Sample-efficient Imitative Multi-token Decision Transformer for Generalizable Real World Driving

0

Sign in to get full access
Overview
- This paper presents a novel decision transformer model for sample-efficient imitative learning in real-world driving scenarios.
- The model, called the Multi-token Decision Transformer (MTDT), is able to generate multi-token driving decisions that can be directly executed by a vehicle control system.
- The researchers demonstrate that MTDT can learn driving policies from relatively small datasets and generalize to unseen environments, outperforming existing imitation learning approaches.
Plain English Explanation
The researchers have developed a new machine learning model that can learn how to drive a car by observing and imitating expert human drivers. This model, called the Multi-token Decision Transformer (MTDT), is able to generate not just a single driving decision (e.g., steer left, accelerate), but a sequence of decisions that can be directly executed by a self-driving car.
Traditionally, imitation learning approaches for driving have struggled to generalize beyond the specific driving scenarios seen during training. However, the MTDT model is designed to be more sample-efficient, meaning it can learn effective driving policies from relatively small datasets. This is an important capability, as collecting large amounts of driving data can be time-consuming and expensive.
The researchers show that MTDT outperforms other imitation learning methods on a variety of real-world driving tasks, demonstrating its ability to generalize to unseen environments. This suggests the model could be a valuable tool for developing more robust and capable self-driving car systems.
Technical Explanation
The core innovation of the MTDT model is its ability to generate multi-token driving decisions in an autoregressive manner. Rather than predicting a single driving action (e.g., steering angle, throttle) at each time step, the model generates a sequence of tokens that correspond to a series of interconnected driving decisions.
This multi-token approach allows the model to capture the inherent temporality and interdependence of driving behavior, as opposed to treating each decision in isolation. The researchers utilize a Transformer-based architecture to enable this multi-token prediction, drawing on the model's ability to effectively model long-range dependencies.
Through extensive experimentation on real-world driving datasets, the researchers demonstrate that MTDT is able to learn driving policies that generalize to novel environments, outperforming single-token imitation learning baselines. They attribute this success to the model's ability to capture the rich, sequential nature of driving behavior, as well as its sample-efficient learning capabilities.
Critical Analysis
The researchers acknowledge several limitations of their work that warrant further investigation. For example, the MTDT model is currently trained on relatively small driving datasets, and its performance on large-scale, diverse driving scenarios remains to be explored.
Additionally, the paper does not delve into the interpretability of the model's decision-making process, which could be an important consideration for the deployment of such systems in real-world settings. Explaining the reasoning behind the model's multi-token driving decisions could help build trust and acceptance among end-users.
Further research could also explore the integration of the MTDT model with other components of a self-driving car system, such as perception and planning modules, to create a more holistic and robust autonomous driving solution.
Conclusion
The Multi-token Decision Transformer presented in this paper represents a significant advancement in imitation learning for real-world driving. By modeling the inherent temporality and interdependence of driving behavior, the MTDT model is able to learn effective driving policies from relatively small datasets and generalize to unseen environments.
This research highlights the potential of sample-efficient, multi-token approaches to enhance the capabilities and robustness of self-driving car systems. As the field of autonomous driving continues to evolve, innovations like the MTDT model could play a crucial role in [accelerating the development and deployment of more capable and generalizable self-driving technologies](https://aimodels.fyi/papers/arxiv/dreureka-language-model-guided-sim-to-real).
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sample-efficient Imitative Multi-token Decision Transformer for Generalizable Real World Driving
Hang Zhou, Dan Xu, Yiding Ji
Reinforcement learning via sequence modeling has shown remarkable promise in autonomous systems, harnessing the power of offline datasets to make informed decisions in simulated environments. However, the full potential of such methods in complex dynamic environments remain to be discovered. In autonomous driving domain, learning-based agents face significant challenges when transferring knowledge from simulated to real-world settings and the performance is also significantly impacted by data distribution shift. To address these issue, we propose Sample-efficient Imitative Multi-token Decision Transformer (SimDT). SimDT introduces multi-token prediction, imitative online learning and prioritized experience replay to Decision Transformer. The performance is evaluated through empirical experiments and results exceed popular imitation and reinforcement learning algorithms on Waymax benchmark.
