Language models scale reliably with over-training and on downstream tasks

0

Sign in to get full access
Overview
- This paper explores how language models scale with increased training data and perform on downstream tasks.
- The researchers find that language models reliably scale with over-training and maintain strong performance on a variety of tasks.
- The paper provides insights into the scaling properties of large language models and their practical applications.
Plain English Explanation
The paper examines how language models, which are AI systems trained on large amounts of text data to understand and generate human language, behave as they are trained on more and more data. The researchers discovered that language models can be trained on massive amounts of data without losing their effectiveness. In fact, the models actually get better at a variety of language-related tasks as they are trained on more information.
This is an important finding because it suggests that language models can continue to improve and become more capable as we give them access to ever-larger datasets. The paper shows that there are reliable "scaling laws" that govern how language models perform - in other words, we can predict how they will change and improve as they are trained on more data.
This builds on previous research that has explored scaling laws in machine learning models. The authors are adding to our understanding of how these scaling principles apply specifically to large language models, which have become increasingly important in fields like natural language processing, dialogue systems, and content generation.
Overall, this research indicates that we can continue to make significant advances in language AI by investing in larger training datasets and more powerful computing resources. The models will reliably become more capable over time, opening up new possibilities for using language technology to assist and interact with humans.
Technical Explanation
The paper examines the scaling properties of large language models as they are trained on increasing amounts of data. The researchers trained a number of different language model architectures, including Transformer, LSTM, and Recurrent models, on datasets ranging from 1 billion to over 1 trillion tokens.
Their results show that language models exhibit reliable scaling laws, where performance metrics like perplexity, accuracy, and task-specific scores scale predictably with the amount of training data. This held true not only for the base language modeling task, but also for a wide range of downstream tasks like question answering, dialogue, and commonsense reasoning.
Furthermore, the models did not exhibit diminishing returns with over-training - they continued to improve as more data was added, with no sign of plateauing or performance degradation. This contrasts with previous concerns about language models becoming overfitted or unstable with excessive training.
The researchers also found that these scaling laws were largely independent of model architecture, suggesting fundamental principles governing language model scaling that transcend specific model designs. They propose that these findings may be explained by data-dependent scaling laws, where the intrinsic complexity of language data allows models to continuously absorb and leverage larger training sets.
Critical Analysis
The paper provides a rigorous and comprehensive analysis of language model scaling, addressing important open questions in the field. The findings are compelling and build on a growing body of research around scaling laws in machine learning.
That said, the study is limited to a relatively narrow set of language model architectures and tasks. While the authors argue the scaling principles may generalize, further research is needed to verify this across a wider range of model types and applications.
Additionally, the paper does not deeply explore potential caveats or failure modes of over-training. While the models did not exhibit degradation, there may be edge cases or specific contexts where excessive training leads to undesirable behaviors that warrant further investigation.
The authors also note that the data-dependent scaling hypothesis requires more theoretical grounding. The exact mechanisms driving the observed scaling laws are not fully explained, leaving room for additional research to unpack the underlying principles.
Overall, this is an important contribution that significantly advances our understanding of language model scaling. However, as with any research, there are opportunities for further exploration and refinement of the ideas presented.
Conclusion
This paper provides compelling evidence that large language models can be trained on massive datasets without suffering from diminishing returns or performance degradation. The researchers found robust scaling laws that govern how these models improve across a variety of language tasks as training data increases.
These findings have important implications for the continued development of advanced language AI systems. They suggest we can expect language models to become steadily more capable as we invest in larger training corpora and computing power. This opens up new possibilities for using language technology to assist and interact with humans in more sophisticated ways.
