Scaling Training Data with Lossy Image Compression

0

Sign in to get full access
Overview
- This paper explores the use of lossy image compression to scale up training data for machine learning models.
- The researchers investigate whether compressing images with lossy techniques can maintain the essential information needed for effective model training, while significantly reducing the storage requirements.
- The paper presents experiments and analyses that shed light on the potential benefits and limitations of this approach.
Plain English Explanation
The researchers in this study looked at whether they could use lossy image compression to make machine learning models more scalable. Lossy compression means that some image details are lost, but the file size is much smaller.
The key idea is that even if you lose some minor details in the images, the essential information needed to train the model might still be there. This could allow you to dramatically increase the amount of training data without running into storage constraints.
The researchers performed experiments to understand how the scaling laws of machine learning models are affected by using lossy compressed images for training. They looked at factors like the compression level, the model architecture, and the dataset to see how it impacts performance.
Overall, the findings suggest that judicious use of lossy compression can indeed allow for scalable training data without significantly hurting model performance. However, there are also important limitations and tradeoffs to consider, which the paper explores in depth.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of using lossy compressed images as training data for machine learning models. They explored how different levels of compression and model architectures affect the scaling behavior and performance of the trained models.
The core idea is that even if some minor details are lost due to lossy compression, the essential information needed for effective model training may still be preserved. This could enable dramatically scaling up the training data without running into storage constraints.
The researchers evaluated this hypothesis across multiple datasets and model types. They systematically varied the compression level and measured the model's performance, analyzing how the scaling laws are affected.
The results suggest that while there are indeed tradeoffs and limitations to this approach, judicious use of lossy compression can allow for significant increases in training data scale without undue harm to model performance. The paper provides detailed insights into the complex interplay between compression, architecture, and scaling.
Critical Analysis
The paper provides a rigorous and comprehensive exploration of the potential benefits and limitations of using lossy compressed images for scalable machine learning training. The researchers acknowledge that there are important caveats to consider, such as the sensitivity of different model architectures to compression artifacts and the potential for compression to disproportionately impact certain classes or features.
Additionally, the paper does not delve deeply into the theoretical foundations underlying the relationship between lossy compression and model performance. Further research could investigate the information-theoretic principles at play and develop more principled frameworks for understanding the compression-performance tradeoff.
The experimental design is generally sound, but one could argue that the range of compression levels and model architectures studied is still somewhat limited. Expanding the scope of the investigation to include a wider variety of compression techniques, model types, and dataset characteristics could yield additional insights and uncover edge cases or nuances not captured in this work.
Overall, the paper makes a compelling case for the viability of using lossy compression to scale training data, but also highlights the need for careful consideration of the specific use case and thorough empirical validation. Readers are encouraged to think critically about the broader implications and potential pitfalls of this approach as they evaluate its suitability for their own applications.
Conclusion
This paper presents a detailed exploration of using lossy image compression to enable scalable training data for machine learning models. The key finding is that judiciously applying lossy compression can significantly reduce storage requirements while maintaining the essential information needed for effective model training.
The researchers provide valuable insights into the complex interplay between compression level, model architecture, and scaling behavior. While there are important limitations and tradeoffs to consider, the results suggest that this approach has the potential to unlock new frontiers in machine learning by facilitating the use of much larger and more diverse training datasets.
As the field continues to push the boundaries of model scale and performance, techniques like those explored in this paper will likely play an increasingly important role in enabling these advancements. Readers are encouraged to consider the implications of this work for their own research and applications, and to critically evaluate the broader ethical and practical considerations around the use of lossy compression in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Training Data with Lossy Image Compression
Katherine L. Mentzer, Andrea Montanari
Empirically-determined scaling laws have been broadly successful in predicting the evolution of large machine learning models with training data and number of parameters. As a consequence, they have been useful for optimizing the allocation of limited resources, most notably compute time. In certain applications, storage space is an important constraint, and data format needs to be chosen carefully as a consequence. Computer vision is a prominent example: images are inherently analog, but are always stored in a digital format using a finite number of bits. Given a dataset of digital images, the number of bits $L$ to store each of them can be further reduced using lossy data compression. This, however, can degrade the quality of the model trained on such images, since each example has lower resolution. In order to capture this trade-off and optimize storage of training data, we propose a `storage scaling law' that describes the joint evolution of test error with sample size and number of bits per image. We prove that this law holds within a stylized model for image compression, and verify it empirically on two computer vision tasks, extracting the relevant parameters. We then show that this law can be used to optimize the lossy compression level. At given storage, models trained on optimally compressed images present a significantly smaller test error with respect to models trained on the original data. Finally, we investigate the potential benefits of randomizing the compression level.
