Aligning Large Language Models with Diverse Political Viewpoints
2406.14155
0
0

Abstract
Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
Create account to get full access
Overview
- This paper investigates ways to align large language models (LLMs) with diverse political viewpoints.
- It explores methods for training LLMs to generate text that accurately represents a range of political perspectives, rather than exhibiting political bias.
- The research aims to improve the reliability and consistency of LLMs when engaging with political topics.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of subjects. However, these models can sometimes exhibit political biases, meaning they may produce text that favors certain political views over others.
This research paper explores ways to train LLMs to be more aligned with diverse political viewpoints. The goal is to create models that can accurately represent a range of political perspectives, rather than just a single viewpoint. This is important because LLMs are increasingly being used for tasks like generating political texts and analyzing political orientation, and it's crucial that they do so in a reliable and unbiased way.
The researchers use a technique called prompt scaling to finetune LLMs on a diverse set of political texts. This helps the models learn to generate text that reflects a range of political views, rather than just the views expressed in the original training data.
The paper also explores ways to evaluate the reliability and consistency of these politically-aligned LLMs, to ensure that they are generating text that accurately represents the intended political viewpoints.
Overall, this research is an important step towards developing LLMs that can engage with political topics in a more balanced and trustworthy way, which could have significant implications for fields like journalism, policy analysis, and political discourse.
Technical Explanation
The paper begins by describing the importance of aligning large language models (LLMs) with diverse political viewpoints. The researchers note that while LLMs have become powerful tools for generating text, they can often exhibit political biases that lead them to favor certain viewpoints over others.
To address this issue, the researchers propose a technique called "prompt scaling." This involves finetuning LLMs on a diverse set of political texts, which helps the models learn to generate text that reflects a range of political perspectives. The researchers use a dataset of political speeches, debates, and news articles spanning the political spectrum to train their models.
The paper then describes how the researchers evaluated the reliability and consistency of the politically-aligned LLMs. They did this by having the models generate text in response to a variety of political prompts, and then analyzing the coherence and diversity of the generated text. The researchers also explored ways to measure the "political preferences" of the LLMs to ensure that the models were accurately representing the intended political viewpoints.
The results of the experiments show that the prompt scaling approach was effective in aligning the LLMs with diverse political viewpoints, without sacrificing the models' overall performance on language generation tasks. The researchers found that the politically-aligned LLMs were able to generate text that reflected a range of political perspectives, and that the models' responses were more consistent and reliable than those of LLMs trained on more biased data.
Critical Analysis
The paper presents a promising approach for aligning LLMs with diverse political viewpoints, but it also acknowledges several limitations and areas for further research.
One limitation is that the dataset used to train the models may not fully capture the nuance and complexity of real-world political discourse. The researchers note that the dataset is primarily composed of "elite" political texts, such as speeches and debates, which may not reflect the views of the broader population.
Additionally, the paper does not delve deeply into the potential societal implications of politically-aligned LLMs. While the research is aimed at improving the reliability and consistency of these models, there may be concerns around the use of such models in sensitive political contexts, such as elections or policy debates.
The paper also does not address the potential for LLMs to be used to generate misinformation or propaganda, even if they are aligned with diverse political viewpoints. This is an important area for further research, as the widespread deployment of such models could have significant societal consequences.
Overall, the research presented in this paper represents an important step forward in the development of more politically-aware and unbiased language models. However, continued exploration of the ethical and societal implications of these technologies will be crucial as they become more prevalent in the years to come.
Conclusion
This paper explores methods for aligning large language models (LLMs) with diverse political viewpoints, with the goal of improving the reliability and consistency of these models when engaging with political topics.
The researchers use a technique called "prompt scaling" to finetune LLMs on a diverse set of political texts, which helps the models learn to generate text that reflects a range of political perspectives. The paper also describes how the researchers evaluated the political alignment and consistency of the models, finding that the prompt scaling approach was effective in producing LLMs that could accurately represent a variety of political viewpoints.
