Rough Transformers: Lightweight Continuous-Time Sequence Modelling with Path Signatures

0
🤖
Sign in to get full access
Overview
- Real-world time-series data often exhibits long-range dependencies and is observed at irregular intervals, making traditional sequence-based models ineffective.
- Researchers have explored two approaches to address this challenge: Neural ODE-based models to handle irregularly sampled data and Transformer-based architectures to capture long-range dependencies.
- However, both approaches incur high computational costs, especially for longer input sequences.
Plain English Explanation
The paper introduces a new model called the "Rough Transformer" that aims to overcome the limitations of these existing approaches. The key idea is to use a continuous-time representation of the input data, which allows the model to capture long-range dependencies while remaining computationally efficient.
The Rough Transformer uses a technique called "multi-view signature attention" to augment the standard Transformer attention mechanism. This approach leverages path signatures to capture both local and global dependencies in the input data, without being sensitive to changes in sequence length or sampling frequency.
By operating on continuous-time representations and using this specialized attention mechanism, the Rough Transformer can outperform traditional Transformer models on a variety of time-series-related tasks, while requiring significantly less computational resources.
Technical Explanation
The paper proposes the Rough Transformer, a variation of the Transformer model that operates on continuous-time representations of input sequences. This allows the model to handle irregularly sampled data and capture long-range dependencies, while remaining more computationally efficient than existing approaches.
The key innovation is the "multi-view signature attention" mechanism, which uses path signatures to augment the standard Transformer attention. This approach allows the model to consider both local and global (multi-scale) dependencies in the input data, without being sensitive to changes in sequence length or sampling frequency.
The authors demonstrate the effectiveness of the Rough Transformer on a range of time-series-related tasks, such as leveraging 2D information for long-term time-series prediction and attention-based RNN modeling. They show that the Rough Transformer consistently outperforms vanilla Transformer models, while requiring a fraction of the computational time and memory resources, thanks to its continuous-time representation and specialized attention mechanism.
Critical Analysis
The paper provides a compelling solution to the challenges of working with real-world time-series data, which often exhibits long-range dependencies and irregular sampling. The Rough Transformer's use of continuous-time representations and multi-view signature attention is a novel and promising approach, as it combines the benefits of Neural ODE-based models and Transformer-based architectures without incurring their high computational costs.
However, the paper does not address the potential limitations of the path signature approach, which may struggle to capture higher-order dependencies or handle complex, nonlinear time-series data. Additionally, the authors do not provide a detailed analysis of the Rough Transformer's performance on a wider range of time-series tasks or datasets, which would help to better understand its generalizability and limitations.
Further research could explore ways to boost the performance of Transformer-based models on long sequences, potentially by combining the Rough Transformer's continuous-time representation and specialized attention mechanism with other techniques, such as structured matrix approaches.
Conclusion
The Rough Transformer presents a novel and efficient solution for working with real-world time-series data, which often exhibits long-range dependencies and irregular sampling. By using continuous-time representations and a specialized attention mechanism based on path signatures, the Rough Transformer can outperform traditional Transformer models while requiring significantly less computational resources.
This research highlights the potential of combining techniques from different domains, such as Neural ODE-based models and Transformer-based architectures, to tackle the unique challenges of time-series data. As the field continues to evolve, the Rough Transformer's approach could have important implications for a wide range of time-series-related applications, from forecasting to anomaly detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Rough Transformers: Lightweight Continuous-Time Sequence Modelling with Path Signatures
Fernando Moreno-Pino, 'Alvaro Arroyo, Harrison Waldon, Xiaowen Dong, 'Alvaro Cartea
Time-series data in real-world settings typically exhibit long-range dependencies and are observed at non-uniform intervals. In these settings, traditional sequence-based recurrent models struggle. To overcome this, researchers often replace recurrent architectures with Neural ODE-based models to account for irregularly sampled data and use Transformer-based architectures to account for long-range dependencies. Despite the success of these two approaches, both incur very high computational costs for input sequences of even moderate length. To address this challenge, we introduce the Rough Transformer, a variation of the Transformer model that operates on continuous-time representations of input sequences and incurs significantly lower computational costs. In particular, we propose textit{multi-view signature attention}, which uses path signatures to augment vanilla attention and to capture both local and global (multi-scale) dependencies in the input data, while remaining robust to changes in the sequence length and sampling frequency and yielding improved spatial processing. We find that, on a variety of time-series-related tasks, Rough Transformers consistently outperform their vanilla attention counterparts while obtaining the representational benefits of Neural ODE-based models, all at a fraction of the computational time and memory resources.
