Lossless and Near-Lossless Compression for Foundation Models

0
📈
Sign in to get full access
Overview
- As deep learning models become larger and more widely deployed, they place a significant burden on the infrastructure, requiring more network bandwidth and storage space.
- While much research has focused on reducing model sizes, this paper investigates the use of lossless compression techniques to further optimize storage and network requirements.
- The authors show that lossless compression can significantly reduce the size of popular models, sometimes by over 50%.
- They also introduce a tunable lossy compression technique that can further reduce the size of less compressible models with minimal impact on accuracy.
- The authors estimate these methods could save over an ExaByte per month of network traffic downloaded from large model hubs like HuggingFace.
Plain English Explanation
Deep learning models are getting increasingly large and complex, which means they require more storage space and network bandwidth to use and distribute. While researchers have explored ways to make these models smaller, this paper looks at a different approach: using lossless compression.
Lossless compression is a technique that shrinks the size of a file without losing any of the original information. The authors found that when they applied lossless compression to popular deep learning models, they were able to reduce the model size by over 50% in some cases. This could lead to significant savings in the amount of network traffic and storage needed to work with these large models, especially for organizations that host and distribute them, like HuggingFace.
The paper also introduces a new type of "tunable lossy compression" that can further reduce the size of models that are less compressible using the lossless approach, while still maintaining the model's accuracy. The authors estimate that using these compression techniques could save over an ExaByte (that's a 1 followed by 18 zeros!) of network traffic per month.
Technical Explanation
The paper explores the use of lossless compression techniques to reduce the storage and network requirements of large deep learning models. Lossless compression works by encoding the original data in a more compact form, allowing it to be reconstructed exactly without any loss of information.
The authors investigate the compressibility of popular deep learning models, including transformer-based language models, and find that significant size reductions (over 50% in some cases) can be achieved through lossless compression. They attribute this to the inherent redundancy in the weights and parameters of these models.
To further optimize model size, the researchers introduce a "tunable lossy compression" technique that can provide additional reductions for models that are less compressible using the lossless approach. This lossy compression method selectively discards information that has a minimal impact on the model's accuracy, allowing for greater compression ratios.
The authors evaluate their compression methods on a diverse set of deep learning models and datasets, including those used in the survey of transformer compression techniques and the study on the effects of making small models smaller. They also compare their results to other error-bounded lossy compression techniques for scientific datasets and the GWLZ group-wise learning-based lossy compression method.
Critical Analysis
The paper presents a compelling case for using lossless and tunable lossy compression to optimize the storage and network requirements of large deep learning models. The authors provide a thorough evaluation of their techniques across a diverse set of models and datasets, and the reported size reductions are significant.
One potential limitation of the work is that the compression methods may not be applicable to all types of deep learning models, especially those with very specialized architectures or training processes. The authors acknowledge this and suggest that further research is needed to understand the compressibility of different model classes.
Another area for further investigation is the impact of these compression techniques on the inference performance of the models. While the authors claim that the tunable lossy compression method has minimal impact on accuracy, there may be other performance considerations, such as inference latency or energy consumption, that should be explored.
Overall, this research represents an important contribution to the field of deep learning model optimization, and the methods described could have significant practical implications for organizations that develop, deploy, and distribute large-scale AI models, such as those discussed in the paper on enhancing inference efficiency.
Conclusion
This paper demonstrates that lossless and tunable lossy compression techniques can significantly reduce the storage and network requirements of large deep learning models, sometimes by over 50%. The authors' findings have important practical implications for organizations that work with and distribute these models, as the proposed methods could save vast amounts of network bandwidth and storage space.
The research also highlights the inherent redundancy in the weights and parameters of deep learning models, suggesting that there may be additional opportunities for optimization beyond just model compression. Overall, this work represents an important step forward in making large-scale AI models more efficient and accessible to a wider range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Lossless and Near-Lossless Compression for Foundation Models
Moshik Hershcovitch, Leshem Choshen, Andrew Wood, Ilias Enmouri, Peter Chin, Swaminathan Sundararaman, Danny Harnik
With the growth of model sizes and scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast literature about reducing model sizes, we investigate a more traditional type of compression -- one that compresses the model to a smaller form and is coupled with a decompression algorithm that returns it to its original size -- namely lossless compression. Somewhat surprisingly, we show that such lossless compression can gain significant network and storage reduction on popular models, at times reducing over $50%$ of the model size. We investigate the source of model compressibility, introduce compression variants tailored for models and categorize models to compressibility groups. We also introduce a tunable lossy compression technique that can further reduce size even on the less compressible models with little to no effect on the model accuracy. We estimate that these methods could save over an ExaByte per month of network traffic downloaded from a large model hub like HuggingFace.
