Self-Supervised Singing Voice Pre-Training towards Speech-to-Singing Conversion

0

Sign in to get full access
Overview
- This paper explores a self-supervised pre-training approach for singing voice conversion, which aims to transform normal speech into expressive singing.
- The researchers leverage unlabeled singing voice data to pre-train a model, which can then be fine-tuned for speech-to-singing conversion tasks.
- This pre-training strategy aims to improve the quality and expressiveness of the generated singing voice, compared to previous approaches that relied solely on speech data.
Plain English Explanation
The paper discusses a new technique for converting regular speech into singing. The key idea is to leverage diverse semantic-based audio pretrained models - the model is first trained on a large amount of singing voice data in a self-supervised way, without needing any labels or annotations. This pre-training allows the model to learn the characteristics and expressiveness of singing voices.
After this initial pre-training, the model can then be fine-tuned on a smaller dataset of paired speech and singing samples to convert normal speech into singing. The researchers found that this approach produces more realistic and high-fidelity singing voices compared to models trained only on speech data.
The benefit of this technique is that it can generate singing voices that sound more natural and expressive, without requiring a large labeled dataset of speech-to-singing pairs. This could be useful for applications like singing voice transformation or music production.
Technical Explanation
The paper proposes a self-supervised pre-training approach for speech-to-singing conversion. The key idea is to leverage a large corpus of unlabeled singing voice data to pre-train a neural network model, which can then be fine-tuned on a smaller dataset of paired speech and singing samples.
The pre-training process involves training the model to perform a masked prediction task on the singing voice data, similar to techniques used in language models like BERT. This allows the model to learn the underlying structure and expressiveness of singing voices in a self-supervised manner.
After pre-training, the model is fine-tuned on a speech-to-singing dataset using an adversarial training scheme. This involves a generator model that converts speech to singing, and a discriminator model that tries to distinguish real singing from the generated samples. The generator is trained to fool the discriminator, leading to more realistic and expressive singing voice outputs.
The researchers evaluate their approach on several singing voice conversion benchmarks, and find that it outperforms previous methods that relied solely on speech data for training. The self-supervised pre-training allows the model to better capture the nuances and expressiveness of singing, leading to higher quality and more natural-sounding results.
Critical Analysis
The paper presents a novel and promising approach for improving speech-to-singing conversion, but there are a few potential limitations and areas for further research:
-
The self-supervised pre-training assumes access to a large corpus of unlabeled singing voice data, which may not be readily available for all languages or musical styles. Techniques for robust singing voice transcription could help address this data challenge.
-
While the adversarial fine-tuning scheme helps improve the realism of the generated singing, the model may still struggle with capturing the full expressiveness and dynamics of human singing performance. Iterative refinement approaches could potentially help address this.
-
The paper focuses on objective metrics like audio quality and similarity to real singing, but does not thoroughly evaluate the perceived naturalness and artistic merit of the generated singing voices. Further user studies would be valuable to assess the real-world usability of the approach.
Overall, the self-supervised pre-training strategy shows promise, but continued research is needed to address the remaining challenges in achieving high-fidelity and expressive speech-to-singing conversion.
Conclusion
This paper presents a novel approach for speech-to-singing conversion that leverages self-supervised pre-training on singing voice data. By learning the underlying structure and expressiveness of singing voices in a data-efficient manner, the model is able to generate more realistic and natural-sounding singing from normal speech.
The proposed technique represents an important step forward in enabling high-quality singing voice transformation applications, which could have diverse use cases in music production, interactive entertainment, and assistive technologies. Further research is needed to address remaining challenges, but this work demonstrates the value of leveraging self-supervised pre-training for complex audio generation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Singing Voice Pre-Training towards Speech-to-Singing Conversion
Ruiqi Li, Rongjie Huang, Yongqi Wang, Zhiqing Hong, Zhou Zhao
Speech-to-singing voice conversion (STS) task always suffers from data scarcity, because it requires paired speech and singing data. Compounding this issue are the challenges of content-pitch alignment and the suboptimal quality of generated outputs, presenting significant hurdles in STS research. This paper presents SVPT, an STS approach boosted by a self-supervised singing voice pre-training model. We leverage spoken language model techniques to tackle the rhythm alignment problem and the in-context learning capability to achieve zero-shot conversion. We adopt discrete-unit random resampling and pitch corruption strategies, enabling training with unpaired singing data and thus mitigating the issue of data scarcity. SVPT also serves as an effective backbone for singing voice synthesis (SVS), offering insights into scaling up SVS models. Experimental results indicate that SVPT delivers notable improvements in both STS and SVS endeavors. Audio samples are available at https://speech2sing.github.io.
Read more6/5/2024
0
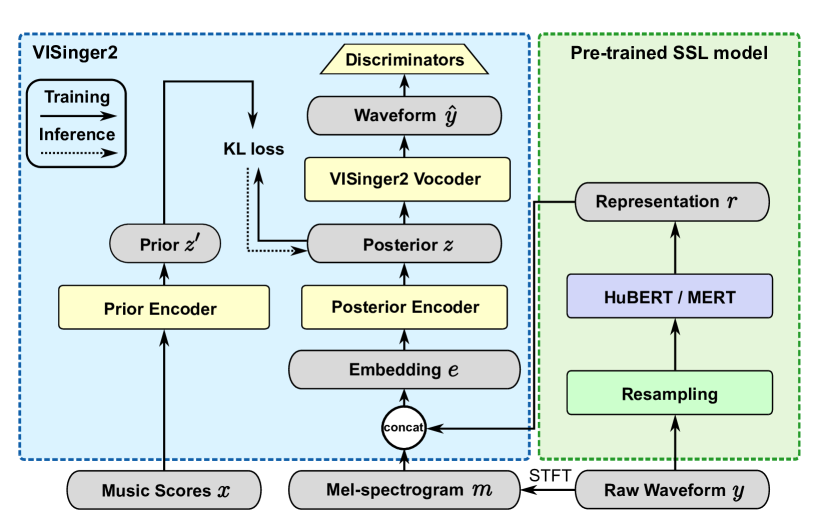
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024
🧪
0
SPA-SVC: Self-supervised Pitch Augmentation for Singing Voice Conversion
Bingsong Bai, Fengping Wang, Yingming Gao, Ya Li
Diffusion-based singing voice conversion (SVC) models have shown better synthesis quality compared to traditional methods. However, in cross-domain SVC scenarios, where there is a significant disparity in pitch between the source and target voice domains, the models tend to generate audios with hoarseness, posing challenges in achieving high-quality vocal outputs. Therefore, in this paper, we propose a Self-supervised Pitch Augmentation method for Singing Voice Conversion (SPA-SVC), which can enhance the voice quality in SVC tasks without requiring additional data or increasing model parameters. We innovatively introduce a cycle pitch shifting training strategy and Structural Similarity Index (SSIM) loss into our SVC model, effectively enhancing its performance. Experimental results on the public singing datasets M4Singer indicate that our proposed method significantly improves model performance in both general SVC scenarios and particularly in cross-domain SVC scenarios.
Read more6/12/2024

0
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Wangjin Zhou, Fengrun Zhang, Yiming Liu, Wenhao Guan, Yi Zhao, He Qu
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Read more9/14/2024