Live and Learn: Continual Action Clustering with Incremental Views
2404.07962
0
0

Abstract
Multi-view action clustering leverages the complementary information from different camera views to enhance the clustering performance. Although existing approaches have achieved significant progress, they assume all camera views are available in advance, which is impractical when the camera view is incremental over time. Besides, learning the invariant information among multiple camera views is still a challenging issue, especially in continual learning scenario. Aiming at these problems, we propose a novel continual action clustering (CAC) method, which is capable of learning action categories in a continual learning manner. To be specific, we first devise a category memory library, which captures and stores the learned categories from historical views. Then, as a new camera view arrives, we only need to maintain a consensus partition matrix, which can be updated by leveraging the incoming new camera view rather than keeping all of them. Finally, a three-step alternate optimization is proposed, in which the category memory library and consensus partition matrix are optimized. The empirical experimental results on 6 realistic multi-view action collections demonstrate the excellent clustering performance and time/space efficiency of the CAC compared with 15 state-of-the-art baselines.
Create account to get full access
Overview
- This paper presents a novel approach for "continual action clustering with incremental views", which aims to group actions in a continually evolving environment where new data and views are added over time.
- The key ideas include an incremental multi-view clustering algorithm that can adapt to new data and views, and a framework for continual action clustering that learns representations and clusters actions in an online manner.
- The proposed method is evaluated on several real-world datasets and shown to outperform existing approaches in terms of clustering accuracy and efficiency.
Plain English Explanation
In this paper, the researchers have developed a new way to group or "cluster" actions in a setting where new information keeps getting added over time. Imagine you're trying to organize your music library - as you keep adding new songs, you want to be able to automatically group similar songs together, even as the library grows and changes.
The core of their approach is an "incremental multi-view clustering" algorithm. This means the method can adapt and update the groupings as new "views" or types of information about the actions become available. For example, if you're clustering actions in a video game, the initial view might be the raw gameplay data. But later, you might get additional information like the player's comments or the action's visual features - the algorithm can incorporate these new views to refine the groupings.
Importantly, the method learns these groupings in an "online" or continual fashion, without having to reprocess all the data from scratch every time something new is added. This makes it efficient and scalable, able to handle real-world scenarios where data is constantly evolving.
The researchers demonstrate the effectiveness of their approach on several real-world datasets, showing it outperforms existing methods in terms of accurately grouping the actions and doing so quickly.
Technical Explanation
The paper proposes a framework for continual action clustering with incremental views, which aims to group actions in a setting where new data and new "views" (sources of information about the actions) are added over time.
The key components of the approach are:
-
Incremental Multi-view Clustering: The researchers develop an algorithm that can update the action groupings (clusters) as new views become available, without having to reprocess all the data from the beginning. This builds on prior work in incremental multi-view clustering.
-
Continual Action Clustering: The framework learns representations and clusters actions in an online, continual fashion. This allows it to adapt to evolving data and views, unlike traditional batch-based clustering approaches.
The method is evaluated on several real-world datasets, including human activity recognition and robotic manipulation tasks. Experiments show the proposed approach outperforms state-of-the-art continual learning and multi-view clustering methods in terms of clustering accuracy and efficiency.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed continual action clustering framework. However, a few potential limitations and areas for future work are worth noting:
-
Representation Learning: The paper focuses on the clustering aspect, but the representation learning component is relatively simple. Exploring more advanced representation learning techniques could potentially improve the overall performance.
-
Real-world Deployment: While the experiments cover diverse datasets, the paper does not address some practical challenges that may arise when deploying such a system in a real-world, industrial setting. Further research is needed to understand the robustness and scalability of the approach in more complex, dynamic environments.
-
Interpretability: The paper does not discuss the interpretability of the learned clusters. In many applications, understanding the reasoning behind the groupings is crucial. Incorporating interpretability mechanisms could enhance the usability and trust in the system.
Overall, the paper presents a compelling approach to the important problem of continual action clustering. The incremental, multi-view clustering algorithm is a significant contribution, and the evaluation demonstrates its effectiveness. Further research to address the above limitations could lead to even more impactful and practical solutions.