Read more6/3/2024
0
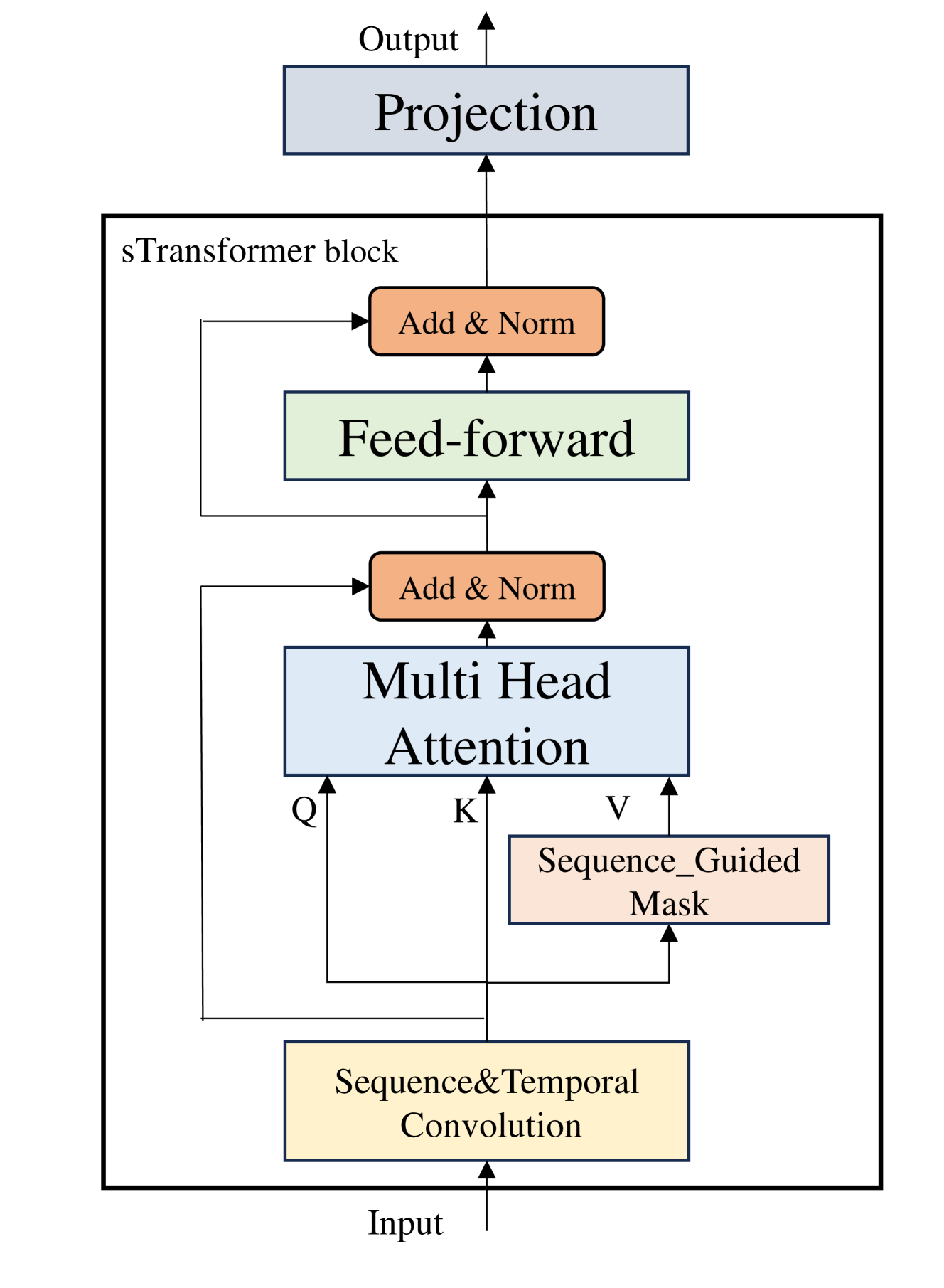
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Jiaheng Yin, Zhengxin Shi, Jianshen Zhang, Xiaomin Lin, Yulin Huang, Yongzhi Qi, Wei Qi
In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Read more8/20/2024

0
Lecture notes on rough paths and applications to machine learning
Thomas Cass, Cristopher Salvi
These notes expound the recent use of the signature transform and rough path theory in data science and machine learning. We develop the core theory of the signature from first principles and then survey some recent popular applications of this approach, including signature-based kernel methods and neural rough differential equations. The notes are based on a course given by the two authors at Imperial College London.
Read more4/11/2024
0
tsGT: Stochastic Time Series Modeling With Transformer
{L}ukasz Kuci'nski, Witold Drzewakowski, Mateusz Olko, Piotr Kozakowski, {L}ukasz Maziarka, Marta Emilia Nowakowska, {L}ukasz Kaiser, Piotr Mi{l}o's
Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
Read more4/4/2024