On scalable oversight with weak LLMs judging strong LLMs

0

Sign in to get full access
Overview
- Explores using weaker language models to oversee and judge stronger language models.
- Aims to develop scalable oversight approaches for large language models (LLMs).
- Proposes a framework where a weaker LLM evaluates the outputs of a stronger LLM.
Plain English Explanation
The paper investigates using less powerful AI language models to monitor and assess more advanced language models. The goal is to create a scalable system for overseeing powerful AI systems, where a simpler model can judge the outputs of a more complex one.
The key idea is to have a "weak" language model evaluate the results generated by a "strong" language model. This could allow for more widespread oversight and alignment of large language models, without requiring human judges for every interaction.
Technical Explanation
The paper proposes a framework where a weaker language model is used to oversee and evaluate the outputs of a more powerful language model. The weaker model acts as a judge, assessing the quality, safety, and alignment of the stronger model's responses.
The authors explore different approaches for training and deploying these "weak judge" models, including fine-tuning on datasets of human judgments and adversarial training. They also investigate ways to make the judging process efficient and scalable, such as having the judge model focus only on high-stakes or high-risk outputs.
Through experiments, the researchers demonstrate that weaker language models can effectively identify issues in the outputs of stronger models, including safety violations, factual inaccuracies, and alignment problems. This suggests that scalable oversight of advanced language models may be feasible using this approach.
Critical Analysis
The paper acknowledges several limitations and areas for further research. One key concern is the potential for misalignment between the weak judge model and human values or preferences. There is a risk that the judge model may itself be biased or flawed, leading to incorrect assessments of the stronger model.
Additionally, the researchers note that the performance of the weak judge model is heavily dependent on the quality and coverage of the training data used. Ensuring comprehensive and unbiased datasets for training the judge model is crucial but challenging in practice.
Further research is needed to explore the robustness of this approach, its scalability to real-world deployment, and ways to ensure the judge model's alignment with human values and objectives.
Conclusion
This paper presents a promising approach to scalable oversight of large language models, using weaker models to judge the outputs of stronger ones. By leveraging the capabilities of less powerful AI systems, it may be possible to develop more widespread and efficient monitoring of advanced language models, helping to ensure their safety and alignment.
However, the research also highlights important challenges that need to be addressed, such as ensuring the judge model's own reliability and alignment. Continued exploration of this approach, along with other oversight mechanisms, will be crucial as language models become increasingly powerful and influential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On scalable oversight with weak LLMs judging strong LLMs
Zachary Kenton, Noah Y. Siegel, J'anos Kram'ar, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D. Goodman, Rohin Shah
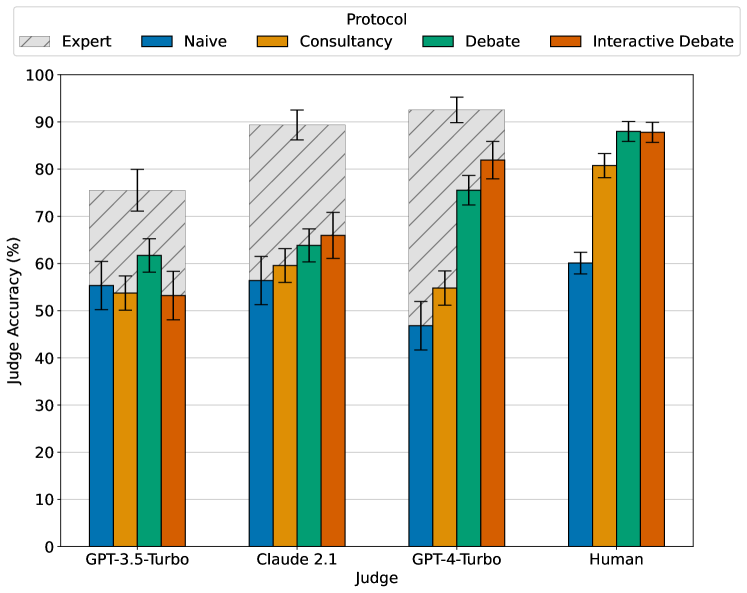
Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Read more7/15/2024
0
Debating with More Persuasive LLMs Leads to More Truthful Answers
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktaschel, Ethan Perez
Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Read more7/29/2024

0
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
Read more6/19/2024

0
DebateQA: Evaluating Question Answering on Debatable Knowledge
Rongwu Xu, Xuan Qi, Zehan Qi, Wei Xu, Zhijiang Guo
The rise of large language models (LLMs) has enabled us to seek answers to inherently debatable questions on LLM chatbots, necessitating a reliable way to evaluate their ability. However, traditional QA benchmarks assume fixed answers are inadequate for this purpose. To address this, we introduce DebateQA, a dataset of 2,941 debatable questions, each accompanied by multiple human-annotated partial answers that capture a variety of perspectives. We develop two metrics: Perspective Diversity, which evaluates the comprehensiveness of perspectives, and Dispute Awareness, which assesses if the LLM acknowledges the question's debatable nature. Experiments demonstrate that both metrics align with human preferences and are stable across different underlying models. Using DebateQA with two metrics, we assess 12 popular LLMs and retrieval-augmented generation methods. Our findings reveal that while LLMs generally excel at recognizing debatable issues, their ability to provide comprehensive answers encompassing diverse perspectives varies considerably.
Read more8/6/2024