Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation

0

Sign in to get full access
Overview
- This paper explores scaling diffusion policy models in transformers to 1 billion parameters for robotic manipulation tasks.
- Diffusion policy models are a type of generative model that can learn complex policies from data.
- Scaling these models to larger sizes can improve their performance on challenging robotic manipulation problems.
Plain English Explanation
The researchers in this paper wanted to see if they could take a type of machine learning model called a "diffusion policy model" and make it much larger, with 1 billion parameters. Diffusion policy models are a kind of generative model that can learn complex skills or behaviors from data, like how to manipulate objects in the real world.
By scaling up these models to a very large size with 1 billion parameters, the researchers hoped to improve the models' performance on challenging robotic manipulation tasks. Robotic manipulation is the process of getting a robot to interact with and physically move objects, which is an important capability for many real-world applications.
The core idea is that bigger machine learning models often perform better on difficult problems, so the researchers wanted to see if they could take this type of policy model and scale it up significantly to get better results.
Technical Explanation
The paper explores scaling diffusion policy models in transformer architectures to 1 billion parameters for robotic manipulation tasks. Diffusion policy models are a type of generative policy model that can learn complex behaviors from data, making them well-suited for challenging robot manipulation problems.
The researchers trained these large 1 billion parameter diffusion policy models using a transformer-based architecture. Transformers are a type of neural network architecture that has shown impressive results on a variety of tasks by capturing long-range dependencies. By scaling the diffusion policy model to this massive size, the researchers aimed to improve the model's ability to learn and execute dexterous robot manipulation skills.
The paper presents the architecture and training details of these large-scale diffusion policy models, as well as experiments evaluating their performance on robotic manipulation benchmarks. The results demonstrate significant improvements in manipulation capabilities compared to smaller baseline models, suggesting that scaling diffusion policy models to a billion parameters can be an effective approach for advancing the state-of-the-art in robot learning.
Critical Analysis
The paper provides a thorough technical explanation of the scaled diffusion policy model and its application to robotic manipulation tasks. The key innovation is the scaling of these models to an extremely large size of 1 billion parameters, which is an order of magnitude larger than typical policy models used in robotics.
One potential limitation noted in the paper is the computational and resource requirements for training and deploying these massive models. The researchers acknowledge that the large model size may limit practical deployment on resource-constrained robotic platforms. Further research into model compression or efficient inference techniques could help address this challenge.
Additionally, the paper only evaluates the models on a limited set of robotic manipulation benchmarks. While the results demonstrate impressive performance gains, it would be valuable to see how these models generalize to a wider range of real-world robotic tasks and environments. Exploring the model's robustness and ability to transfer to new scenarios could uncover additional insights and limitations.
Overall, the paper makes a compelling case for the benefits of scaling diffusion policy models to larger sizes for advancing robot learning capabilities. However, further research is needed to fully understand the practical implications and limitations of this approach in real-world robotic applications.
Conclusion
This paper presents an innovative approach to scaling diffusion policy models in transformer architectures to 1 billion parameters for improved robotic manipulation capabilities. By dramatically increasing the model size, the researchers were able to achieve significant performance gains on challenging manipulation benchmarks, suggesting that this scaling strategy can be an effective way to push the boundaries of robot learning.
While the computational and resource requirements of these large models may limit their immediate practical deployment, the insights from this research could inform the development of more efficient and scalable policy models for a wide range of robotic applications in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation
Minjie Zhu, Yichen Zhu, Jinming Li, Junjie Wen, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, Jian Tang
Diffusion Policy is a powerful technique tool for learning end-to-end visuomotor robot control. It is expected that Diffusion Policy possesses scalability, a key attribute for deep neural networks, typically suggesting that increasing model size would lead to enhanced performance. However, our observations indicate that Diffusion Policy in transformer architecture (DP) struggles to scale effectively; even minor additions of layers can deteriorate training outcomes. To address this issue, we introduce Scalable Diffusion Transformer Policy for visuomotor learning. Our proposed method, namely textbf{methodname}, introduces two modules that improve the training dynamic of Diffusion Policy and allow the network to better handle multimodal action distribution. First, we identify that DP~suffers from large gradient issues, making the optimization of Diffusion Policy unstable. To resolve this issue, we factorize the feature embedding of observation into multiple affine layers, and integrate it into the transformer blocks. Additionally, our utilize non-causal attention which allows the policy network to enquote{see} future actions during prediction, helping to reduce compounding errors. We demonstrate that our proposed method successfully scales the Diffusion Policy from 10 million to 1 billion parameters. This new model, named methodname, can effectively scale up the model size with improved performance and generalization. We benchmark methodname~across 50 different tasks from MetaWorld and find that our largest methodname~outperforms DP~with an average improvement of 21.6%. Across 7 real-world robot tasks, our ScaleDP demonstrates an average improvement of 36.25% over DP-T on four single-arm tasks and 75% on three bimanual tasks. We believe our work paves the way for scaling up models for visuomotor learning. The project page is available at scaling-diffusion-policy.github.io.
Read more9/24/2024