While the study is not without limitations, it represents a significant step forward in our understanding of language model scaling. The insights generated by this research will likely inform and inspire further advancements in the field of natural language processing and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
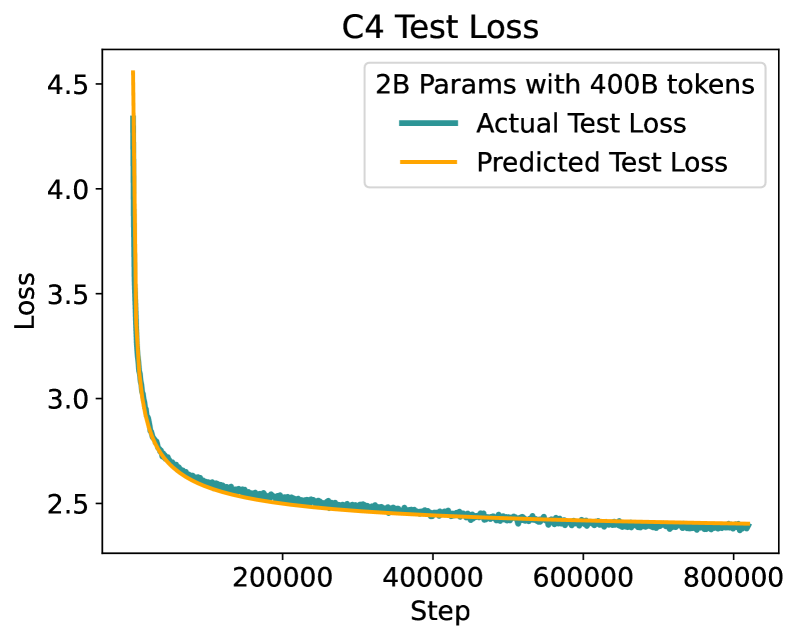
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Read more6/18/2024
0
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Read more4/8/2024
1
Observational Scaling Laws and the Predictability of Language Model Performance
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
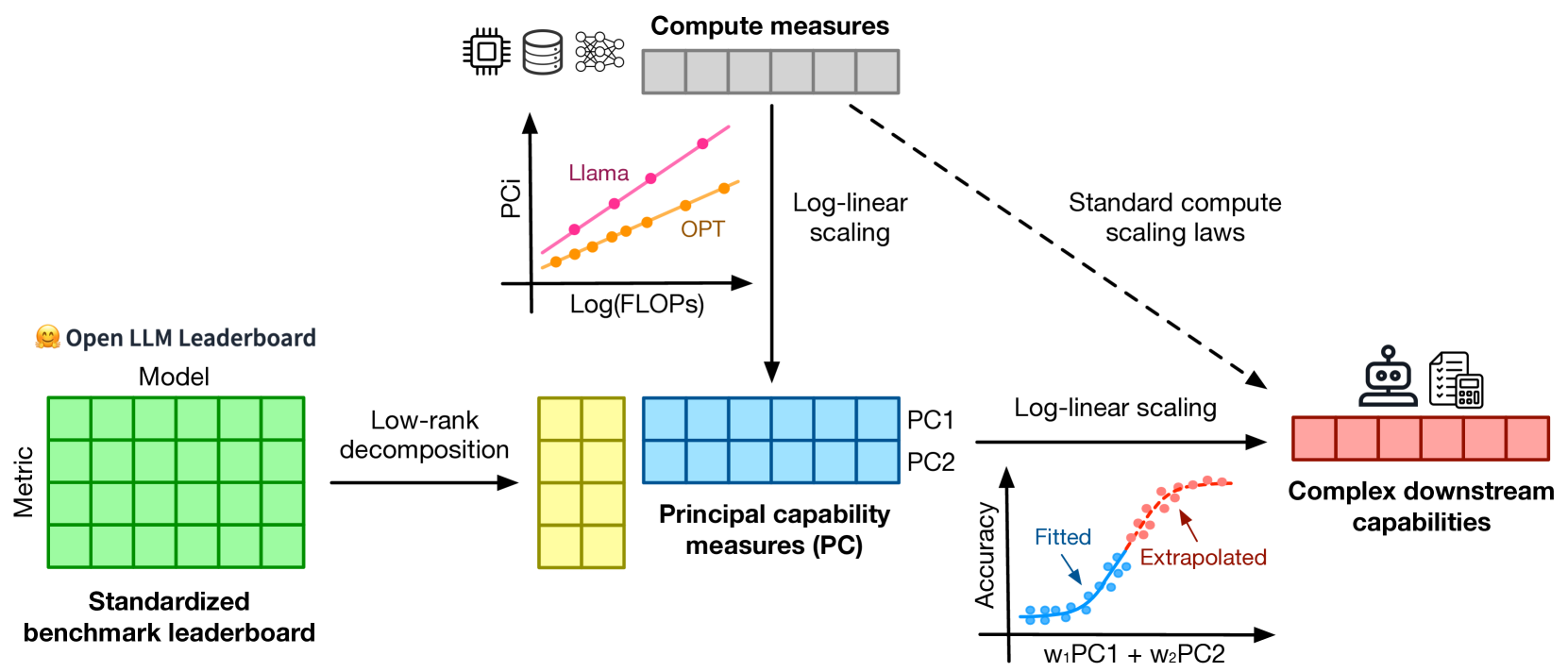
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Read more5/20/2024
0
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Zhenpeng Su, Jianwei Niu, Guiguang Ding
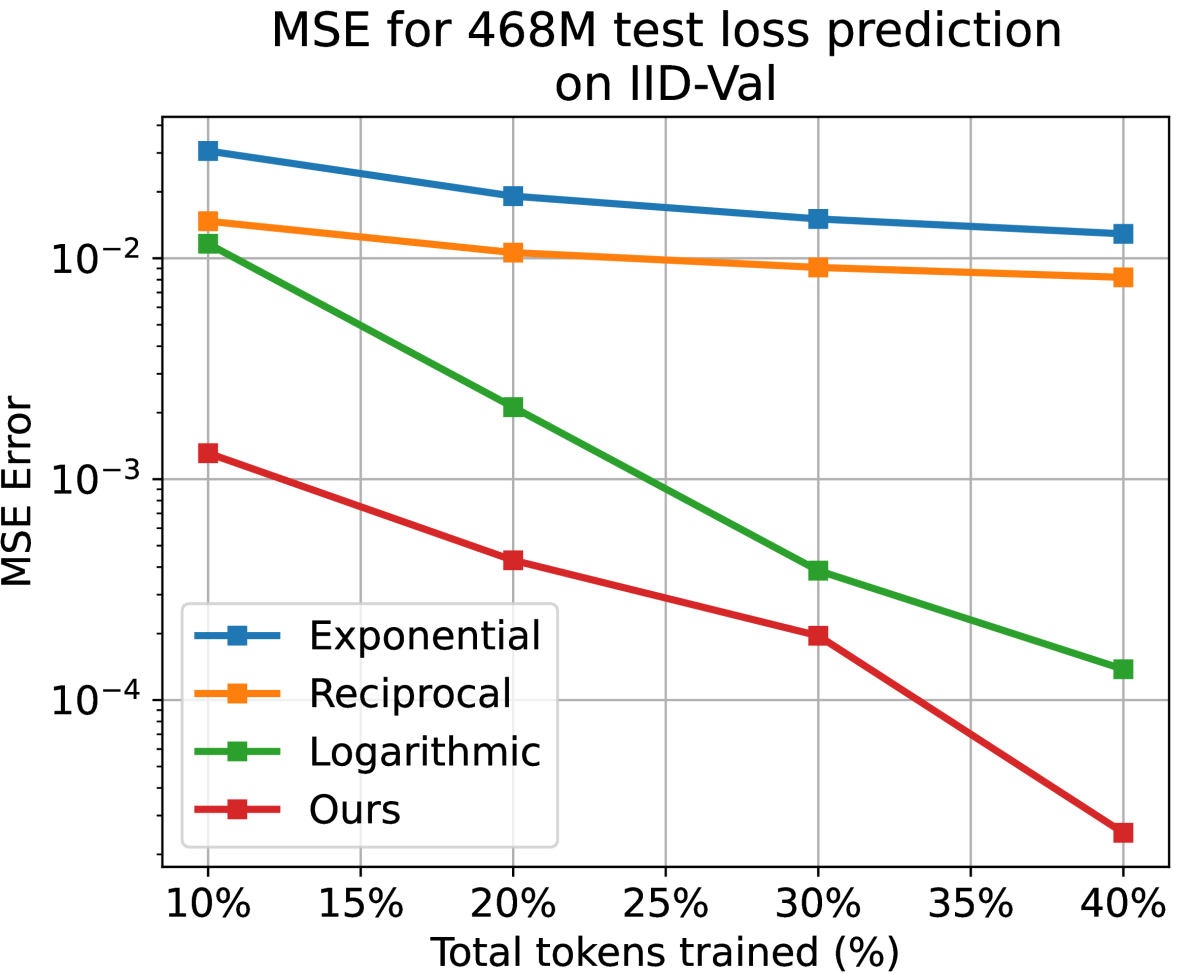
Recently, Large Language Models (LLMs) have been widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed Scaling Laws, have discovered that the final test loss of LLMs scales as power-laws with model size, computational budget, and dataset size. However, the temporal change of the test loss of an LLM throughout its pre-training process remains unexplored, though it is valuable in many aspects, such as selecting better hyperparameters textit{directly} on the target LLM. In this paper, we propose the novel concept of Temporal Scaling Law, studying how the test loss of an LLM evolves as the training steps scale up. In contrast to modeling the test loss as a whole in a coarse-grained manner, we break it down and dive into the fine-grained test loss of each token position, and further develop a dynamic hyperbolic-law. Afterwards, we derive the much more precise temporal scaling law by studying the temporal patterns of the parameters in the dynamic hyperbolic-law. Results on both in-distribution (ID) and out-of-distribution (OOD) validation datasets demonstrate that our temporal scaling law accurately predicts the test loss of LLMs across training steps. Our temporal scaling law has broad practical applications. First, it enables direct and efficient hyperparameter selection on the target LLM, such as data mixture proportions. Secondly, viewing the LLM pre-training dynamics from the token position granularity provides some insights to enhance the understanding of LLM pre-training.
Read more6/18/2024