Safe Deep Model-Based Reinforcement Learning with Lyapunov Functions
2405.16184
0
0

Abstract
Model-based Reinforcement Learning (MBRL) has shown many desirable properties for intelligent control tasks. However, satisfying safety and stability constraints during training and rollout remains an open question. We propose a new Model-based RL framework to enable efficient policy learning with unknown dynamics based on learning model predictive control (LMPC) framework with mathematically provable guarantees of stability. We introduce and explore a novel method for adding safety constraints for model-based RL during training and policy learning. The new stability-augmented framework consists of a neural-network-based learner that learns to construct a Lyapunov function, and a model-based RL agent to consistently complete the tasks while satisfying user-specified constraints given only sub-optimal demonstrations and sparse-cost feedback. We demonstrate the capability of the proposed framework through simulated experiments.
Create account to get full access
Overview
- This paper presents a novel approach for safe deep model-based reinforcement learning (MBRL) using Lyapunov functions.
- The proposed method ensures safety during the learning process by incorporating Lyapunov stability analysis into the MBRL framework.
- The authors demonstrate the effectiveness of their approach through experiments on various simulated environments.
Plain English Explanation
In the field of reinforcement learning (RL), agents are trained to make decisions that maximize a reward signal. However, in many real-world applications, it's crucial to ensure the safety of the agent's actions, especially during the learning process. This is where the concept of "safe reinforcement learning" comes into play.
The researchers in this paper Safe Deep Model-Based Reinforcement Learning with Lyapunov Functions have developed a new method that incorporates Lyapunov stability analysis into a deep model-based reinforcement learning (MBRL) framework. Lyapunov functions are a powerful mathematical tool used to analyze the stability of dynamic systems, and the authors have found a way to leverage this concept to ensure the safety of the RL agent during training.
The key idea is to learn a Lyapunov function that serves as a measure of the agent's "safety" or "stability" during the learning process. This Lyapunov function is then used to guide the agent's actions, ensuring that it stays within safe regions of the state space and avoids potentially dangerous situations. By doing this, the agent can learn effectively while still maintaining a high level of safety.
The researchers have demonstrated the effectiveness of their approach through experiments on various simulated environments, where the agent is able to learn optimal policies while consistently staying within safe bounds. This is a significant advancement in the field of safe reinforcement learning, as it allows for the development of RL systems that can be deployed in real-world applications with strict safety requirements.
Technical Explanation
The central idea of this paper is to incorporate Lyapunov stability analysis into a deep model-based reinforcement learning (MBRL) framework to ensure safety during the learning process. The authors propose a novel algorithm, called Safe Deep MBRL with Lyapunov Functions, which learns a Lyapunov function that serves as a measure of the agent's "safety" or "stability."
The algorithm consists of two main components: a model-based RL component that learns a dynamics model of the environment, and a Lyapunov function learning component that learns a Lyapunov function to guide the agent's actions. The Lyapunov function is used to constrain the agent's actions, ensuring that it stays within safe regions of the state space.
The authors evaluate their approach on several simulated environments, including a cart-pole system, a quadrotor, and a bipedal robot. The results demonstrate that the proposed method is able to learn optimal policies while consistently maintaining safety, outperforming baseline MBRL algorithms that do not incorporate Lyapunov stability analysis.
This work builds upon previous research on safe reinforcement learning and Lyapunov-based control. The authors' key contribution is the integration of these two concepts into a unified MBRL framework, which allows for the development of RL agents that can be deployed in real-world applications with strict safety requirements.
Critical Analysis
The proposed approach represents a significant advancement in the field of safe reinforcement learning, as it provides a principled way to incorporate safety guarantees into the learning process. The use of Lyapunov functions to guide the agent's actions is a particularly elegant solution, as it allows for the explicit modeling and enforcement of safety constraints.
However, the authors do note some limitations of their approach. Firstly, the method relies on the ability to learn an accurate Lyapunov function, which can be challenging in complex, high-dimensional environments. Additionally, the approach assumes that the environment dynamics can be accurately modeled, which may not always be the case in real-world applications.
Furthermore, the authors do not provide a formal analysis of the safety guarantees provided by their method. While the experimental results are promising, a more rigorous theoretical treatment of the safety properties would be valuable for building trust in the approach.
Another area for potential improvement is the scalability of the method. The authors' experiments are limited to relatively simple simulated environments, and it's unclear how well the approach would scale to larger, more complex problems. Exploring ways to improve the computational efficiency and scalability of the algorithm would be an important direction for future research.
Despite these limitations, the Safe Deep MBRL with Lyapunov Functions approach represents an important step forward in the field of safe reinforcement learning. The authors have demonstrated the feasibility of incorporating Lyapunov stability analysis into deep RL, and their work provides a solid foundation for further research and development in this area.