0
Sparse Diffusion Policy: A Sparse, Reusable, and Flexible Policy for Robot Learning
Yixiao Wang, Yifei Zhang, Mingxiao Huo, Ran Tian, Xiang Zhang, Yichen Xie, Chenfeng Xu, Pengliang Ji, Wei Zhan, Mingyu Ding, Masayoshi Tomizuka
The increasing complexity of tasks in robotics demands efficient strategies for multitask and continual learning. Traditional models typically rely on a universal policy for all tasks, facing challenges such as high computational costs and catastrophic forgetting when learning new tasks. To address these issues, we introduce a sparse, reusable, and flexible policy, Sparse Diffusion Policy (SDP). By adopting Mixture of Experts (MoE) within a transformer-based diffusion policy, SDP selectively activates experts and skills, enabling efficient and task-specific learning without retraining the entire model. SDP not only reduces the burden of active parameters but also facilitates the seamless integration and reuse of experts across various tasks. Extensive experiments on diverse tasks in both simulations and real world show that SDP 1) excels in multitask scenarios with negligible increases in active parameters, 2) prevents forgetting in continual learning of new tasks, and 3) enables efficient task transfer, offering a promising solution for advanced robotic applications. Demos and codes can be found in https://forrest-110.github.io/sparse_diffusion_policy/.
Read more7/2/2024
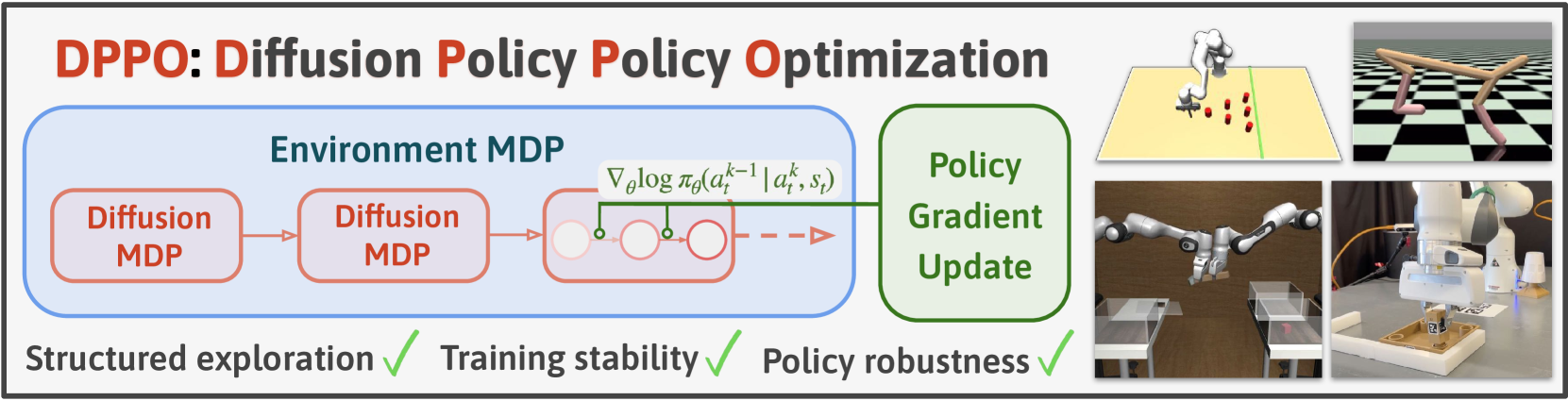
0
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024
👨🏫
0
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Tsung-Wei Ke, Nikolaos Gkanatsios, Katerina Fragkiadaki
Diffusion policies are conditional diffusion models that learn robot action distributions conditioned on the robot and environment state. They have recently shown to outperform both deterministic and alternative action distribution learning formulations. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy equipped with a novel 3D denoising transformer that fuses information from the 3D visual scene, a language instruction and proprioception to predict the noise in noised 3D robot pose trajectories. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 18.1% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it improves over the current SOTA by a 9% relative increase. It also learns to control a robot manipulator in the real world from a handful of demonstrations. Through thorough comparisons with the current SOTA policies and ablations of our model, we show 3D Diffuser Actor's design choices dramatically outperform 2D representations, regression and classification objectives, absolute attentions, and holistic non-tokenized 3D scene embeddings.
Read more7/26/2024