Safe Policy Exploration Improvement via Subgoals

0
Sign in to get full access
Overview
- Reinforcement learning (RL) can be used to train agents to solve complex tasks, but it often requires extensive exploration that can lead to unsafe or undesirable behavior.
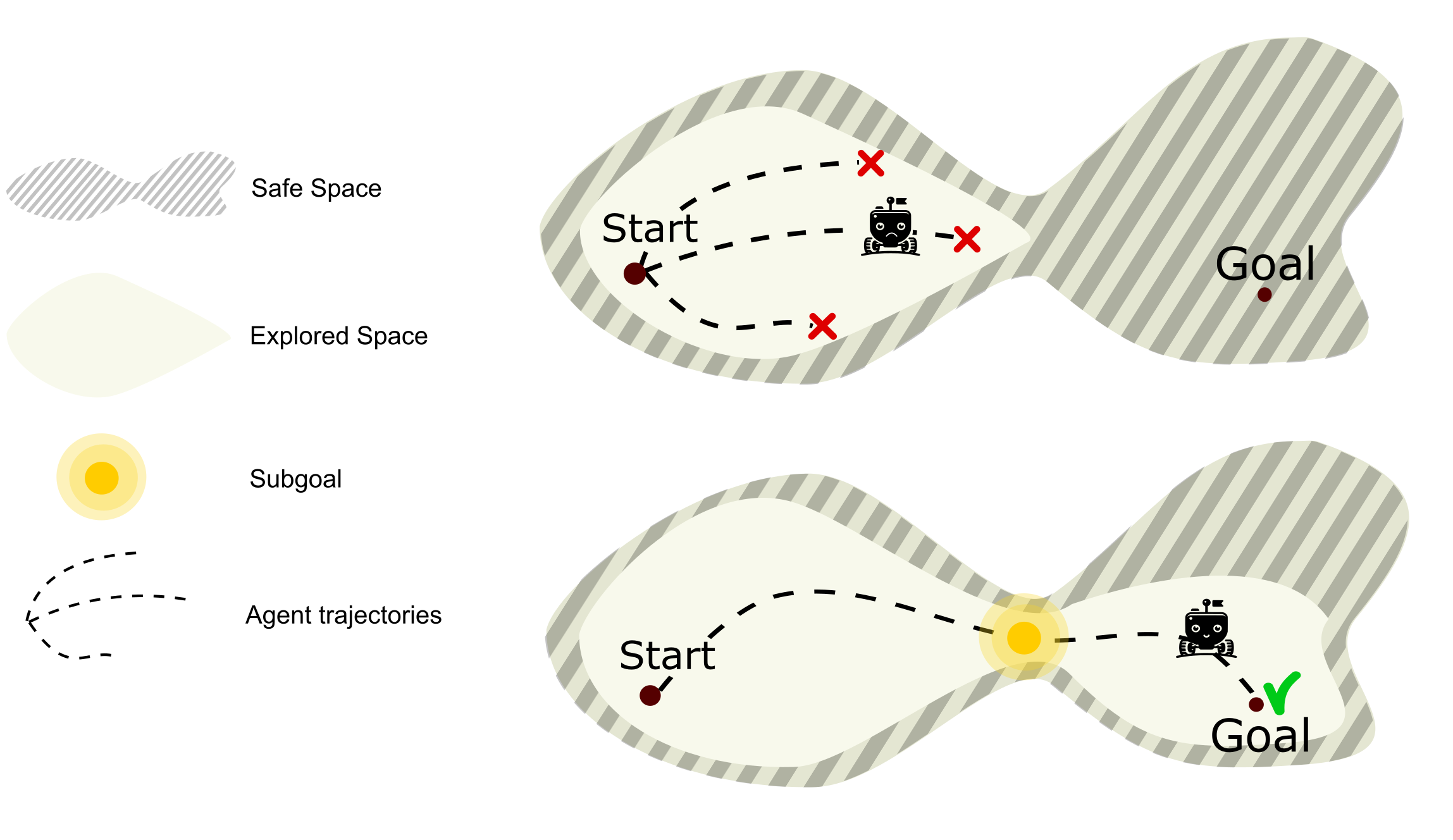
- This paper proposes a method called "Safe Policy Exploration Improvement via Subgoals" (SPEIS) to address this challenge by using subgoals to guide the exploration process and ensure safety.