Read more7/26/2024
0
gzip Predicts Data-dependent Scaling Laws
Rohan Pandey
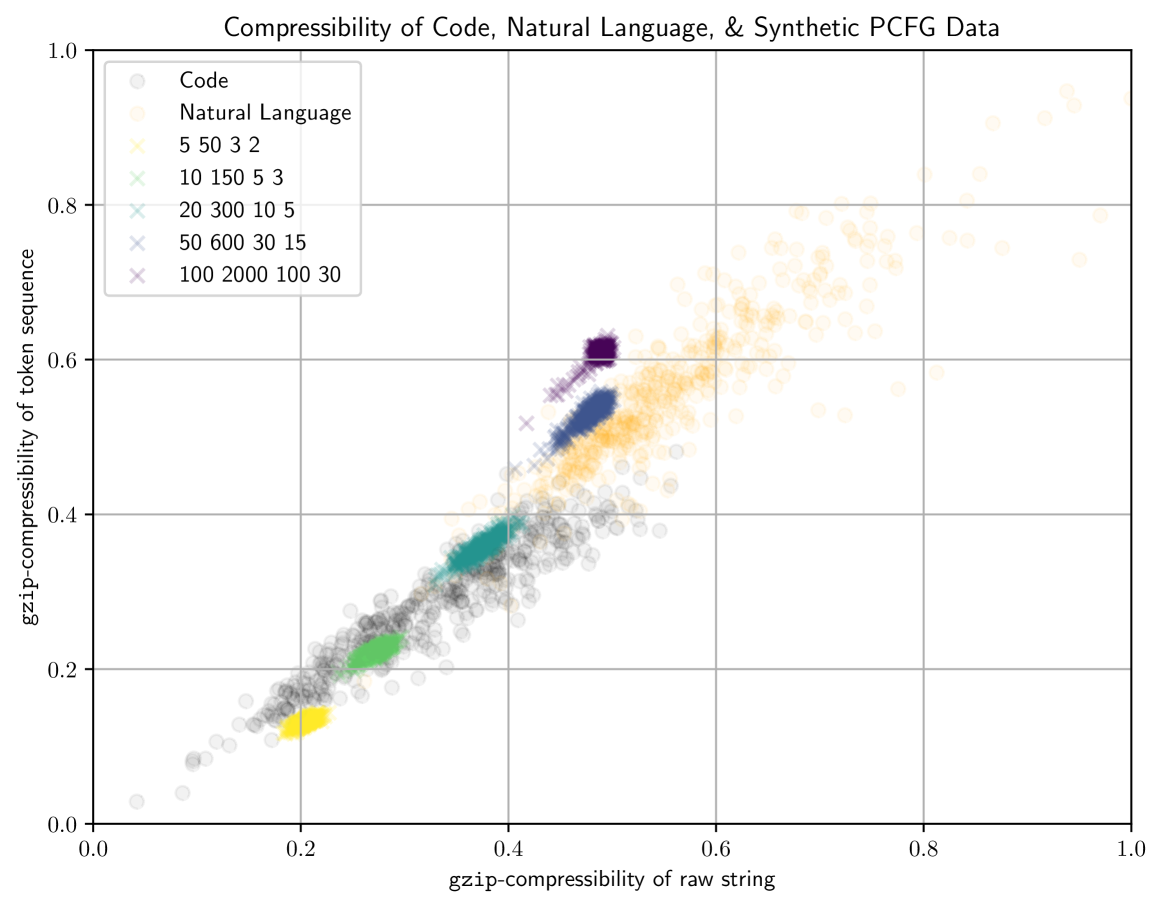
Past work has established scaling laws that predict the performance of a neural language model (LM) as a function of its parameter count and the number of tokens it's trained on, enabling optimal allocation of a fixed compute budget. Are these scaling laws agnostic to training data as some prior work suggests? We generate training datasets of varying complexities by modulating the syntactic properties of a PCFG, finding that 1) scaling laws are sensitive to differences in data complexity and that 2) gzip, a compression algorithm, is an effective predictor of how data complexity impacts scaling properties. We propose a new data-dependent scaling law for LM's that accounts for the training data's gzip-compressibility; its compute-optimal frontier increases in dataset size preference (over parameter count preference) as training data becomes harder to compress.
Read more5/28/2024
📈
0
Lossless and Near-Lossless Compression for Foundation Models
Moshik Hershcovitch, Leshem Choshen, Andrew Wood, Ilias Enmouri, Peter Chin, Swaminathan Sundararaman, Danny Harnik
With the growth of model sizes and scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast literature about reducing model sizes, we investigate a more traditional type of compression -- one that compresses the model to a smaller form and is coupled with a decompression algorithm that returns it to its original size -- namely lossless compression. Somewhat surprisingly, we show that such lossless compression can gain significant network and storage reduction on popular models, at times reducing over $50%$ of the model size. We investigate the source of model compressibility, introduce compression variants tailored for models and categorize models to compressibility groups. We also introduce a tunable lossy compression technique that can further reduce size even on the less compressible models with little to no effect on the model accuracy. We estimate that these methods could save over an ExaByte per month of network traffic downloaded from a large model hub like HuggingFace.
