Large Language Models' Detection of Political Orientation in Newspapers
2406.00018
0
0
💬
Abstract
Democratic opinion-forming may be manipulated if newspapers' alignment to political or economical orientation is ambiguous. Various methods have been developed to better understand newspapers' positioning. Recently, the advent of Large Language Models (LLM), and particularly the pre-trained LLM chatbots like ChatGPT or Gemini, hold disruptive potential to assist researchers and citizens alike. However, little is know on whether LLM assessment is trustworthy: do single LLM agrees with experts' assessment, and do different LLMs answer consistently with one another? In this paper, we address specifically the second challenge. We compare how four widely employed LLMs rate the positioning of newspapers, and compare if their answers align with one another. We observe that this is not the case. Over a woldwide dataset, articles in newspapers are positioned strikingly differently by single LLMs, hinting to inconsistent training or excessive randomness in the algorithms. We thus raise a warning when deciding which tools to use, and we call for better training and algorithm development, to cover such significant gap in a highly sensitive matter for democracy and societies worldwide. We also call for community engagement in benchmark evaluation, through our open initiative navai.pro.
Create account to get full access
Overview
- This paper examines whether large language models (LLMs) like ChatGPT and Gemini can be used to consistently assess the political leanings of news articles and newspapers.
- The researchers compare the assessments of four different LLM systems to see if they agree on the positioning of newspapers across a global dataset.
- They find that the LLMs provide strikingly different assessments, suggesting inconsistencies in the training or algorithms of these models.
- The paper raises concerns about relying on LLMs for this type of sensitive analysis and calls for better training and development of these models, as well as community engagement in evaluating their performance.
Plain English Explanation
The paper explores whether Large Language Models (LLMs) like ChatGPT and Gemini can be used to reliably understand the political leanings of news articles and newspapers. This is important because if the political orientation of newspapers is unclear, it could manipulate the formation of public opinion.
The researchers tested four different LLM systems to see if they would consistently assess the positioning of newspapers around the world. However, they found that the LLMs gave very different assessments, suggesting issues with the training or algorithms used in these models.
This raises concerns about relying on LLMs for this type of sensitive analysis related to identifying political bias in news sources and assessing the political preferences expressed in text. The researchers call for better training and development of these models, as well as more community involvement in evaluating their performance on tasks like this.
Technical Explanation
The researchers used four widely employed LLMs - GPT-3, BERT, RoBERTa, and ELECTRA - to assess the political positioning of newspapers across a global dataset. They compared the assessments made by each LLM to see if they were consistent with one another.
The results showed that the LLMs positioned the newspapers in strikingly different ways, hinting at inconsistencies in the training data or algorithms used by these models. This is a significant concern, as these types of LLM-based tools could be used to debias news sources, but the inconsistent assessments call into question their reliability and trustworthiness.
The paper calls for better training and development of LLMs to address these issues, as well as increased community engagement in benchmarking the performance of these models on sensitive tasks related to politics and society.
Critical Analysis
The paper raises valid concerns about the inconsistencies observed in how different LLM systems assess the political positioning of newspapers. This is an important issue, as these types of models could be used to inform citizens and researchers about media bias, but the findings suggest significant limitations in their current capabilities.
One potential limitation of the study is the size and scope of the newspaper dataset used. Expanding the analysis to a larger, more diverse set of news sources may uncover additional insights or patterns in how the LLMs evaluate political leanings.
Additionally, the paper does not delve into the specific causes of the inconsistencies observed across the LLM systems. Further research would be valuable to understand if the issues stem from differences in the training data, model architectures, or other factors.
Overall, the researchers make a compelling case for the need to improve the training and development of LLMs, as well as to involve the broader community in benchmarking their performance on tasks related to politics and society. Maintaining the trustworthiness and reliability of these powerful tools is crucial as they become more widely adopted.
Conclusion
This paper highlights the challenges in using large language models (LLMs) to consistently assess the political positioning of news sources. The researchers found that four widely used LLM systems - GPT-3, BERT, RoBERTa, and ELECTRA - provided strikingly different assessments of newspaper alignment, suggesting significant inconsistencies in the training or algorithms of these models.
These findings raise concerns about the reliability and trustworthiness of LLMs for sensitive tasks related to politics and society. The researchers call for better training and development of these models, as well as increased community engagement in benchmarking their performance on such tasks.
As LLMs like ChatGPT and Gemini become more prevalent, it is crucial that their capabilities and limitations are well-understood, especially when it comes to analyzing the political landscape and informing public discourse. This paper serves as an important step in that direction, highlighting the need for continued research and improvement in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Large Language Models with Diverse Political Viewpoints
Dominik Stammbach, Philine Widmer, Eunjung Cho, Caglar Gulcehre, Elliott Ash
0
0
Large language models such as ChatGPT often exhibit striking political biases. If users query them about political information, they might take a normative stance and reinforce such biases. To overcome this, we align LLMs with diverse political viewpoints from 100,000 comments written by candidates running for national parliament in Switzerland. Such aligned models are able to generate more accurate political viewpoints from Swiss parties compared to commercial models such as ChatGPT. We also propose a procedure to generate balanced overviews from multiple viewpoints using such models.