- SPEIS works by decomposing the original task into a hierarchy of subtasks, each with its own reward function and safety constraints, which are then used to guide the exploration process and learn a safe policy.
Plain English Explanation
The paper introduces a new method called "Safe Policy Exploration Improvement via Subgoals" (SPEIS) to address the challenge of unsafe exploration in reinforcement learning (RL). RL is a powerful technique for training agents to solve complex tasks, but it often requires extensive exploration of the environment, which can lead to unsafe or undesirable behavior.
To address this, the SPEIS method decomposes the original task into a hierarchy of subtasks, each with its own reward function and safety constraints. This allows the agent to focus its exploration on the subtasks, which are easier to solve and have fewer safety concerns than the original task. By learning to solve these subtasks, the agent can gradually build up the skills and knowledge needed to tackle the full task in a safe and reliable way.
The key insight behind SPEIS is that breaking down a complex task into smaller, more manageable pieces can make it easier for the agent to learn a safe and effective policy. By having clear subgoals and safety constraints for each subtask, the agent can explore the environment more effectively and avoid getting stuck in unsafe or unproductive areas.
Technical Explanation
The SPEIS method works by decomposing the original reinforcement learning task into a hierarchical structure of subtasks, each with its own reward function and safety constraints. The agent is then trained to solve these subtasks in a safe and efficient manner, with the ultimate goal of learning a safe policy for the full task.
The method consists of several key components:
-
Subgoal Identification: The original task is broken down into a set of subtasks or subgoals, which represent intermediate steps towards the final goal. These subgoals are designed to be easier to solve and have fewer safety concerns than the original task.
-
Subgoal-based Exploration: The agent is trained to explore the environment in a way that focuses on achieving the current subgoal, rather than blindly exploring the full state space. This is done by modifying the agent's reward function to prioritize reaching the subgoal and avoiding unsafe states.
-
Safety Constraints: Each subtask is associated with a set of safety constraints, which the agent must satisfy in order to progress to the next subgoal. These constraints help to ensure that the agent's behavior remains safe and aligned with the overall goal of the task.
-
Hierarchical Policy Learning: The agent learns a separate policy for each subtask, which are then composed into a hierarchical policy that can be used to solve the full task. This approach allows the agent to build up its skills and knowledge in a gradual and structured way, rather than trying to learn the full task all at once.
The paper presents experimental results on several challenging reinforcement learning tasks, which demonstrate the effectiveness of the SPEIS method in improving the safety and efficiency of the exploration process, while still achieving high performance on the original task.
Critical Analysis
The SPEIS method represents a promising approach to addressing the challenge of unsafe exploration in reinforcement learning. By decomposing the original task into a hierarchy of subtasks, the method provides a structured way for the agent to explore the environment and learn a safe policy.
One potential limitation of the method is that the identification of appropriate subgoals and safety constraints may require significant domain-specific knowledge and intervention. The paper does not provide a fully automated way to generate these components, which could limit the method's applicability to a wider range of tasks.
Additionally, the hierarchical policy learning approach may introduce additional complexity and computational overhead, particularly as the number of subtasks increases. It would be interesting to see how the method scales to more complex and high-dimensional tasks, and whether there are ways to further streamline the policy learning process.
Overall, the SPEIS method represents an important step forward in the field of safe reinforcement learning, and the ideas and techniques presented in the paper could inspire further research and development in this area.
Conclusion
The "Safe Policy Exploration Improvement via Subgoals" (SPEIS) method introduced in this paper offers a promising approach to addressing the challenge of unsafe exploration in reinforcement learning. By decomposing the original task into a hierarchy of subtasks, each with its own reward function and safety constraints, SPEIS allows the agent to explore the environment more safely and effectively, while still achieving high performance on the full task.