Read more4/24/2024
🌿
0
Compressed models are NOT miniature versions of large models
Rohit Raj Rai, Rishant Pal, Amit Awekar
Large neural models are often compressed before deployment. Model compression is necessary for many practical reasons, such as inference latency, memory footprint, and energy consumption. Compressed models are assumed to be miniature versions of corresponding large neural models. However, we question this belief in our work. We compare compressed models with corresponding large neural models using four model characteristics: prediction errors, data representation, data distribution, and vulnerability to adversarial attack. We perform experiments using the BERT-large model and its five compressed versions. For all four model characteristics, compressed models significantly differ from the BERT-large model. Even among compressed models, they differ from each other on all four model characteristics. Apart from the expected loss in model performance, there are major side effects of using compressed models to replace large neural models.
Read more7/19/2024

0
Scaling Training Data with Lossy Image Compression
Katherine L. Mentzer, Andrea Montanari
Empirically-determined scaling laws have been broadly successful in predicting the evolution of large machine learning models with training data and number of parameters. As a consequence, they have been useful for optimizing the allocation of limited resources, most notably compute time. In certain applications, storage space is an important constraint, and data format needs to be chosen carefully as a consequence. Computer vision is a prominent example: images are inherently analog, but are always stored in a digital format using a finite number of bits. Given a dataset of digital images, the number of bits $L$ to store each of them can be further reduced using lossy data compression. This, however, can degrade the quality of the model trained on such images, since each example has lower resolution. In order to capture this trade-off and optimize storage of training data, we propose a `storage scaling law' that describes the joint evolution of test error with sample size and number of bits per image. We prove that this law holds within a stylized model for image compression, and verify it empirically on two computer vision tasks, extracting the relevant parameters. We then show that this law can be used to optimize the lossy compression level. At given storage, models trained on optimally compressed images present a significantly smaller test error with respect to models trained on the original data. Finally, we investigate the potential benefits of randomizing the compression level.
Read more7/26/2024
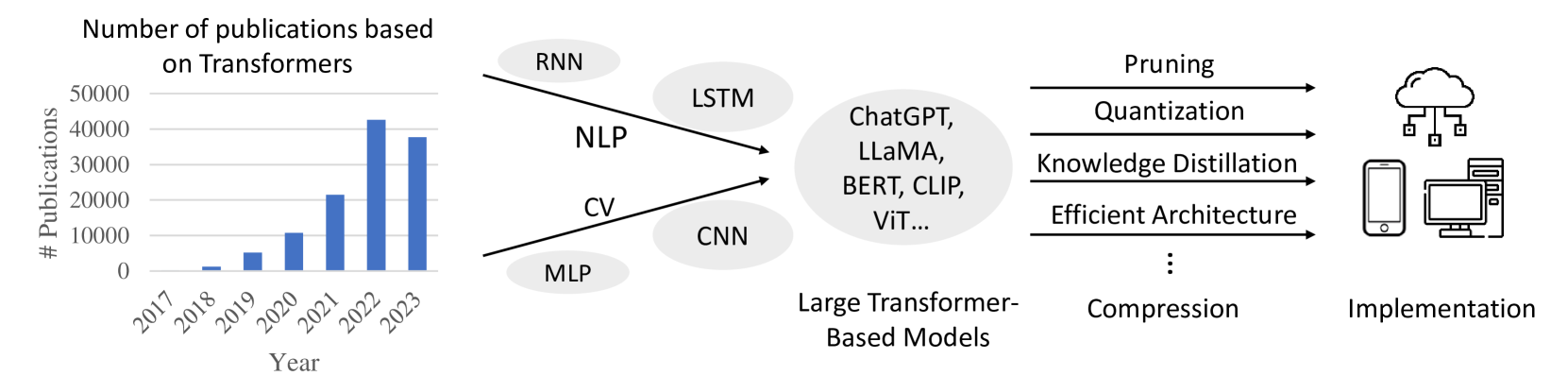
4
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
Read more4/9/2024