Conclusion
This paper introduces a novel framework for "continual action clustering with incremental views", which addresses the challenge of grouping actions in dynamic, evolving environments. The key innovation is an incremental multi-view clustering algorithm that can adapt to new data and views over time, coupled with a continual learning approach for learning representations and clusters.
The proposed method is shown to outperform existing techniques in terms of clustering accuracy and efficiency, making it a promising solution for real-world applications like human activity recognition and robotic manipulation. While the paper highlights several areas for potential improvement, the overall contribution represents an important step forward in enabling AI systems to learn and adapt in complex, changing environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Continual Learning in the Presence of Repetition
Hamed Hemati, Lorenzo Pellegrini, Xiaotian Duan, Zixuan Zhao, Fangfang Xia, Marc Masana, Benedikt Tscheschner, Eduardo Veas, Yuxiang Zheng, Shiji Zhao, Shao-Yuan Li, Sheng-Jun Huang, Vincenzo Lomonaco, Gido M. van de Ven
0
0
Continual learning (CL) provides a framework for training models in ever-evolving environments. Although re-occurrence of previously seen objects or tasks is common in real-world problems, the concept of repetition in the data stream is not often considered in standard benchmarks for CL. Unlike with the rehearsal mechanism in buffer-based strategies, where sample repetition is controlled by the strategy, repetition in the data stream naturally stems from the environment. This report provides a summary of the CLVision challenge at CVPR 2023, which focused on the topic of repetition in class-incremental learning. The report initially outlines the challenge objective and then describes three solutions proposed by finalist teams that aim to effectively exploit the repetition in the stream to learn continually. The experimental results from the challenge highlight the effectiveness of ensemble-based solutions that employ multiple versions of similar modules, each trained on different but overlapping subsets of classes. This report underscores the transformative potential of taking a different perspective in CL by employing repetition in the data stream to foster innovative strategy design.
5/8/2024
🚀
Learning to Learn for Few-shot Continual Active Learning
Stella Ho, Ming Liu, Shang Gao, Longxiang Gao
0
0
Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in continual learning are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning setting where labeled data are inadequate, and unlabeled data are abundant but with a limited annotation budget. We exploit meta-learning and propose a method, called Meta-Continual Active Learning. This method sequentially queries the most informative examples from a pool of unlabeled data for annotation to enhance task-specific performance and tackle continual learning problems through meta-objective. Specifically, we employ meta-learning and experience replay to address inter-task confusion and catastrophic forgetting. We further incorporate textual augmentations to avoid memory over-fitting caused by experience replay and sample queries, thereby ensuring generalization. We conduct extensive experiments on benchmark text classification datasets from diverse domains to validate the feasibility and effectiveness of meta-continual active learning. We also analyze the impact of different active learning strategies on various meta continual learning models. The experimental results demonstrate that introducing randomness into sample selection is the best default strategy for maintaining generalization in meta-continual learning framework.
