysis on different MDS datasets shows that there is a direct dependency between the number of sources and their contribution to the summary.
5/24/2024
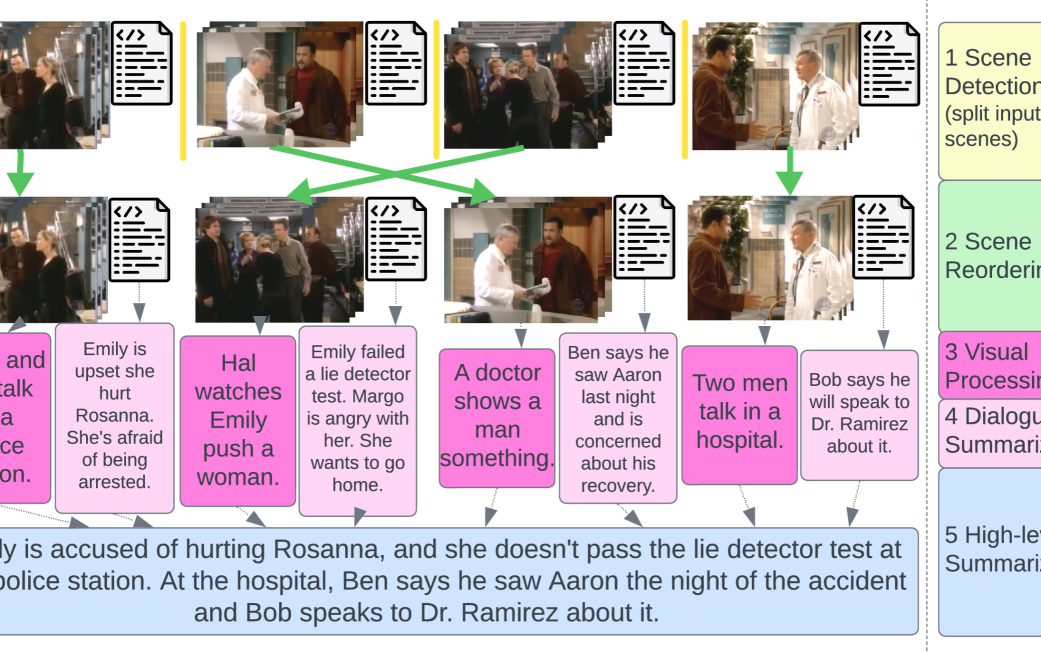
A Modular Approach for Multimodal Summarization of TV Shows
Louis Mahon, Mirella Lapata
0
0
In this paper we address the task of summarizing television shows, which touches key areas in AI research: complex reasoning, multiple modalities, and long narratives. We present a modular approach where separate components perform specialized sub-tasks which we argue affords greater flexibility compared to end-to-end methods. Our modules involve detecting scene boundaries, reordering scenes so as to minimize the number of cuts between different events, converting visual information to text, summarizing the dialogue in each scene, and fusing the scene summaries into a final summary for the entire episode. We also present a new metric, PREFS (Precision and Recall Evaluation of Summary FactS), to measure both precision and recall of generated summaries, which we decompose into atomic facts. Tested on the recently released SummScreen3D dataset Papalampidi and Lapata (2023), our method produces higher quality summaries than comparison models, as measured with ROUGE and our new fact-based metric.
6/17/2024
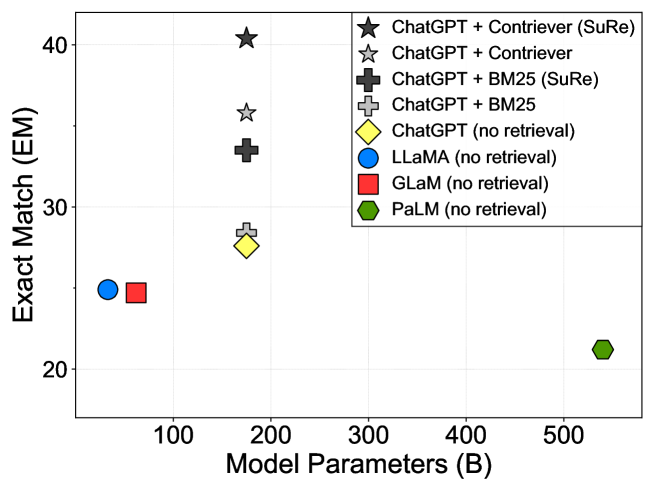
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Jaehyung Kim, Jaehyun Nam, Sangwoo Mo, Jongjin Park, Sang-Woo Lee, Minjoon Seo, Jung-Woo Ha, Jinwoo Shin
0
0
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
4/23/2024