SE3D: A Framework For Saliency Method Evaluation In 3D Imaging

0
🚀
Sign in to get full access
Overview
- Deep learning models have dominated 2D imaging tasks for over a decade.
- These models are now being applied to 3D imaging, like LIDAR, MRI, and CT scans, with important implications for fields like autonomous driving and medical imaging.
- Explaining the decisions of these 3D Convolutional Neural Networks (3D CNNs) is crucial, but existing explainable AI methods often fall short.
- A key challenge is the lack of a benchmark to assess 3D saliency methods, which are used to explain 3D CNN models.
Plain English Explanation
Deep learning models have become incredibly powerful at analyzing 2D images, like photos. For over 10 years, these advanced artificial intelligence models have been dominating tasks involving 2D images, like identifying objects in a picture.
Now, these deep learning models are starting to be used for 3D data as well. 3D data comes from technologies like LIDAR (which uses lasers to map the 3D structure of the world), medical scans like MRI and CT, and other 3D imaging methods. This 3D data has important applications in fields like self-driving cars and medical imaging.
When these deep learning models are used for critical tasks like driving cars or diagnosing medical conditions, it's very important to be able to explain how the models are making their decisions. This is the goal of explainable AI - developing methods to understand and interpret the inner workings of AI systems.
However, existing explainable AI methods often struggle when it comes to 3D deep learning models. There hasn't been a good way to quantitatively assess the quality of the explanations provided for 3D deep learning models. This makes it hard to improve the explanations and ensure these powerful 3D models are being used safely and responsibly.
Technical Explanation
To address this gap, the researchers propose SE3D, a framework for evaluating the quality of saliency methods used to explain 3D Convolutional Neural Networks (3D CNNs). Saliency methods are a type of explainable AI technique that highlight the most important parts of the input data that are driving a model's predictions.
The key innovations in SE3D are:
- Modifications to existing 3D datasets like ShapeNet, ScanNet, and BraTS to enable evaluation of 3D saliency methods.
- New evaluation metrics to quantitatively assess the quality of saliency explanations for 3D CNNs.
Using SE3D, the researchers evaluate both state-of-the-art 3D saliency methods as well as extensions of 2D saliency methods to the 3D domain. Their experiments show that current 3D saliency methods do not provide explanations of sufficient quality, and that there is significant room for improvement in explaining 3D deep learning models.
Critical Analysis
The researchers identify a crucial gap in the explainable AI literature - the lack of benchmarks and evaluation methods for 3D saliency. Without a way to rigorously assess the quality of 3D saliency explanations, it is difficult to develop improved methods and ensure the safe deployment of 3D deep learning models in high-stakes domains.
The SE3D framework proposed by the researchers is an important step forward. By modifying existing 3D datasets and defining new evaluation metrics, they provide a much-needed tool for the research community. However, the researchers acknowledge that SE3D has limitations, such as the reliance on synthetic data, and call for the development of more diverse 3D datasets and saliency evaluation approaches.
Additionally, the researchers' findings that current 3D saliency methods are lacking in quality highlight the significant challenges in explaining the inner workings of 3D deep learning models. Developing robust and trustworthy explanations for these powerful, but complex, models will be critical as they become more widely adopted in domains like autonomous driving and medical imaging.
Conclusion
This paper identifies a crucial gap in the explainable AI literature - the lack of benchmarks and evaluation methods for assessing the quality of saliency explanations for 3D deep learning models. The researchers propose the SE3D framework to address this issue, providing a way to quantitatively evaluate 3D saliency methods.