Read more4/24/2024
0
Hierarchical Autoencoder-based Lossy Compression for Large-scale High-resolution Scientific Data
Hieu Le, Jian Tao
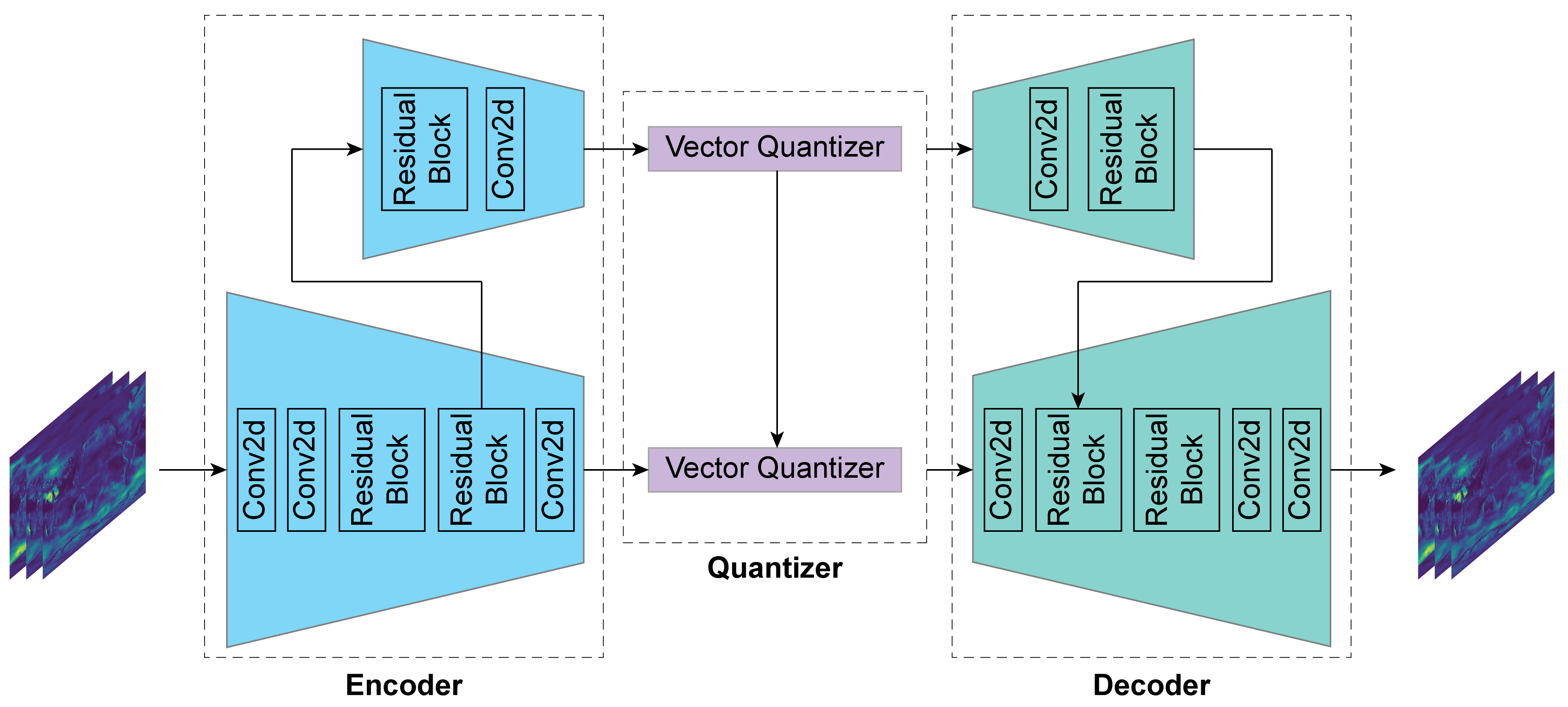
Lossy compression has become an important technique to reduce data size in many domains. This type of compression is especially valuable for large-scale scientific data, whose size ranges up to several petabytes. Although Autoencoder-based models have been successfully leveraged to compress images and videos, such neural networks have not widely gained attention in the scientific data domain. Our work presents a neural network that not only significantly compresses large-scale scientific data, but also maintains high reconstruction quality. The proposed model is tested with scientific benchmark data available publicly and applied to a large-scale high-resolution climate modeling data set. Our model achieves a compression ratio of 140 on several benchmark data sets without compromising the reconstruction quality. 2D simulation data from the High-Resolution Community Earth System Model (CESM) Version 1.3 over 500 years are also being compressed with a compression ratio of 200 while the reconstruction error is negligible for scientific analysis.
Read more5/8/2024