Scaling Technology Acceptance Analysis with Large Language Model (LLM) Annotation Systems

0
💬
Sign in to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) for scaling technology acceptance analysis, where researchers assess how people perceive and adopt new technologies.
- The authors discuss the potential of LLM-based annotation systems to streamline and automate the process of analyzing large datasets related to technology acceptance.
- The paper covers the key aspects of LLM annotation systems, their effectiveness compared to traditional human-based annotation, and the broader implications for conducting advanced text analytics.
Plain English Explanation
Researchers often study how people react to and adopt new technologies, a field known as technology acceptance analysis. This paper explores using powerful language AI models, called Large Language Models (LLMs), to help with this research.
LLMs are AI systems that can understand and generate human-like text. The authors suggest using LLMs to automatically analyze large datasets related to how people perceive and use new technologies. This could make the research process more efficient and scalable, compared to having humans manually review and annotate the data.
The paper compares the performance of LLM-based annotation systems to traditional human-based approaches. It also discusses how LLMs can be used for advanced text analytics to gain deeper insights from the technology acceptance data.
The authors propose a framework called AnnOLLM that aims to make it easier to use LLMs for this type of research. They envision LLMs becoming valuable research assistants that can help scientists analyze large datasets more efficiently.
Technical Explanation
The paper presents a framework for using Large Language Models (LLMs) to scale technology acceptance analysis, which involves assessing how people perceive and adopt new technologies.
The authors discuss the potential of LLM-based annotation systems to streamline the process of analyzing large datasets related to technology acceptance. These systems can automatically classify and annotate textual data, such as user reviews or survey responses, according to relevant criteria like perceived usefulness, ease of use, and intention to use.
The paper compares the performance of LLM-based annotation to traditional human-based approaches, evaluating factors like accuracy, consistency, and efficiency. The results suggest that LLMs can match or even outperform human annotators in certain tasks, while offering the ability to scale up the analysis process.
The authors also discuss how LLMs can be leveraged for advanced text analytics on technology acceptance data. This includes extracting insights about user sentiment, identifying key factors influencing adoption, and generating summaries or hypotheses to guide further research.
To facilitate the use of LLMs for this purpose, the authors propose a framework called AnnOLLM, which aims to streamline the process of adapting LLMs to specific annotation tasks. The authors envision LLMs becoming valuable research assistants that can augment and accelerate the work of technology acceptance researchers.
Critical Analysis
The paper presents a compelling case for the use of Large Language Models (LLMs) in scaling technology acceptance analysis, but it also acknowledges several caveats and areas for further research.
One key limitation discussed is the potential for bias and inconsistency in LLM-based annotations, especially when dealing with complex or subjective concepts. The authors note that careful training and evaluation of LLM models is necessary to ensure reliable and unbiased results.
Additionally, the paper does not address the potential privacy and ethical concerns that may arise when using LLMs to analyze user-generated data, such as reviews or social media posts. Researchers will need to carefully consider data privacy and obtain appropriate consent from participants.
Further research is also needed to fully understand the long-term implications of relying on LLMs as research assistants. This includes investigating the potential for LLMs to introduce new biases or errors that could impact the validity of research findings.
Overall, the paper presents a promising approach to leveraging the power of LLMs to streamline technology acceptance analysis, but it also highlights the importance of maintaining a critical and thoughtful approach to the use of these powerful AI systems in academic research.
Conclusion
This paper explores the potential of using Large Language Models (LLMs) to scale and automate the process of technology acceptance analysis, a field focused on understanding how people perceive and adopt new technologies.
The authors discuss the development of LLM-based annotation systems that can efficiently classify and analyze large datasets related to technology acceptance, potentially outperforming traditional human-based approaches in terms of accuracy, consistency, and scalability.
The paper also examines how LLMs can be leveraged for advanced text analytics to gain deeper insights from technology acceptance data, such as identifying key factors influencing user adoption and generating hypotheses to guide further research.
While the proposed framework presents a promising path forward, the authors acknowledge the need to address potential biases and ethical concerns associated with the use of LLMs in this context. Ongoing research and careful implementation will be crucial to ensuring the reliable and responsible application of these powerful AI systems in academic research.
Overall, this paper serves as an important contribution to the growing field of LLM-powered text analytics and its potential to transform various domains, including technology acceptance analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Scaling Technology Acceptance Analysis with Large Language Model (LLM) Annotation Systems
Pawel Robert Smolinski, Joseph Januszewicz, Jacek Winiarski
Technology acceptance models effectively predict how users will adopt new technology products. Traditional surveys, often expensive and cumbersome, are commonly used for this assessment. As an alternative to surveys, we explore the use of large language models for annotating online user-generated content, like digital reviews and comments. Our research involved designing an LLM annotation system that transform reviews into structured data based on the Unified Theory of Acceptance and Use of Technology model. We conducted two studies to validate the consistency and accuracy of the annotations. Results showed moderate-to-strong consistency of LLM annotation systems, improving further by lowering the model temperature. LLM annotations achieved close agreement with human expert annotations and outperformed the agreement between experts for UTAUT variables. These results suggest that LLMs can be an effective tool for analyzing user sentiment, offering a practical alternative to traditional survey methods and enabling deeper insights into technology design and adoption.
