Scheduled Curiosity-Deep Dyna-Q: Efficient Exploration for Dialog Policy Learning

0

Sign in to get full access
Overview
- This paper introduces Scheduled Curiosity-Deep Dyna-Q (SC-DDQ), an efficient exploration algorithm for dialog policy learning.
- The approach combines the strengths of Deep Dyna-Q and curiosity-driven exploration to enable effective learning of dialog policies.
- The key idea is to schedule the tradeoff between exploitation and exploration over time, starting with more exploration and gradually shifting towards exploitation as the agent learns.
Plain English Explanation
Imagine you're trying to teach a robot how to have a conversation. The robot needs to learn what to say and when, but it also needs to try out new things to figure out what works best. Scheduled Curiosity-Deep Dyna-Q is a way to help the robot learn efficiently.
At first, the robot is very curious and tries all sorts of random things to see what happens. This helps it discover new ways of talking that might work well. Over time, the robot starts to understand what kinds of responses are effective, so it focuses more on using those. The balance between trying new things and using what it's already learned is carefully scheduled to help the robot learn as quickly and effectively as possible.
Technical Explanation
The paper proposes the Scheduled Curiosity-Deep Dyna-Q (SC-DDQ) algorithm, which builds on the Deep Dyna-Q framework for dialog policy learning. SC-DDQ incorporates a curiosity-driven exploration mechanism that is scheduled over time.
The key components of SC-DDQ are:
- A deep neural network that models the dialog policy and learns to map dialog states to actions.
- A model-based component that learns a transition model of the dialog environment, allowing the agent to simulate interactions and rehearse policies.
- A curiosity-driven exploration bonus that encourages the agent to explore states and actions that are novel or uncertain.
- A scheduled weighting that gradually reduces the exploration bonus over time, shifting the agent's behavior from exploration to exploitation as the policy learning progresses.
The paper demonstrates the effectiveness of SC-DDQ through experiments on dialog policy learning tasks, showing improved sample efficiency and final performance compared to baseline approaches.
Critical Analysis
The paper provides a compelling approach to addressing the exploration-exploitation tradeoff in dialog policy learning, a key challenge in developing conversational AI systems. The scheduled curiosity-driven exploration mechanism seems well-motivated and the experimental results are promising.
However, the paper does not extensively discuss potential limitations or caveats of the proposed method. For example, the approach may be sensitive to hyperparameter choices for the exploration scheduling, and its performance may depend on the specific characteristics of the dialog environment and task. Further research is needed to better understand the robustness and generalizability of SC-DDQ.
Additionally, the paper focuses primarily on the technical details of the algorithm and does not delve deeply into the broader implications or ethical considerations of developing more capable dialog systems. As conversational AI becomes more sophisticated, it will be important to consider issues such as bias, privacy, and the potential for misuse.
Conclusion
This paper introduces the Scheduled Curiosity-Deep Dyna-Q (SC-DDQ) algorithm, which combines the strengths of Deep Dyna-Q and curiosity-driven exploration to enable efficient learning of dialog policies. By carefully scheduling the tradeoff between exploration and exploitation, SC-DDQ demonstrates improved sample efficiency and performance on dialog policy learning tasks.
While the technical merits of the approach are compelling, further research is needed to better understand its limitations and broader implications. As conversational AI systems become more advanced, it will be crucial to consider not only their technical capabilities but also their societal impact and ethical considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scheduled Curiosity-Deep Dyna-Q: Efficient Exploration for Dialog Policy Learning
Xuecheng Niu, Akinori Ito, Takashi Nose
