RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision

0

Sign in to get full access
Overview
- The paper introduces RT-DETRv3, a real-time end-to-end object detection model that uses a novel hierarchical dense positive supervision approach.
- RT-DETRv3 is designed to achieve high accuracy while maintaining real-time inference speeds, making it suitable for practical applications.
- The model builds upon previous DETR-based detectors and introduces several key improvements to boost performance.
Plain English Explanation
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision is a new object detection model that aims to be both highly accurate and capable of running in real-time. This is important for applications like self-driving cars, security cameras, and augmented reality, where fast and precise object detection is crucial.
The model is based on the DETR (Detector Transformers) architecture, which is known for its strong performance. However, the authors have introduced several key improvements to make the model even better.
One of the main innovations is the hierarchical dense positive supervision approach. This means the model is trained to not only detect objects, but also to predict detailed information about them, like their exact location and size. This additional supervision helps the model learn more effectively and boosts its accuracy.
The authors also made other changes to the model architecture and training process to further improve its speed and performance. The end result is a detector that can run in real-time while maintaining state-of-the-art object detection capabilities.
Technical Explanation
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision builds upon previous work on DETR-based object detectors, which have shown strong performance but struggled to achieve real-time inference speeds.
The key innovations in RT-DETRv3 include:
-
Hierarchical Dense Positive Supervision: The model is trained not only to predict object classes and bounding boxes, but also to regress detailed information about the objects, such as their exact center coordinates, height, and width. This dense supervision at multiple levels helps the model learn more effective representations.
-
Efficient Encoder-Decoder Architecture: The authors redesigned the encoder and decoder components of the DETR model to be more computationally efficient, enabling real-time inference speeds.
-
Bag of Freebies: The authors experimented with various training techniques and "freebies" (e.g., data augmentation, regularization) to further boost the model's performance without sacrificing speed.
Through these improvements, RT-DETRv3 is able to achieve state-of-the-art object detection accuracy while maintaining real-time inference capabilities, making it suitable for practical applications that require fast and precise object detection.
Critical Analysis
The paper provides a thorough evaluation of RT-DETRv3, including comparisons to other state-of-the-art object detectors on several benchmark datasets. The results demonstrate the model's strong performance and ability to run in real-time, which is a significant achievement.
However, the paper does not address some potential limitations or areas for further research:
-
Generalization: While RT-DETRv3 performs well on the evaluated datasets, it would be valuable to assess its robustness and generalization to more diverse and challenging real-world scenarios.
-
Resource Requirements: The paper does not provide detailed information about the computational resources (e.g., memory, power consumption) required to run RT-DETRv3 in real-time, which could be important for certain applications.
-
Qualitative Analysis: The paper focuses primarily on quantitative metrics and would benefit from a more in-depth qualitative analysis of the model's strengths, weaknesses, and failure cases.
-
Interpretability: As with many deep learning models, the inner workings of RT-DETRv3 may be challenging to interpret, which could limit its transparency and explainability in critical applications.
Overall, RT-DETRv3 represents a significant advancement in real-time object detection, but further research and analysis could help address these potential limitations and enhance the model's practical applicability.
Conclusion
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision introduces a novel object detection model that achieves state-of-the-art accuracy while maintaining real-time inference speeds. The key innovations include a hierarchical dense positive supervision approach and an efficient encoder-decoder architecture, which enable the model to learn more effective representations and run efficiently.
