Scaling Law for Time Series Forecasting
2405.15124
0
0
🛸
Abstract
Scaling law that rewards large datasets, complex models and enhanced data granularity has been observed in various fields of deep learning. Yet, studies on time series forecasting have cast doubt on scaling behaviors of deep learning methods for time series forecasting: while more training data improves performance, more capable models do not always outperform less capable models, and longer input horizons may hurt performance for some models. We propose a theory for scaling law for time series forecasting that can explain these seemingly abnormal behaviors. We take into account the impact of dataset size and model complexity, as well as time series data granularity, particularly focusing on the look-back horizon, an aspect that has been unexplored in previous theories. Furthermore, we empirically evaluate various models using a diverse set of time series forecasting datasets, which (1) verifies the validity of scaling law on dataset size and model complexity within the realm of time series forecasting, and (2) validates our theoretical framework, particularly regarding the influence of look back horizon. We hope our findings may inspire new models targeting time series forecasting datasets of limited size, as well as large foundational datasets and models for time series forecasting in future works.footnote{Codes for our experiments will be made public at: url{https://github.com/JingzheShi/ScalingLawForTimeSeriesForecasting}.
Create account to get full access
Overview
• This paper investigates the scaling properties of large time series models, exploring how model performance changes as the model size and dataset size are increased.
• The authors propose a scaling law that can accurately predict the performance of time series forecasting models as they are scaled up in size and complexity.
• The insights from this research could help guide the development of more efficient and effective time series models, with potential applications in fields like finance, economics, and logistics.
Plain English Explanation
The researchers in this paper looked at how the performance of time series forecasting models changes as the models get bigger and the datasets they use get larger. Time series forecasting is the task of predicting future values in a sequence of data points, like stock prices or weather patterns, based on past observations.
As models and datasets grow in size, it becomes important to understand how this scaling affects the models' accuracy and efficiency. The researchers developed a mathematical formula, called a scaling law, that can predict how a time series model's performance will change as the model and dataset size are increased.
This scaling law could help guide the development of better time series forecasting models in the future. For example, it could allow researchers to estimate how much they need to increase a model's size and the amount of training data to achieve a desired level of forecasting accuracy. This could lead to more efficient and effective time series models with applications in fields like finance, economics, and logistics.
Technical Explanation
The paper proposes a scaling law that describes how the performance of time series forecasting models changes as model size and dataset size are increased. Specifically, the authors derive a relationship between the mean squared error (MSE) of a time series model, the number of model parameters, and the amount of training data.
The key insight is that the MSE scales as a power law with respect to the number of model parameters and the amount of training data. This means that as a model is scaled up in size, and the training dataset is expanded, the forecasting error decreases in a predictable way described by the scaling law.
The authors validate the scaling law across multiple time series benchmarks and model architectures, including recurrent neural networks and transformer-based models. They show that the scaling law holds across a wide range of model and dataset sizes, providing a unified framework for understanding the capabilities of large time series forecasting models.
The technical analysis in the paper includes deriving the scaling law mathematically, evaluating the law's goodness-of-fit to empirical data, and exploring the implications of the scaling behavior for model development and optimization.
Critical Analysis
The scaling law proposed in the paper provides a valuable tool for understanding and predicting the performance of large time series forecasting models. However, the authors acknowledge several caveats and limitations to their findings.
First, the scaling law was derived and validated on a limited set of benchmark datasets and model architectures. While the authors show the law holds across a range of settings, further research is needed to test its generalizability to other time series domains and model types.
Additionally, the scaling law assumes that model and dataset scaling follow idealized power law relationships. In practice, there may be more complex dynamics, bottlenecks, or other factors that cause deviations from the predicted scaling behavior.
The paper also does not address potential issues around data quality, distribution shift, or other real-world challenges that can impact the performance of time series models in deployed settings. Careful consideration of these practical concerns will be necessary to fully realize the benefits of the scaling law.
Despite these limitations, the core insights from this research represent an important step forward in understanding the scaling properties of large time series models. The scaling law provides a principled framework for guiding model development and optimization, which could lead to more robust and efficient time series forecasting systems.
Conclusion
This paper presents a scaling law that describes how the performance of time series forecasting models changes as the models and datasets grow in size and complexity. The authors demonstrate that the forecasting error of these models follows a predictable power law relationship with the number of model parameters and the amount of training data.