Read more7/4/2024
0
SMART: Scalable Multi-agent Real-time Simulation via Next-token Prediction
Wei Wu, Xiaoxin Feng, Ziyan Gao, Yuheng Kan
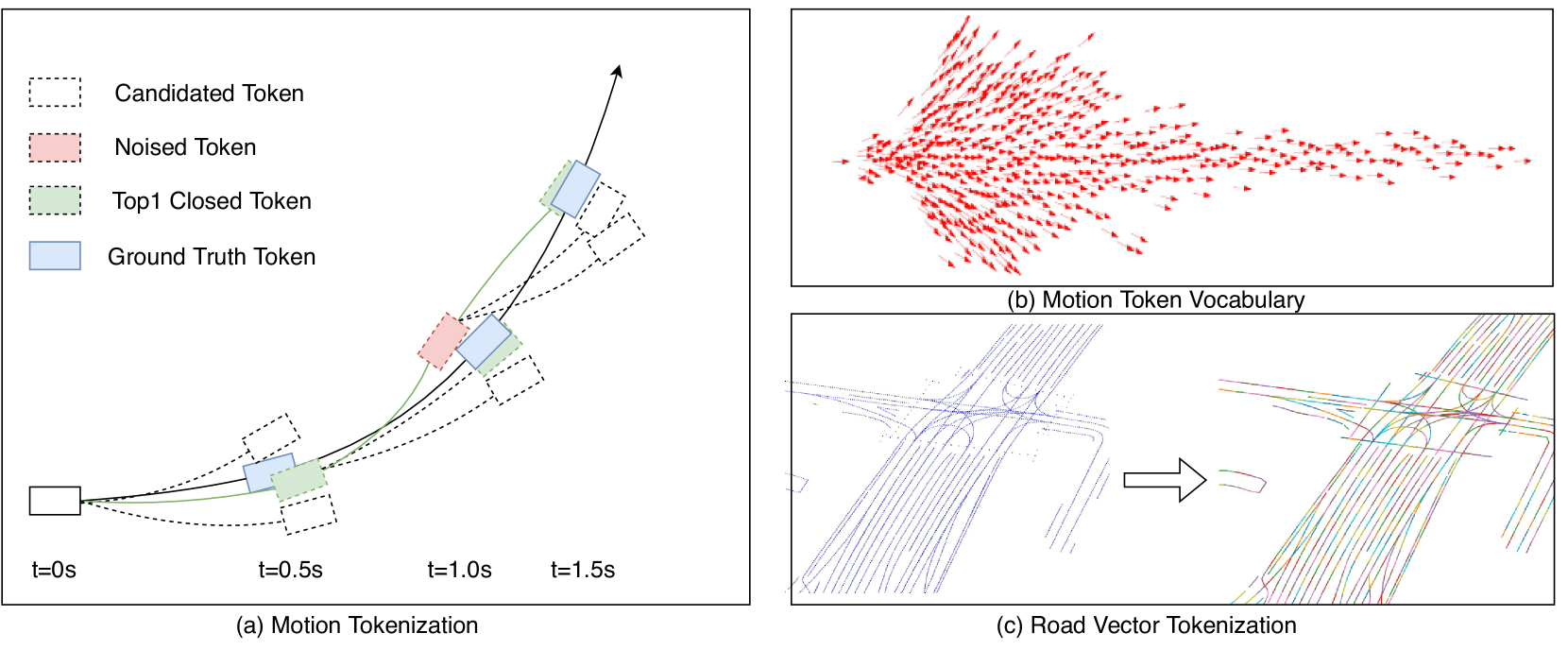
Data-driven autonomous driving motion generation tasks are frequently impacted by the limitations of dataset size and the domain gap between datasets, which precludes their extensive application in real-world scenarios. To address this issue, we introduce SMART, a novel autonomous driving motion generation paradigm that models vectorized map and agent trajectory data into discrete sequence tokens. These tokens are then processed through a decoder-only transformer architecture to train for the next token prediction task across spatial-temporal series. This GPT-style method allows the model to learn the motion distribution in real driving scenarios. SMART achieves state-of-the-art performance across most of the metrics on the generative Sim Agents challenge, ranking 1st on the leaderboards of Waymo Open Motion Dataset (WOMD), demonstrating remarkable inference speed. Moreover, SMART represents the generative model in the autonomous driving motion domain, exhibiting zero-shot generalization capabilities: Using only the NuPlan dataset for training and WOMD for validation, SMART achieved a competitive score of 0.71 on the Sim Agents challenge. Lastly, we have collected over 1 billion motion tokens from multiple datasets, validating the model's scalability. These results suggest that SMART has initially emulated two important properties: scalability and zero-shot generalization, and preliminarily meets the needs of large-scale real-time simulation applications. We have released all the code to promote the exploration of models for motion generation in the autonomous driving field.