The findings that current 3D saliency methods fall short underscores the significant challenges in making 3D deep learning models more transparent and interpretable. As these models become increasingly important in high-stakes domains, developing robust and trustworthy explanations will be essential for ensuring their safe and responsible deployment. The SE3D framework is an important step forward, but more work is needed to improve 3D saliency methods and build greater trust in these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
SE3D: A Framework For Saliency Method Evaluation In 3D Imaging
Mariusz Wi'sniewski, Loris Giulivi, Giacomo Boracchi
For more than a decade, deep learning models have been dominating in various 2D imaging tasks. Their application is now extending to 3D imaging, with 3D Convolutional Neural Networks (3D CNNs) being able to process LIDAR, MRI, and CT scans, with significant implications for fields such as autonomous driving and medical imaging. In these critical settings, explaining the model's decisions is fundamental. Despite recent advances in Explainable Artificial Intelligence, however, little effort has been devoted to explaining 3D CNNs, and many works explain these models via inadequate extensions of 2D saliency methods. One fundamental limitation to the development of 3D saliency methods is the lack of a benchmark to quantitatively assess them on 3D data. To address this issue, we propose SE3D: a framework for Saliency method Evaluation in 3D imaging. We propose modifications to ShapeNet, ScanNet, and BraTS datasets, and evaluation metrics to assess saliency methods for 3D CNNs. We evaluate both state-of-the-art saliency methods designed for 3D data and extensions of popular 2D saliency methods to 3D. Our experiments show that 3D saliency methods do not provide explanations of sufficient quality, and that there is margin for future improvements and safer applications of 3D CNNs in critical fields.
Read more5/24/2024
0
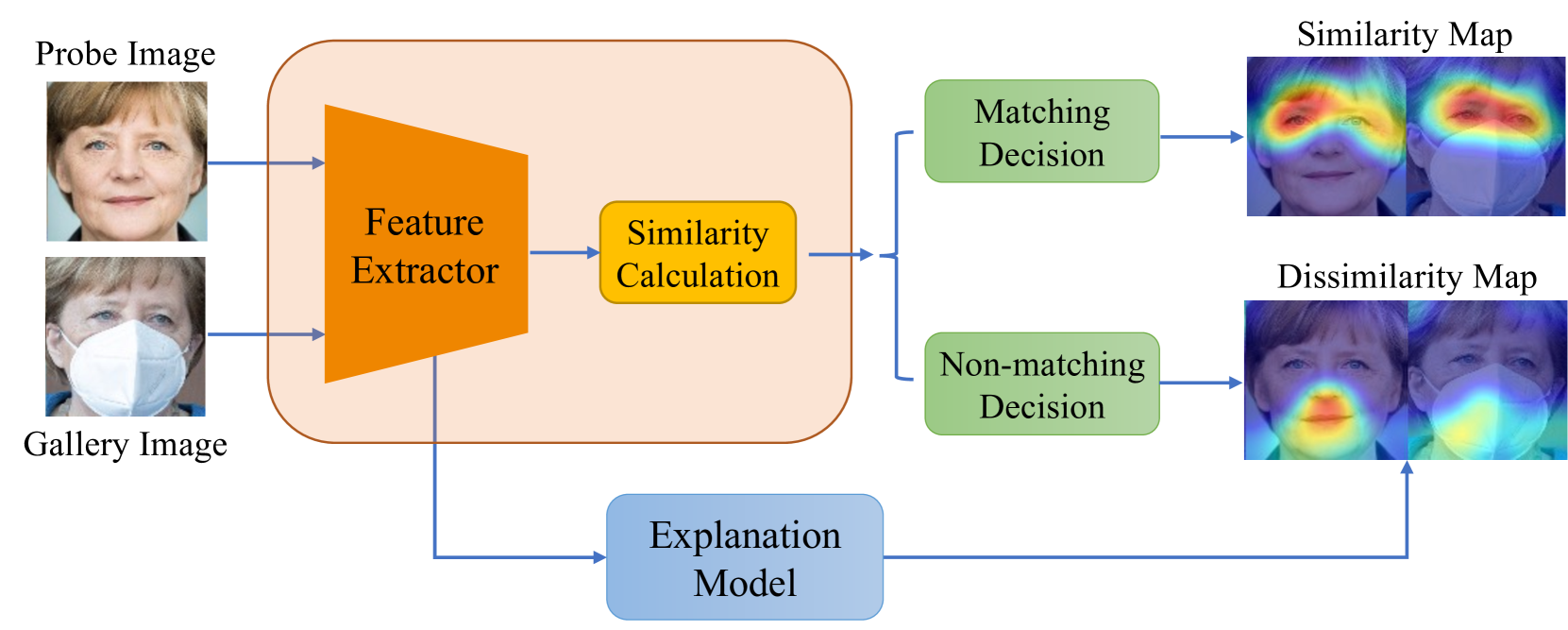
Towards A Comprehensive Visual Saliency Explanation Framework for AI-based Face Recognition Systems
Yuhang Lu, Zewei Xu, Touradj Ebrahimi
Over recent years, deep convolutional neural networks have significantly advanced the field of face recognition techniques for both verification and identification purposes. Despite the impressive accuracy, these neural networks are often criticized for lacking explainability. There is a growing demand for understanding the decision-making process of AI-based face recognition systems. Some studies have investigated the use of visual saliency maps as explanations, but they have predominantly focused on the specific face verification case. The discussion on more general face recognition scenarios and the corresponding evaluation methodology for these explanations have long been absent in current research. Therefore, this manuscript conceives a