Conclusion
In this paper, the authors have presented a novel approach for safe deep model-based reinforcement learning using Lyapunov functions. By learning a Lyapunov function to guide the agent's actions, the proposed method is able to ensure safety during the learning process, while still allowing the agent to learn optimal policies.
The authors' experimental results demonstrate the effectiveness of their approach, and the integration of Lyapunov stability analysis into a deep RL framework represents a significant advancement in the field of safe reinforcement learning. This work paves the way for the development of RL systems that can be safely deployed in real-world applications with strict safety requirements.
While the method has some limitations, the authors have provided a solid foundation for further research and development in this area. Exploring ways to improve the scalability and theoretical guarantees of the approach, as well as applying it to more complex, real-world problems, are all important directions for future work.
Overall, the Safe Deep MBRL with Lyapunov Functions approach represents an important step forward in ensuring the safety and reliability of deep reinforcement learning systems, with significant potential for practical applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
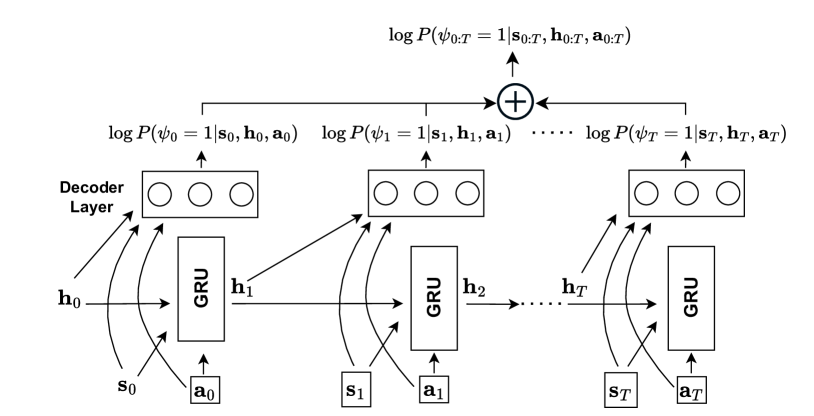
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024
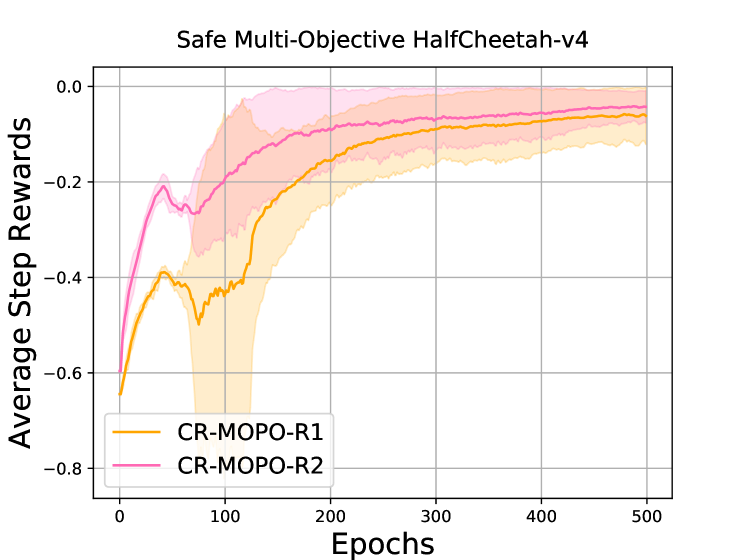
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024
🏅
Verified Safe Reinforcement Learning for Neural Network Dynamic Models
Junlin Wu, Huan Zhang, Yevgeniy Vorobeychik
0
0
Learning reliably safe autonomous control is one of the core problems in trustworthy autonomy. However, training a controller that can be formally verified to be safe remains a major challenge. We introduce a novel approach for learning verified safe control policies in nonlinear neural dynamical systems while maximizing overall performance. Our approach aims to achieve safety in the sense of finite-horizon reachability proofs, and is comprised of three key parts. The first is a novel curriculum learning scheme that iteratively increases the verified safe horizon. The second leverages the iterative nature of gradient-based learning to leverage incremental verification, reusing information from prior verification runs. Finally, we learn multiple verified initial-state-dependent controllers, an idea that is especially valuable for more complex domains where learning a single universal verified safe controller is extremely challenging. Our experiments on five safe control problems demonstrate that our trained controllers can achieve verified safety over horizons that are as much as an order of magnitude longer than state-of-the-art baselines, while maintaining high reward, as well as a perfect safety record over entire episodes.
5/28/2024
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
Udayan Mandal, Guy Amir, Haoze Wu, Ieva Daukantas, Fletcher Lee Newell, Umberto J. Ravaioli, Baoluo Meng, Michael Durling, Milan Ganai, Tobey Shim, Guy Katz, Clark Barrett
0
0
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the black box nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
5/24/2024