Safety in Graph Machine Learning: Threats and Safeguards

0

Sign in to get full access
Overview
- This paper examines the safety and security challenges in the field of Graph Machine Learning (Graph ML).
- It discusses various threats and vulnerabilities that can arise in Graph ML systems, and proposes safeguards to address these issues.
- The paper covers topics such as reliability, generalizability, and confidentiality in the context of Graph ML.
Plain English Explanation
Graph Machine Learning (Graph ML) is a powerful technique that allows computers to analyze and understand the relationships between different entities, like people, products, or locations. Just like other machine learning methods, Graph ML models can be vulnerable to various threats and safety issues.
This paper explores some of the key safety and security concerns in Graph ML. For example, a Graph ML model might not work as expected when faced with new or unusual data, which could lead to unreliable or biased results. The model could also struggle to generalize its insights to different situations, limiting its usefulness. Additionally, the sensitive data used to train Graph ML models could be at risk of being compromised, threatening the confidentiality of the information.
To address these problems, the paper suggests several safeguards and strategies. For instance, the researchers recommend testing Graph ML models extensively to ensure they can handle a wide range of input data reliably. They also suggest techniques to improve the models' ability to generalize their learnings to new contexts. Finally, the paper discusses ways to protect the privacy and security of the data used to train Graph ML systems.
By understanding and addressing the safety and security challenges in Graph ML, researchers and developers can help ensure that these powerful technologies are used responsibly and effectively, delivering valuable insights while mitigating potential risks.
Technical Explanation
The paper begins by providing an overview of the fundamentals of Graph Machine Learning (Graph ML). Graph ML is a machine learning technique that leverages the relationships and connections between different entities, represented as a graph data structure. This approach can be particularly useful for tasks like recommendation systems, fraud detection, and social network analysis.
However, the authors note that like other machine learning methods, Graph ML models can be vulnerable to various safety and security threats. The paper then delves into the key challenges in this area, including:
-
Reliability: Graph ML models may not perform consistently or as expected when faced with new or unusual data, leading to unreliable or biased results. The paper discusses techniques to enhance the robustness and stability of Graph ML systems.
-
Generalizability: Graph ML models may struggle to generalize their learnings to different contexts or domains, limiting their usefulness. The paper explores approaches to improve the generalization capabilities of Graph ML models.
-
Confidentiality: The sensitive data used to train Graph ML models could be at risk of being compromised, threatening the privacy and security of the information. The paper suggests safeguards to protect the confidentiality of the data used in Graph ML.
To address these challenges, the paper proposes various safeguards and strategies, including:
- Systematic testing and evaluation procedures to ensure the reliability and robustness of Graph ML models.
- Techniques to enhance the generalization capabilities of Graph ML models, such as data augmentation and transfer learning.
- Privacy-preserving methods to protect the confidentiality of the data used in Graph ML, including secure multi-party computation and differential privacy.
By implementing these safeguards, the authors aim to help researchers and developers create safer and more secure Graph ML systems that can deliver valuable insights while mitigating potential risks.
Critical Analysis
The paper provides a comprehensive overview of the safety and security challenges in Graph Machine Learning, highlighting key issues such as reliability, generalizability, and confidentiality. The proposed safeguards and strategies offer a solid foundation for addressing these concerns.
However, the paper does not delve into the practical implementation details of these safeguards, which could be a valuable addition for researchers and developers looking to apply these techniques in their work. Further research may be needed to explore the effectiveness and feasibility of the proposed approaches in real-world Graph ML applications.
Additionally, the paper could have discussed the trade-offs and potential limitations of the suggested safeguards. For example, some privacy-preserving techniques may come at the cost of reduced model performance or increased computational overhead. Acknowledging and addressing such trade-offs would help readers better understand the practical implications of implementing the proposed solutions.
Overall, the paper serves as a valuable resource for understanding the safety and security landscape in Graph Machine Learning, and the proposed safeguards provide a solid starting point for further research and development in this field.