comprehensive explanation framework for face recognition tasks. Firstly, an exhaustive definition of visual saliency map-based explanations for AI-based face recognition systems is provided, taking into account the two most common recognition situations individually, i.e., face verification and identification. Secondly, a new model-agnostic explanation method named CorrRISE is proposed to produce saliency maps, which reveal both the similar and dissimilar regions between any given face images. Subsequently, the explanation framework conceives a new evaluation methodology that offers quantitative measurement and comparison of the performance of general visual saliency explanation methods in face recognition. Consequently, extensive experiments are carried out on multiple verification and identification scenarios. The results showcase that CorrRISE generates insightful saliency maps and demonstrates superior performance, particularly in similarity maps in comparison with the state-of-the-art explanation approaches.
Read more7/9/2024
👁️
0
An explainable three dimension framework to uncover learning patterns: A unified look in variable sulci recognition
Michail Mamalakis, Heloise de Vareilles, Atheer AI-Manea, Samantha C. Mitchell, Ingrid Arartz, Lynn Egeland Morch-Johnsen, Jane Garrison, Jon Simons, Pietro Lio, John Suckling, Graham Murray
The significant features identified in a representative subset of the dataset during the learning process of an artificial intelligence model are referred to as a 'global' explanation. Three-dimensional (3D) global explanations are crucial in neuroimaging where a complex representational space demands more than basic two-dimensional interpretations. Curently, studies in the literature lack accurate, low-complexity, and 3D global explanations in neuroimaging and beyond. To fill this gap, we develop a novel explainable artificial intelligence (XAI) 3D-Framework that provides robust, faithful, and low-complexity global explanations. We evaluated our framework on various 3D deep learning networks trained, validated, and tested on a well-annotated cohort of 596 MRI images. The focus of detection was on the presence or absence of the paracingulate sulcus, a highly variable feature of brain topology associated with symptoms of psychosis. Our proposed 3D-Framework outperformed traditional XAI methods in terms of faithfulness for global explanations. As a result, these explanations uncovered new patterns that not only enhance the credibility and reliability of the training process but also reveal the broader developmental landscape of the human cortex. Our XAI 3D-Framework proposes for the first time, a way to utilize global explanations to discover the context in which detection of specific features are embedded, opening our understanding of normative brain development and atypical trajectories that can lead to the emergence of mental illness.