The scaling law offers a valuable tool for researchers and practitioners working on time series problems. It can help guide the development of more efficient and effective forecasting models, with potential applications in finance, economics, logistics, and other domains that rely on accurate predictions of sequential data.
While the scaling law has some limitations, this work represents an important advancement in our understanding of the fundamental scaling properties of large time series models. Further research building on these insights could lead to transformative improvements in time series forecasting capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024
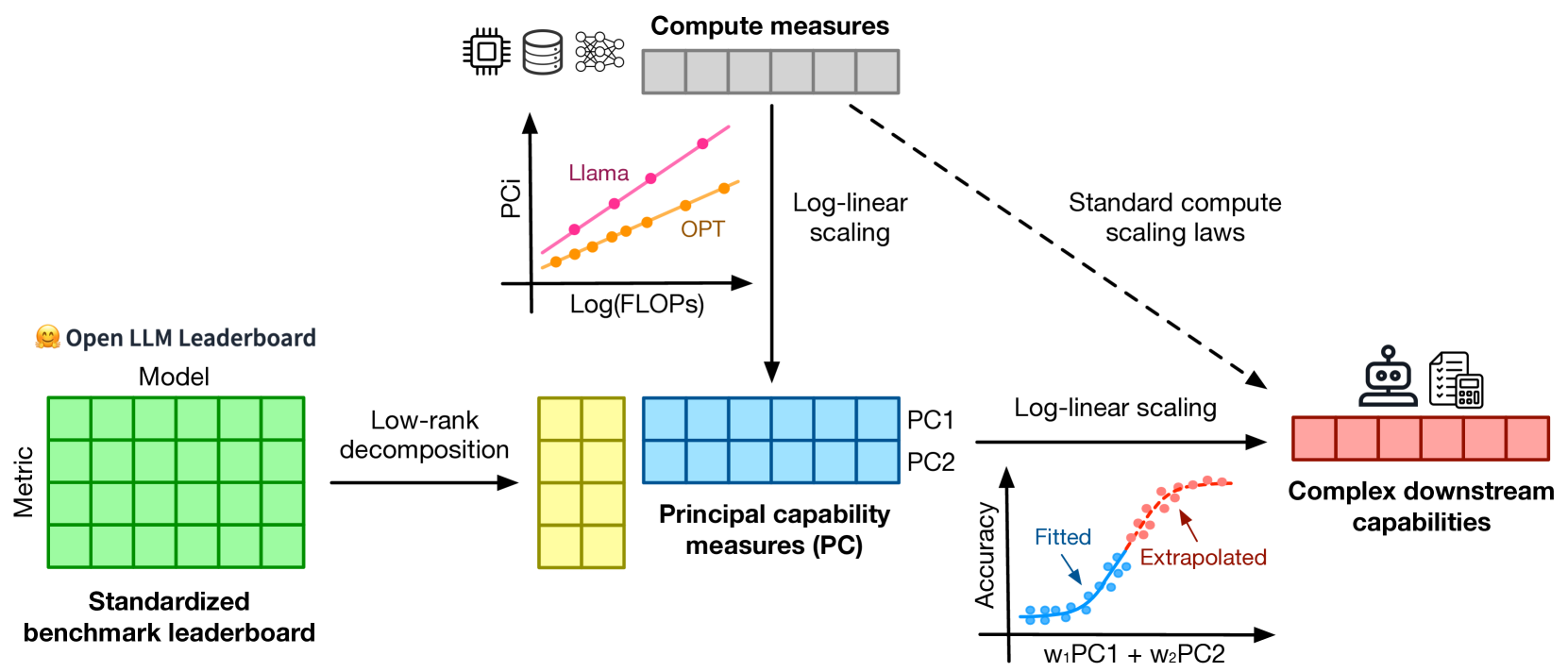
Observational Scaling Laws and the Predictability of Language Model Performance
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
0
0
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
5/20/2024
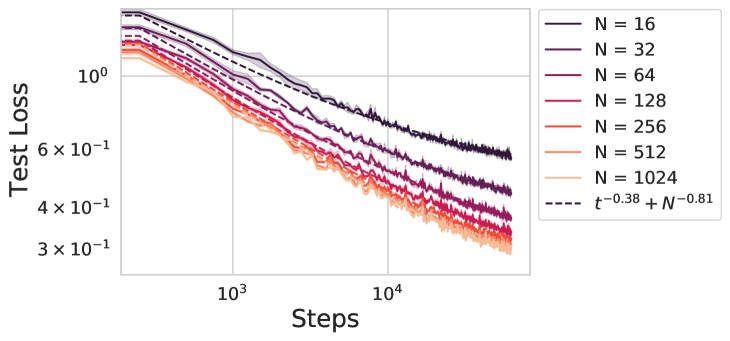
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
6/26/2024
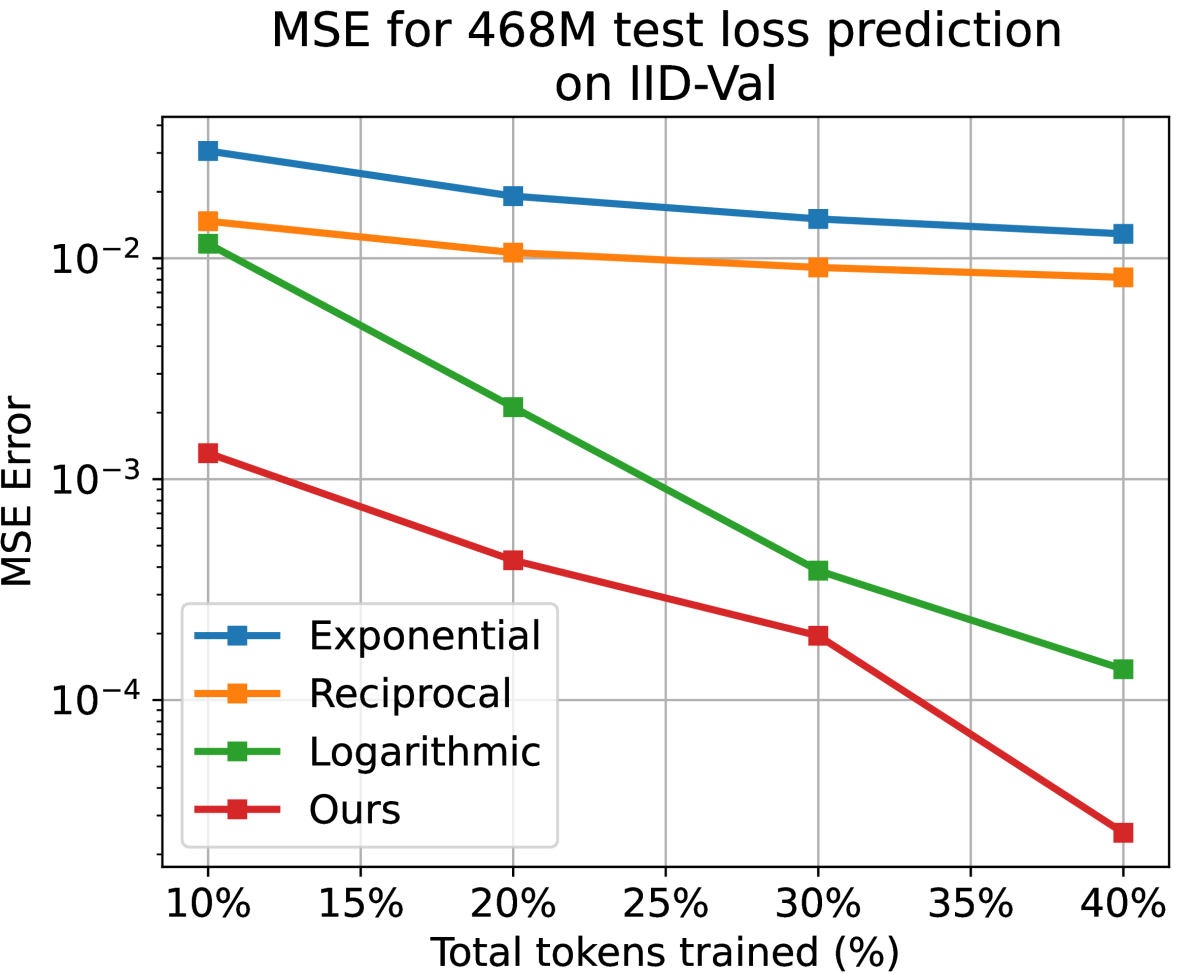
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
0
0
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
6/18/2024