Read more7/2/2024
1
Large Language Models for Data Annotation: A Survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, Huan Liu
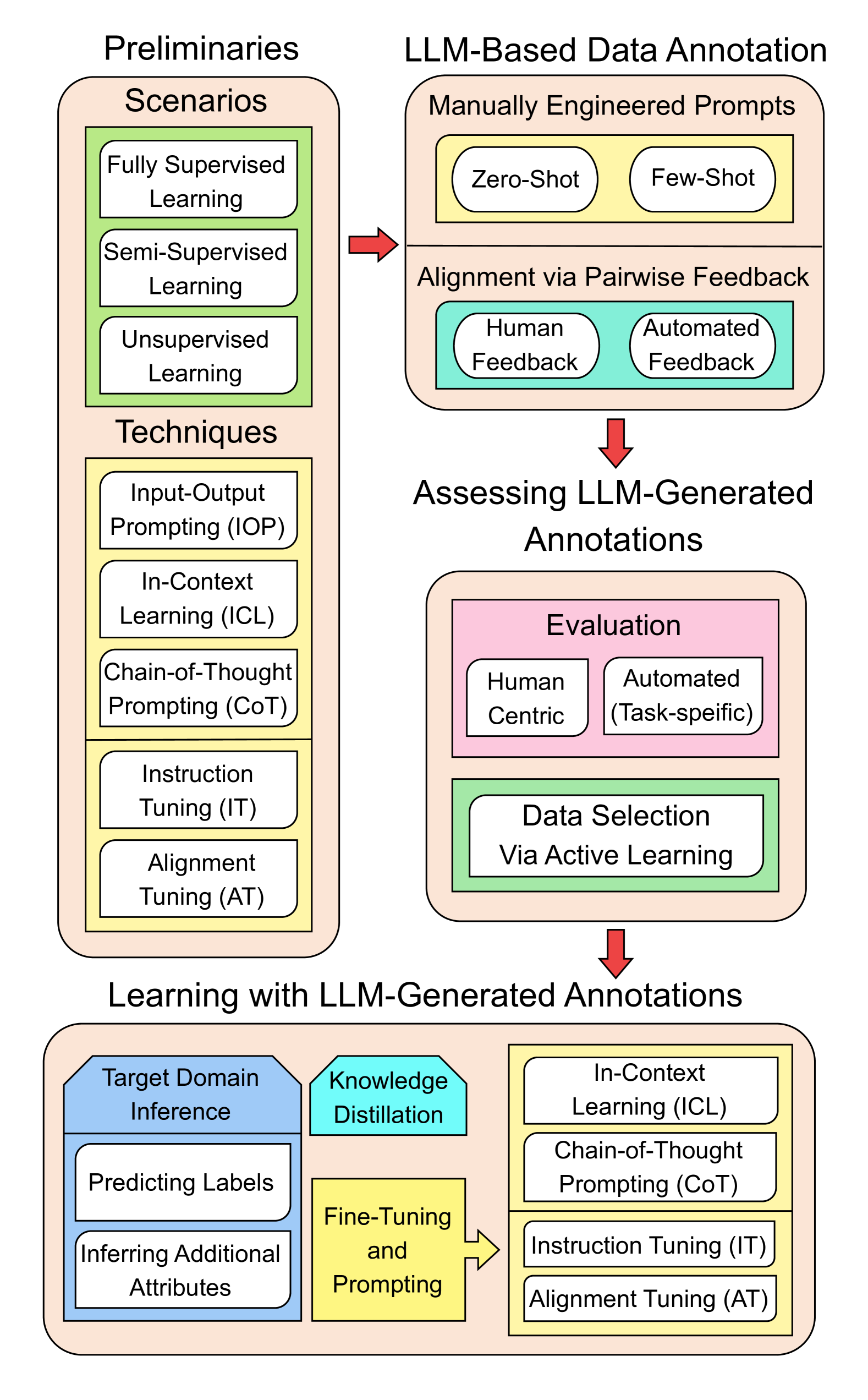
Data annotation generally refers to the labeling or generating of raw data with relevant information, which could be used for improving the efficacy of machine learning models. The process, however, is labor-intensive and costly. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to automate the complicated process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, we uniquely focus on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Annotation Generation, LLM-Generated Annotations Assessment, and LLM-Generated Annotations Utilization. Furthermore, this survey includes an in-depth taxonomy of data types that LLMs can annotate, a comprehensive review of learning strategies for models utilizing LLM-generated annotations, and a detailed discussion of the primary challenges and limitations associated with using LLMs for data annotation. Serving as a key guide, this survey aims to assist researchers and practitioners in exploring the potential of the latest LLMs for data annotation, thereby fostering future advancements in this critical field.
Read more6/26/2024

0
The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
Read more5/3/2024
💬
0
The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Dmitry Scherbakov, Nina Hubig, Vinita Jansari, Alexander Bakumenko, Leslie A. Lenert
Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.
Read more9/10/2024