Read more7/9/2024
0
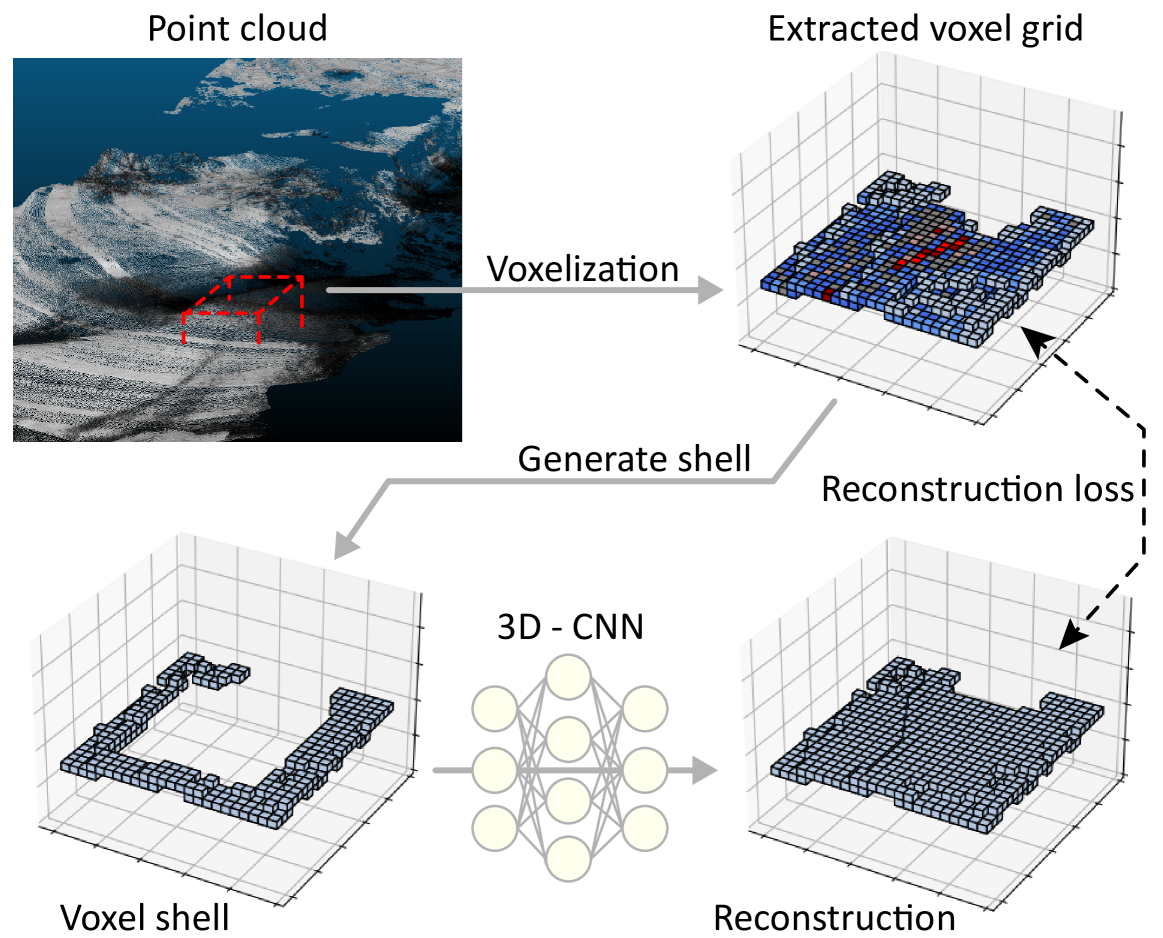
Evaluating saliency scores in point clouds of natural environments by learning surface anomalies
Reuma Arav, Dennis Wittich, Franz Rottensteiner
In recent years, three-dimensional point clouds are used increasingly to document natural environments. Each dataset contains a diverse set of objects, at varying shapes and sizes, distributed throughout the data and intricately intertwined with the topography. Therefore, regions of interest are difficult to find and consequent analyses become a challenge. Inspired from visual perception principles, we propose to differentiate objects of interest from the cluttered environment by evaluating how much they stand out from their surroundings, i.e., their geometric salience. Previous saliency detection approaches suggested mostly handcrafted attributes for the task. However, such methods fail when the data are too noisy or have high levels of texture. Here we propose a learning-based mechanism that accommodates noise and textured surfaces. We assume that within the natural environment any change from the prevalent surface would suggest a salient object. Thus, we first learn the underlying surface and then search for anomalies within it. Initially, a deep neural network is trained to reconstruct the surface. Regions where the reconstructed part deviates significantly from the original point cloud yield a substantial reconstruction error, signifying an anomaly, i.e., saliency. We demonstrate the effectiveness of the proposed approach by searching for salient features in various natural scenarios, which were acquired by different acquisition platforms. We show the strong correlation between the reconstruction error and salient objects.
Read more8/27/2024