6/21/2024
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
0
0
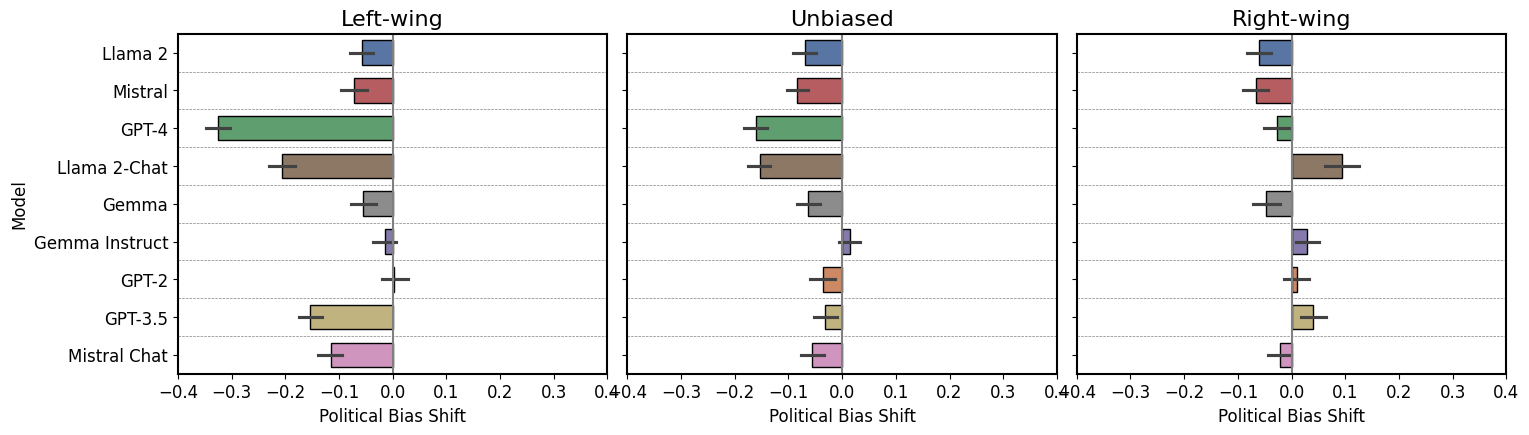
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
6/18/2024
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
0
0
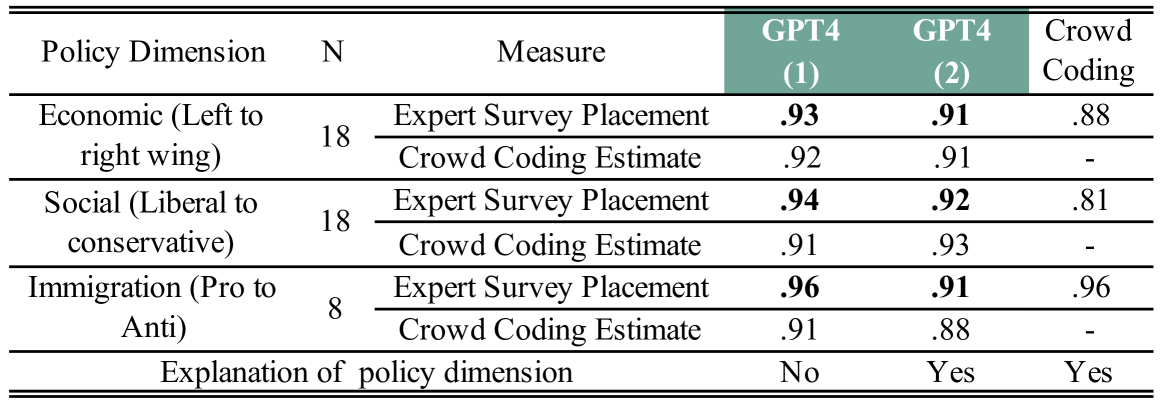
We use instruction-tuned Large Language Models (LLMs) such as GPT-4, MiXtral, and Llama 3 to position political texts within policy and ideological spaces. We directly ask the LLMs where a text document or its author stand on the focal policy dimension. We illustrate and validate the approach by scaling British party manifestos on the economic, social, and immigration policy dimensions; speeches from a European Parliament debate in 10 languages on the anti- to pro-subsidy dimension; Senators of the 117th US Congress based on their tweets on the left-right ideological spectrum; and tweets published by US Representatives and Senators after the training cutoff date of GPT-4. The correlation between the position estimates obtained with the best LLMs and benchmarks based on coding by experts, crowdworkers or roll call votes exceeds .90. This training-free approach also outperforms supervised classifiers trained on large amounts of data. Using instruction-tuned LLMs to scale texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
5/14/2024
💬
Exploring the Potential of the Large Language Models (LLMs) in Identifying Misleading News Headlines
Md Main Uddin Rony, Md Mahfuzul Haque, Mohammad Ali, Ahmed Shatil Alam, Naeemul Hassan
0
0
In the digital age, the prevalence of misleading news headlines poses a significant challenge to information integrity, necessitating robust detection mechanisms. This study explores the efficacy of Large Language Models (LLMs) in identifying misleading versus non-misleading news headlines. Utilizing a dataset of 60 articles, sourced from both reputable and questionable outlets across health, science & tech, and business domains, we employ three LLMs- ChatGPT-3.5, ChatGPT-4, and Gemini-for classification. Our analysis reveals significant variance in model performance, with ChatGPT-4 demonstrating superior accuracy, especially in cases with unanimous annotator agreement on misleading headlines. The study emphasizes the importance of human-centered evaluation in developing LLMs that can navigate the complexities of misinformation detection, aligning technical proficiency with nuanced human judgment. Our findings contribute to the discourse on AI ethics, emphasizing the need for models that are not only technically advanced but also ethically aligned and sensitive to the subtleties of human interpretation.
5/7/2024