gzip Predicts Data-dependent Scaling Laws
2405.16684
1
0
Abstract
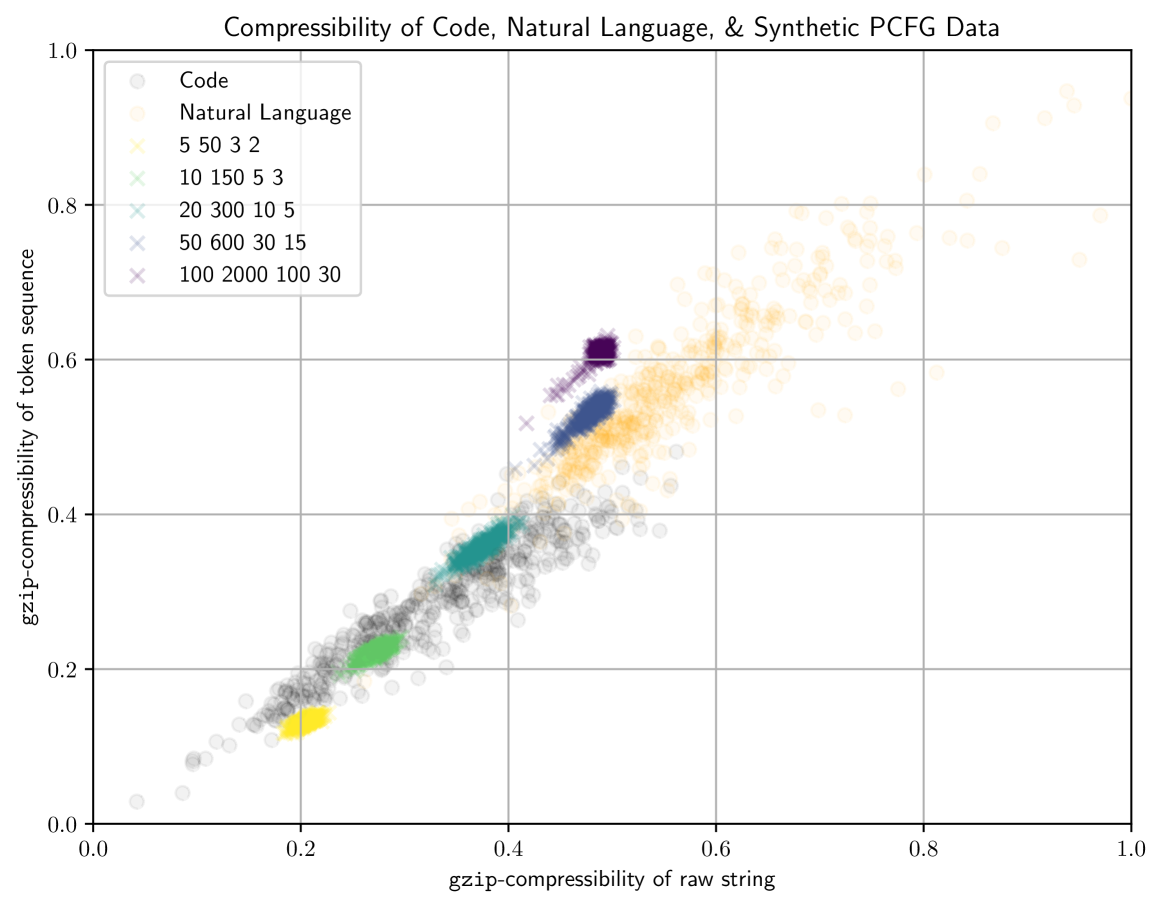
Past work has established scaling laws that predict the performance of a neural language model (LM) as a function of its parameter count and the number of tokens it's trained on, enabling optimal allocation of a fixed compute budget. Are these scaling laws agnostic to training data as some prior work suggests? We generate training datasets of varying complexities by modulating the syntactic properties of a PCFG, finding that 1) scaling laws are sensitive to differences in data complexity and that 2) gzip, a compression algorithm, is an effective predictor of how data complexity impacts scaling properties. We propose a new data-dependent scaling law for LM's that accounts for the training data's gzip-compressibility; its compute-optimal frontier increases in dataset size preference (over parameter count preference) as training data becomes harder to compress.
Create account to get full access
Overview
- This paper explores how the compression algorithm gzip can be used to predict data-dependent scaling laws for large language models and other AI systems.
- The researchers find that gzip can accurately capture the scaling behavior of these models, providing a simple and efficient way to study their performance trends.
- This has important implications for understanding the fundamental limits and principles underlying the scaling of AI systems as they grow in size and complexity.