Read more5/27/2024
0
Trajeglish: Traffic Modeling as Next-Token Prediction
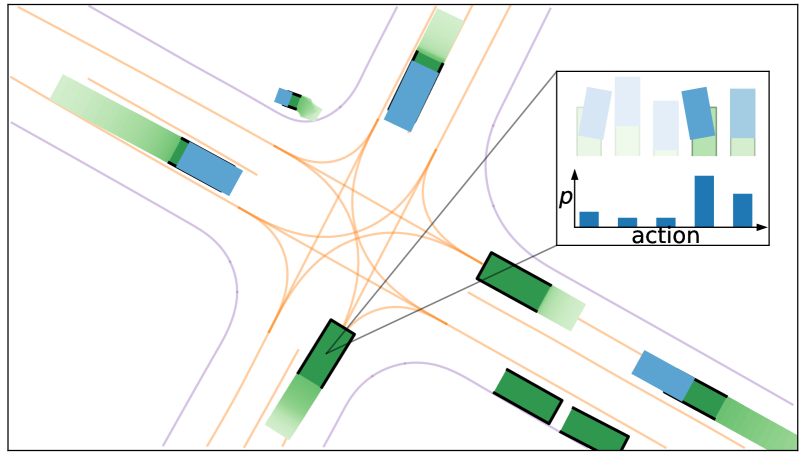
Jonah Philion, Xue Bin Peng, Sanja Fidler
A longstanding challenge for self-driving development is simulating dynamic driving scenarios seeded from recorded driving logs. In pursuit of this functionality, we apply tools from discrete sequence modeling to model how vehicles, pedestrians and cyclists interact in driving scenarios. Using a simple data-driven tokenization scheme, we discretize trajectories to centimeter-level resolution using a small vocabulary. We then model the multi-agent sequence of discrete motion tokens with a GPT-like encoder-decoder that is autoregressive in time and takes into account intra-timestep interaction between agents. Scenarios sampled from our model exhibit state-of-the-art realism; our model tops the Waymo Sim Agents Benchmark, surpassing prior work along the realism meta metric by 3.3% and along the interaction metric by 9.9%. We ablate our modeling choices in full autonomy and partial autonomy settings, and show that the representations learned by our model can quickly be adapted to improve performance on nuScenes. We additionally evaluate the scalability of our model with respect to parameter count and dataset size, and use density estimates from our model to quantify the saliency of context length and intra-timestep interaction for the traffic modeling task.