The strong performance of RT-DETRv3 on benchmark datasets, coupled with its real-time capabilities, make it a promising solution for practical applications that require fast and precise object detection, such as self-driving cars, security systems, and augmented reality. While the paper does not address certain limitations, the model's advancements represent an important step forward in the field of object detection and could have significant implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
Shuo Wang, Chunlong Xia, Feng Lv, Yifeng Shi
RT-DETR is the first real-time end-to-end transformer-based object detector. Its efficiency comes from the framework design and the Hungarian matching. However, compared to dense supervision detectors like the YOLO series, the Hungarian matching provides much sparser supervision, leading to insufficient model training and difficult to achieve optimal results. To address these issues, we proposed a hierarchical dense positive supervision method based on RT-DETR, named RT-DETRv3. Firstly, we introduce a CNN-based auxiliary branch that provides dense supervision that collaborates with the original decoder to enhance the encoder feature representation. Secondly, to address insufficient decoder training, we propose a novel learning strategy involving self-attention perturbation. This strategy diversifies label assignment for positive samples across multiple query groups, thereby enriching positive supervisions. Additionally, we introduce a shared-weight decoder branch for dense positive supervision to ensure more high-quality queries matching each ground truth. Notably, all aforementioned modules are training-only. We conduct extensive experiments to demonstrate the effectiveness of our approach on COCO val2017. RT-DETRv3 significantly outperforms existing real-time detectors, including the RT-DETR series and the YOLO series. For example, RT-DETRv3-R18 achieves 48.1% AP (+1.6%/+1.4%) compared to RT-DETR-R18/RT-DETRv2-R18 while maintaining the same latency. Meanwhile, it requires only half of epochs to attain a comparable performance. Furthermore, RT-DETRv3-R101 can attain an impressive 54.6% AP outperforming YOLOv10-X. Code will be released soon.
Read more9/16/2024
🔎
1
DETRs Beat YOLOs on Real-time Object Detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. We build RT-DETR in two steps, drawing on the advanced DETR: first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: https://zhao-yian.github.io/RTDETR.
Read more4/4/2024
🔎
0
RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu
In this report, we present RT-DETRv2, an improved Real-Time DEtection TRansformer (RT-DETR). RT-DETRv2 builds upon the previous state-of-the-art real-time detector, RT-DETR, and opens up a set of bag-of-freebies for flexibility and practicality, as well as optimizing the training strategy to achieve enhanced performance. To improve the flexibility, we suggest setting a distinct number of sampling points for features at different scales in the deformable attention to achieve selective multi-scale feature extraction by the decoder. To enhance practicality, we propose an optional discrete sampling operator to replace the grid_sample operator that is specific to RT-DETR compared to YOLOs. This removes the deployment constraints typically associated with DETRs. For the training strategy, we propose dynamic data augmentation and scale-adaptive hyperparameters customization to improve performance without loss of speed. Source code and pre-trained models will be available at https://github.com/lyuwenyu/RT-DETR.
Read more7/25/2024
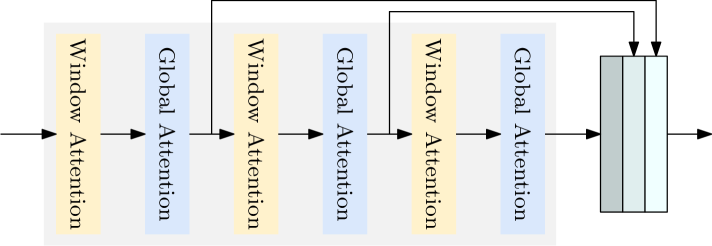
0
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
Qiang Chen, Xiangbo Su, Xinyu Zhang, Jian Wang, Jiahui Chen, Yunpeng Shen, Chuchu Han, Ziliang Chen, Weixiang Xu, Fanrong Li, Shan Zhang, Kun Yao, Errui Ding, Gang Zhang, Jingdong Wang
In this paper, we present a light-weight detection transformer, LW-DETR, which outperforms YOLOs for real-time object detection. The architecture is a simple stack of a ViT encoder, a projector, and a shallow DETR decoder. Our approach leverages recent advanced techniques, such as training-effective techniques, e.g., improved loss and pretraining, and interleaved window and global attentions for reducing the ViT encoder complexity. We improve the ViT encoder by aggregating multi-level feature maps, and the intermediate and final feature maps in the ViT encoder, forming richer feature maps, and introduce window-major feature map organization for improving the efficiency of interleaved attention computation. Experimental results demonstrate that the proposed approach is superior over existing real-time detectors, e.g., YOLO and its variants, on COCO and other benchmark datasets. Code and models are available at (https://github.com/Atten4Vis/LW-DETR).
Read more6/6/2024