Conclusion
This paper addresses the critical issue of safety and security in Graph Machine Learning, a rapidly growing field with various applications. By identifying key challenges related to reliability, generalizability, and confidentiality, the authors have laid the groundwork for developing more robust and secure Graph ML systems.
The proposed safeguards, such as systematic testing, generalization techniques, and privacy-preserving methods, offer promising avenues for researchers and developers to enhance the safety and trustworthiness of Graph ML. As the adoption of these technologies continues to grow, addressing these safety and security concerns will be essential to ensure the responsible and effective use of Graph ML in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Safety in Graph Machine Learning: Threats and Safeguards
Song Wang, Yushun Dong, Binchi Zhang, Zihan Chen, Xingbo Fu, Yinhan He, Cong Shen, Chuxu Zhang, Nitesh V. Chawla, Jundong Li
Graph Machine Learning (Graph ML) has witnessed substantial advancements in recent years. With their remarkable ability to process graph-structured data, Graph ML techniques have been extensively utilized across diverse applications, including critical domains like finance, healthcare, and transportation. Despite their societal benefits, recent research highlights significant safety concerns associated with the widespread use of Graph ML models. Lacking safety-focused designs, these models can produce unreliable predictions, demonstrate poor generalizability, and compromise data confidentiality. In high-stakes scenarios such as financial fraud detection, these vulnerabilities could jeopardize both individuals and society at large. Therefore, it is imperative to prioritize the development of safety-oriented Graph ML models to mitigate these risks and enhance public confidence in their applications. In this survey paper, we explore three critical aspects vital for enhancing safety in Graph ML: reliability, generalizability, and confidentiality. We categorize and analyze threats to each aspect under three headings: model threats, data threats, and attack threats. This novel taxonomy guides our review of effective strategies to protect against these threats. Our systematic review lays a groundwork for future research aimed at developing practical, safety-centered Graph ML models. Furthermore, we highlight the significance of safe Graph ML practices and suggest promising avenues for further investigation in this crucial area.
Read more5/21/2024

0
AI Safety in Generative AI Large Language Models: A Survey
Jaymari Chua, Yun Li, Shiyi Yang, Chen Wang, Lina Yao
Large Language Model (LLMs) such as ChatGPT that exhibit generative AI capabilities are facing accelerated adoption and innovation. The increased presence of Generative AI (GAI) inevitably raises concerns about the risks and safety associated with these models. This article provides an up-to-date survey of recent trends in AI safety research of GAI-LLMs from a computer scientist's perspective: specific and technical. In this survey, we explore the background and motivation for the identified harms and risks in the context of LLMs being generative language models; our survey differentiates by emphasising the need for unified theories of the distinct safety challenges in the research development and applications of LLMs. We start our discussion with a concise introduction to the workings of LLMs, supported by relevant literature. Then we discuss earlier research that has pointed out the fundamental constraints of generative models, or lack of understanding thereof (e.g., performance and safety trade-offs as LLMs scale in number of parameters). We provide a sufficient coverage of LLM alignment -- delving into various approaches, contending methods and present challenges associated with aligning LLMs with human preferences. By highlighting the gaps in the literature and possible implementation oversights, our aim is to create a comprehensive analysis that provides insights for addressing AI safety in LLMs and encourages the development of aligned and secure models. We conclude our survey by discussing future directions of LLMs for AI safety, offering insights into ongoing research in this critical area.