The key insights of the SPEIS method, such as the use of subgoals to guide exploration and the incorporation of safety constraints, could have important implications for the development of more robust and reliable reinforcement learning systems. As the field of AI continues to advance, techniques like SPEIS will likely play an increasingly important role in ensuring that these systems can be deployed safely and reliably in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Safe Policy Exploration Improvement via Subgoals
Brian Angulo, Gregory Gorbov, Aleksandr Panov, Konstantin Yakovlev
Reinforcement learning is a widely used approach to autonomous navigation, showing potential in various tasks and robotic setups. Still, it often struggles to reach distant goals when safety constraints are imposed (e.g., the wheeled robot is prohibited from moving close to the obstacles). One of the main reasons for poor performance in such setups, which is common in practice, is that the need to respect the safety constraints degrades the exploration capabilities of an RL agent. To this end, we introduce a novel learnable algorithm that is based on decomposing the initial problem into smaller sub-problems via intermediate goals, on the one hand, and respects the limit of the cumulative safety constraints, on the other hand -- SPEIS(Safe Policy Exploration Improvement via Subgoals). It comprises the two coupled policies trained end-to-end: subgoal and safe. The subgoal policy is trained to generate the subgoal based on the transitions from the buffer of the safe (main) policy that helps the safe policy to reach distant goals. Simultaneously, the safe policy maximizes its rewards while attempting not to violate the limit of the cumulative safety constraints, thus providing a certain level of safety. We evaluate SPEIS in a wide range of challenging (simulated) environments that involve different types of robots in two different environments: autonomous vehicles from the POLAMP environment and car, point, doggo, and sweep from the safety-gym environment. We demonstrate that our method consistently outperforms state-of-the-art competitors and can significantly reduce the collision rate while maintaining high success rates (higher by 80% compared to the best-performing methods).
Read more8/27/2024
🏅
0
New!Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Jonas Gunster, Puze Liu, Jan Peters, Davide Tateo
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Read more9/19/2024

0
Robots that Suggest Safe Alternatives
Hyun Joe Jeong, Andrea Bajcsy
Goal-conditioned policies, such as those learned via imitation learning, provide an easy way for humans to influence what tasks robots accomplish. However, these robot policies are not guaranteed to execute safely or to succeed when faced with out-of-distribution requests. In this work, we enable robots to know when they can confidently execute a user's desired goal, and automatically suggest safe alternatives when they cannot. Our approach is inspired by control-theoretic safety filtering, wherein a safety filter minimally adjusts a robot's candidate action to be safe. Our key idea is to pose alternative suggestion as a safe control problem in goal space, rather than in action space. Offline, we use reachability analysis to compute a goal-parameterized reach-avoid value network which quantifies the safety and liveness of the robot's pre-trained policy. Online, our robot uses the reach-avoid value network as a safety filter, monitoring the human's given goal and actively suggesting alternatives that are similar but meet the safety specification. We demonstrate our Safe ALTernatives (SALT) framework in simulation experiments with indoor navigation and Franka Panda tabletop manipulation, and with both discrete and continuous goal representations. We find that SALT is able to learn to predict successful and failed closed-loop executions, is a less pessimistic monitor than open-loop uncertainty quantification, and proposes alternatives that consistently align with those people find acceptable.
Read more9/17/2024

0
Enhancing Efficiency of Safe Reinforcement Learning via Sample Manipulation
Shangding Gu, Laixi Shi, Yuhao Ding, Alois Knoll, Costas Spanos, Adam Wierman, Ming Jin
Safe reinforcement learning (RL) is crucial for deploying RL agents in real-world applications, as it aims to maximize long-term rewards while satisfying safety constraints. However, safe RL often suffers from sample inefficiency, requiring extensive interactions with the environment to learn a safe policy. We propose Efficient Safe Policy Optimization (ESPO), a novel approach that enhances the efficiency of safe RL through sample manipulation. ESPO employs an optimization framework with three modes: maximizing rewards, minimizing costs, and balancing the trade-off between the two. By dynamically adjusting the sampling process based on the observed conflict between reward and safety gradients, ESPO theoretically guarantees convergence, optimization stability, and improved sample complexity bounds. Experiments on the Safety-MuJoCo and Omnisafe benchmarks demonstrate that ESPO significantly outperforms existing primal-based and primal-dual-based baselines in terms of reward maximization and constraint satisfaction. Moreover, ESPO achieves substantial gains in sample efficiency, requiring 25--29% fewer samples than baselines, and reduces training time by 21--38%.
Read more6/3/2024