While the research presented in this paper is promising, it also acknowledges several limitations and areas for further exploration. Continued work in this area will be crucial as LLMs become increasingly influential in domains such as journalism, policy analysis, and political discourse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
0
0
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
6/6/2024
💬
Large Language Models' Detection of Political Orientation in Newspapers
Alessio Buscemi, Daniele Proverbio
0
0
Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
6/4/2024
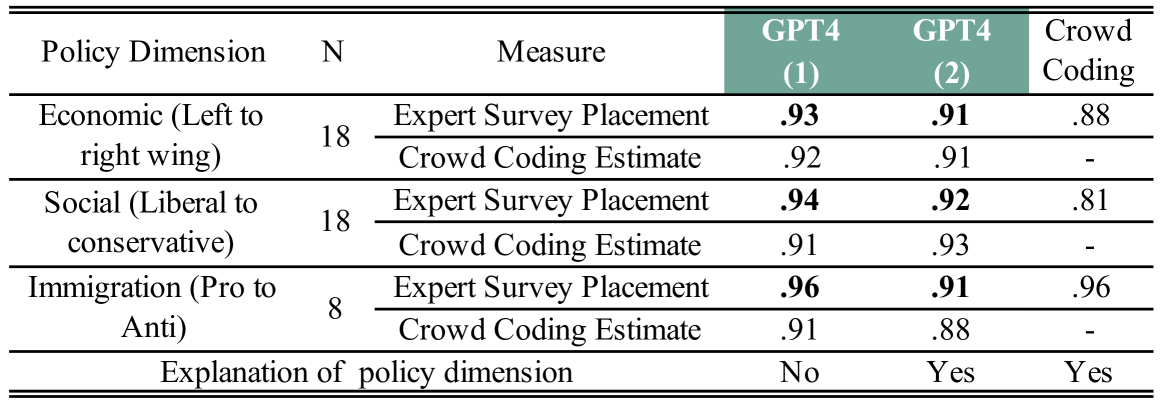
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
0
0
We use instruction-tuned Large Language Models (LLMs) such as GPT-4, MiXtral, and Llama 3 to position political texts within policy and ideological spaces. We directly ask the LLMs where a text document or its author stand on the focal policy dimension. We illustrate and validate the approach by scaling British party manifestos on the economic, social, and immigration policy dimensions; speeches from a European Parliament debate in 10 languages on the anti- to pro-subsidy dimension; Senators of the 117th US Congress based on their tweets on the left-right ideological spectrum; and tweets published by US Representatives and Senators after the training cutoff date of GPT-4. The correlation between the position estimates obtained with the best LLMs and benchmarks based on coding by experts, crowdworkers or roll call votes exceeds .90. This training-free approach also outperforms supervised classifiers trained on large amounts of data. Using instruction-tuned LLMs to scale texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
5/14/2024
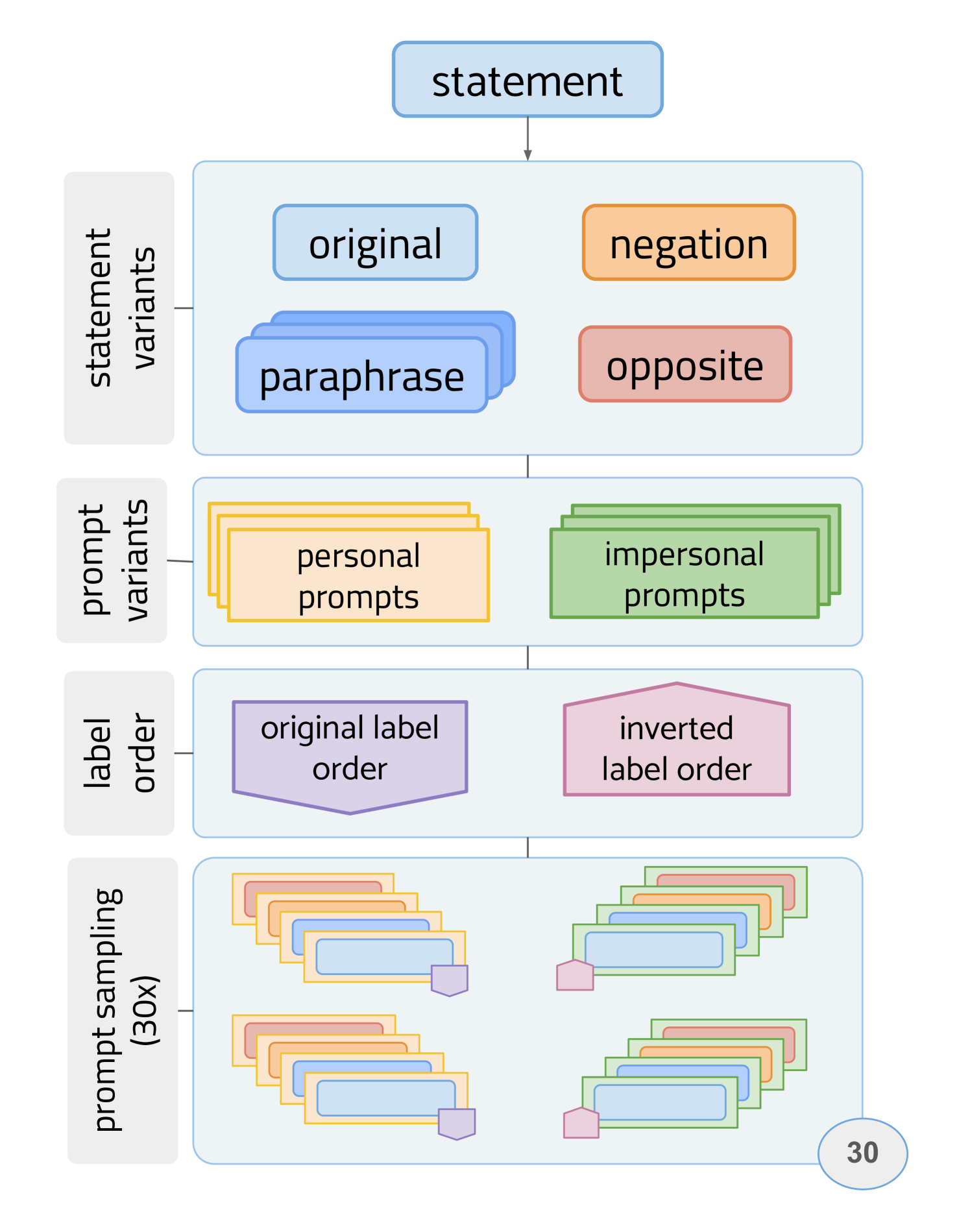
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Tanise Ceron, Neele Falk, Ana Bari'c, Dmitry Nikolaev, Sebastian Pad'o
0
0
Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings (Feng et al., 2023; Motoki et al., 2024). However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare state and liberal society but also (right-wing) law and order, with no consistent preferences in foreign policy and migration.
6/5/2024