Read more4/16/2024
0
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
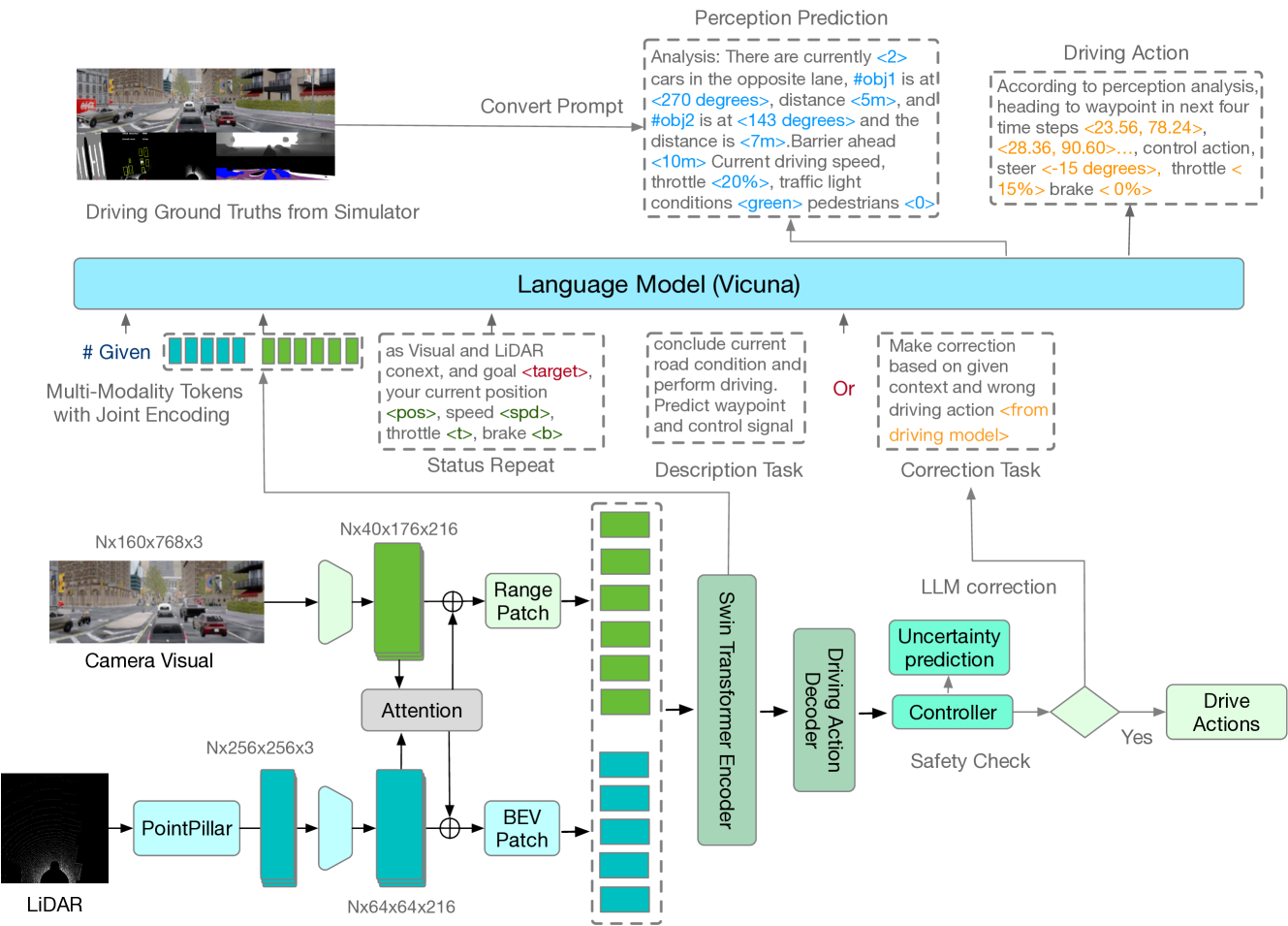
Yiqun Duan, Qiang Zhang, Renjing Xu
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
Read more7/30/2024