6/3/2024
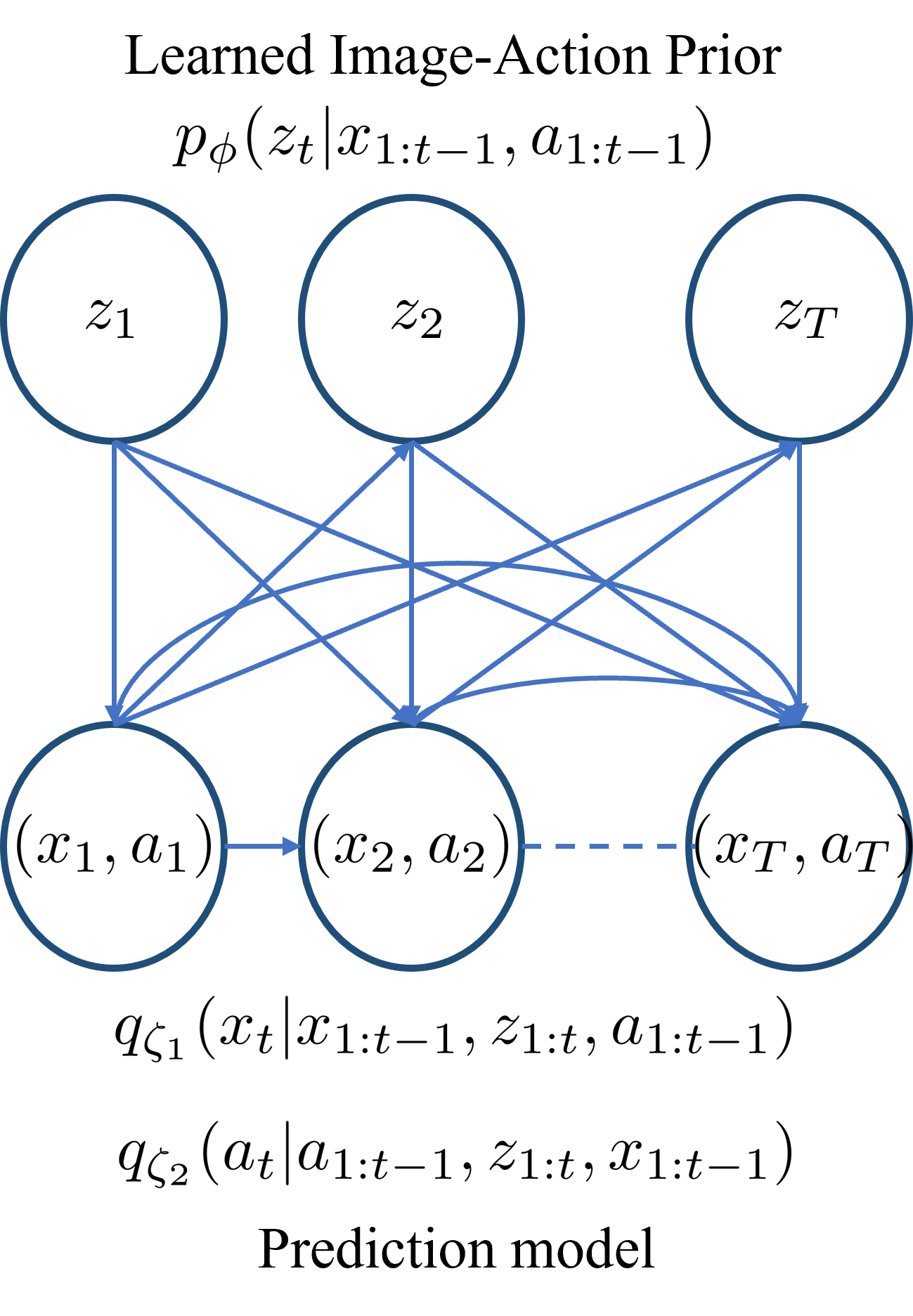
Video Generation with Learned Action Prior
Meenakshi Sarkar, Devansh Bhardwaj, Debasish Ghose
0
0
Stochastic video generation is particularly challenging when the camera is mounted on a moving platform, as camera motion interacts with observed image pixels, creating complex spatio-temporal dynamics and making the problem partially observable. Existing methods typically address this by focusing on raw pixel-level image reconstruction without explicitly modelling camera motion dynamics. We propose a solution by considering camera motion or action as part of the observed image state, modelling both image and action within a multi-modal learning framework. We introduce three models: Video Generation with Learning Action Prior (VG-LeAP) treats the image-action pair as an augmented state generated from a single latent stochastic process and uses variational inference to learn the image-action latent prior; Causal-LeAP, which establishes a causal relationship between action and the observed image frame at time $t$, learning an action prior conditioned on the observed image states; and RAFI, which integrates the augmented image-action state concept into flow matching with diffusion generative processes, demonstrating that this action-conditioned image generation concept can be extended to other diffusion-based models. We emphasize the importance of multi-modal training in partially observable video generation problems through detailed empirical studies on our new video action dataset, RoAM.
6/21/2024

ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Gabriel Sarch, Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, Katerina Fragkiadaki
0
0
Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
6/24/2024