Read more7/29/2024
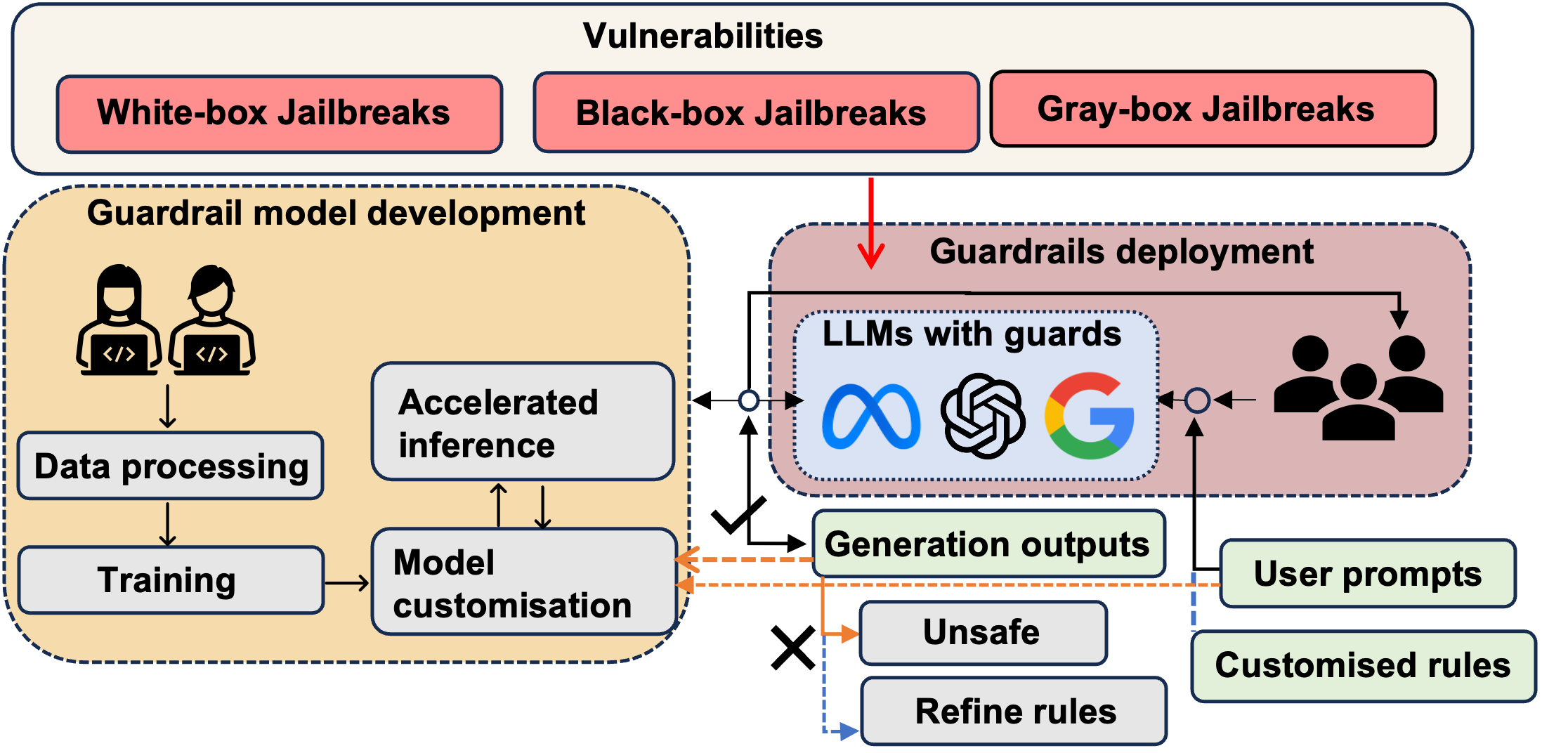
0
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Read more6/6/2024
💬
0
Safety of Multimodal Large Language Models on Images and Texts
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, Yu Qiao
Attracted by the impressive power of Multimodal Large Language Models (MLLMs), the public is increasingly utilizing them to improve the efficiency of daily work. Nonetheless, the vulnerabilities of MLLMs to unsafe instructions bring huge safety risks when these models are deployed in real-world scenarios. In this paper, we systematically survey current efforts on the evaluation, attack, and defense of MLLMs' safety on images and text. We begin with introducing the overview of MLLMs on images and text and understanding of safety, which helps researchers know the detailed scope of our survey. Then, we review the evaluation datasets and metrics for measuring the safety of MLLMs. Next, we comprehensively present attack and defense techniques related to MLLMs' safety. Finally, we analyze several unsolved issues and discuss promising research directions. The latest papers are continually collected at https://github.com/isXinLiu/MLLM-Safety-Collection.
Read more6/21/2024