Training task-oriented dialog agents based on reinforcement learning is time-consuming and requires a large number of interactions with real users. How to grasp dialog policy within limited dialog experiences remains an obstacle that makes the agent training process less efficient. In addition, most previous frameworks start training by randomly choosing training samples, which differs from the human learning method and hurts the efficiency and stability of training. Therefore, we propose Scheduled Curiosity-Deep Dyna-Q (SC-DDQ), a curiosity-driven curriculum learning framework based on a state-of-the-art model-based reinforcement learning dialog model, Deep Dyna-Q (DDQ). Furthermore, we designed learning schedules for SC-DDQ and DDQ, respectively, following two opposite training strategies: classic curriculum learning and its reverse version. Our results show that by introducing scheduled learning and curiosity, the new framework leads to a significant improvement over the DDQ and Deep Q-learning(DQN). Surprisingly, we found that traditional curriculum learning was not always effective. Specifically, according to the experimental results, the easy-first and difficult-first strategies are more suitable for SC-DDQ and DDQ. To analyze our results, we adopted the entropy of sampled actions to depict action exploration and found that training strategies with high entropy in the first stage and low entropy in the last stage lead to better performance.
Read more5/21/2024
0
Mitigating the Stability-Plasticity Dilemma in Adaptive Train Scheduling with Curriculum-Driven Continual DQN Expansion
Achref Jaziri, Etienne Kunzel, Visvanathan Ramesh
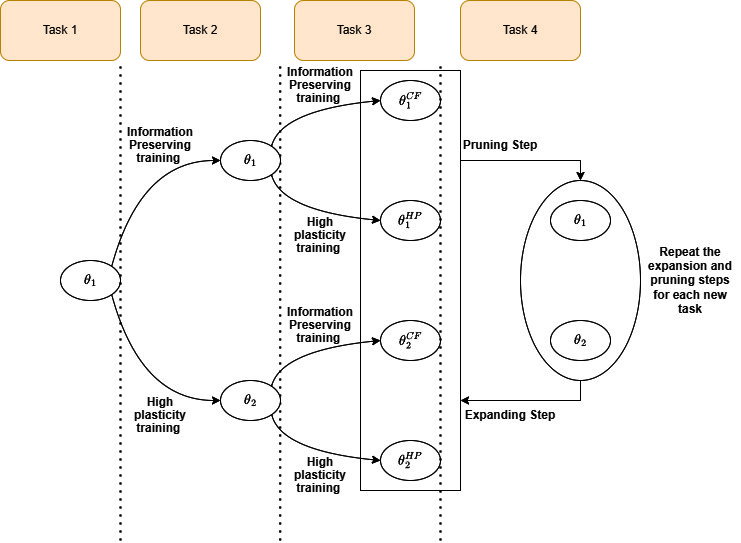
A continual learning agent builds on previous experiences to develop increasingly complex behaviors by adapting to non-stationary and dynamic environments while preserving previously acquired knowledge. However, scaling these systems presents significant challenges, particularly in balancing the preservation of previous policies with the adaptation of new ones to current environments. This balance, known as the stability-plasticity dilemma, is especially pronounced in complex multi-agent domains such as the train scheduling problem, where environmental and agent behaviors are constantly changing, and the search space is vast. In this work, we propose addressing these challenges in the train scheduling problem using curriculum learning. We design a curriculum with adjacent skills that build on each other to improve generalization performance. Introducing a curriculum with distinct tasks introduces non-stationarity, which we address by proposing a new algorithm: Continual Deep Q-Network (DQN) Expansion (CDE). Our approach dynamically generates and adjusts Q-function subspaces to handle environmental changes and task requirements. CDE mitigates catastrophic forgetting through EWC while ensuring high plasticity using adaptive rational activation functions. Experimental results demonstrate significant improvements in learning efficiency and adaptability compared to RL baselines and other adapted methods for continual learning, highlighting the potential of our method in managing the stability-plasticity dilemma in the adaptive train scheduling setting.
Read more8/20/2024
🤿
0
Quantum Deep Reinforcement Learning for Robot Navigation Tasks
Hans Hohenfeld, Dirk Heimann, Felix Wiebe, Frank Kirchner
We utilize hybrid quantum deep reinforcement learning to learn navigation tasks for a simple, wheeled robot in simulated environments of increasing complexity. For this, we train parameterized quantum circuits (PQCs) with two different encoding strategies in a hybrid quantum-classical setup as well as a classical neural network baseline with the double deep Q network (DDQN) reinforcement learning algorithm. Quantum deep reinforcement learning (QDRL) has previously been studied in several relatively simple benchmark environments, mainly from the OpenAI gym suite. However, scaling behavior and applicability of QDRL to more demanding tasks closer to real-world problems e. g., from the robotics domain, have not been studied previously. Here, we show that quantum circuits in hybrid quantum-classic reinforcement learning setups are capable of learning optimal policies in multiple robotic navigation scenarios with notably fewer trainable parameters compared to a classical baseline. Across a large number of experimental configurations, we find that the employed quantum circuits outperform the classical neural network baselines when equating for the number of trainable parameters. Yet, the classical neural network consistently showed better results concerning training times and stability, with at least one order of magnitude of trainable parameters more than the best-performing quantum circuits. However, validating the robustness of the learning methods in a large and dynamic environment, we find that the classical baseline produces more stable and better performing policies overall.
Read more6/26/2024

0
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Alexander Rutherford, Michael Beukman, Timon Willi, Bruno Lacerda, Nick Hawes, Jakob Foerster
What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
Read more8/30/2024