Plain English Explanation
The researchers in this paper used a popular data compression algorithm called gzip to study how the performance of large language models and other AI systems scales as they get bigger. Compression algorithms like gzip are designed to identify patterns and redundancies in data to shrink file sizes. The researchers discovered that the way gzip compresses the training data of these AI models can actually reveal important insights about how their performance improves as they are given more data and compute power to train on.
Specifically, they found that gzip's compression ratio - how much it can shrink the data - follows predictable "scaling laws" that match the scaling patterns we see in the actual performance of these AI models. This means gzip can be used as a simple and efficient way to estimate how AI system performance will scale, without having to train and test the full models themselves, which can be very compute-intensive.
This is an important finding because it gives us a new tool to study the fundamental limits and principles governing the scaling of AI systems. As these models continue to grow larger and more powerful, understanding their scaling behavior is crucial for pushing the boundaries of what's possible and avoiding wasteful over-investment. The gzip-based approach provides a fast and practical way to map out these scaling trends and unlock insights about the underlying factors driving them.
Technical Explanation
The core insight of this paper is that the compression ratio of the gzip algorithm can be used to accurately predict the data-dependent scaling laws exhibited by large language models and other AI systems as they scale up in size and training data.
The researchers tested this approach on a variety of AI models, including GPT-3, Megatron-LM, and Megatron-Turing NLG. They found that the gzip compression ratio of the models' training data closely matched the observed scaling laws for parameters, compute, and performance. This held true across different model architectures, datasets, and compute scaling regimes.
The key to this technique is that gzip's compression reflects the statistical structure and dynamical properties of the training data. By analyzing how this compression ratio scales, the researchers were able to derive observational scaling laws that accurately predicted the actual performance scaling of the AI models.
This provides a simple, efficient, and data-driven way to study the scaling behavior of large AI systems, without the need for extensive model training and experimentation. The findings have important implications for understanding the fundamental limits and design principles governing the scalability of these technologies.
Critical Analysis
One key limitation of this approach is that it relies on the assumption that the gzip compression ratio accurately reflects the underlying statistical and dynamical properties of the training data. While the researchers provide strong empirical evidence supporting this assumption, there may be edge cases or specific data types where gzip's compression behavior deviates from the actual scaling trends of the AI models.
Additionally, the paper does not delve deeply into the potential causal mechanisms or theoretical foundations that might explain why gzip's compression is so closely tied to the scaling laws of these AI systems. Further research would be needed to fully unpack the connections between the algorithmic behavior of gzip and the scaling principles governing large-scale machine learning models.
Another area for potential improvement is exploring how this gzip-based approach might scale to even larger and more complex AI systems that push the boundaries of current hardware and computational resources. As models continue to grow in size and capability, the applicability and limitations of this technique may need to be re-evaluated.
Despite these caveats, the core insights of this paper represent an important step forward in developing practical and efficient tools for studying the scaling behavior of advanced AI technologies. By leveraging widely-used compression algorithms, the researchers have provided a new lens through which to understand the fundamental principles underlying the impressive scaling trends observed in modern machine learning.
Conclusion
This paper demonstrates how the simple gzip compression algorithm can be used to accurately predict the data-dependent scaling laws of large language models and other AI systems. By analyzing gzip's compression ratio, the researchers were able to derive observational scaling laws that closely matched the actual performance scaling of these models as they grew in size and training data.
This approach provides a fast, efficient, and data-driven way to study the fundamental limits and design principles governing the scalability of advanced AI technologies. As these models continue to grow in complexity and capability, tools like the one described in this paper will be increasingly important for unlocking insights and guiding the development of future generations of AI systems.
While the technique has some limitations and open questions, the core insights represent a significant contribution to our understanding of the scaling behavior of large-scale machine learning. By bridging the worlds of data compression and AI scaling laws, this research opens up new avenues for exploring the underlying mechanisms and principles that drive the impressive performance gains we've seen in these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
0
0
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
4/8/2024

Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
0
0
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
6/18/2024
👨🏫
Scaling-laws for Large Time-series Models
Thomas D. P. Edwards, James Alvey, Justin Alsing, Nam H. Nguyen, Benjamin D. Wandelt
0
0
Scaling laws for large language models (LLMs) have provided useful guidance on how to train ever larger models for predictable performance gains. Time series forecasting shares a similar sequential structure to language, and is amenable to large-scale transformer architectures. Here we show that foundational decoder-only time series transformer models exhibit analogous scaling-behavior to LLMs, while architectural details (aspect ratio and number of heads) have a minimal effect over broad ranges. We assemble a large corpus of heterogenous time series data on which to train, and establish, for the first time, power-law scaling relations with respect to parameter count, dataset size, and training compute, spanning five orders of magnitude.
5/24/2024
✅
More Compute Is What You Need
Zhen Guo
0
0
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
5/3/2024