URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
2406.04660
0
0
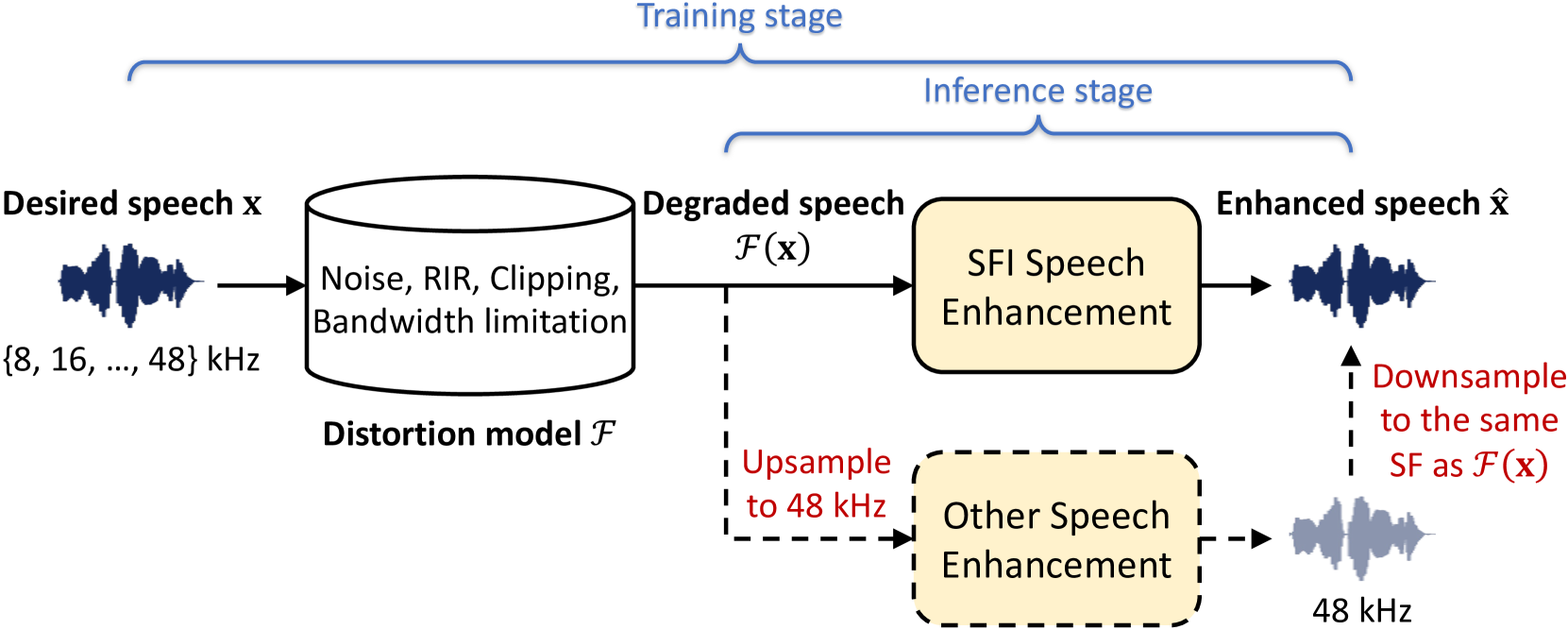
Abstract
The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
Create account to get full access
Overview
- This paper introduces the URGENT challenge, which aims to address the key issues of universality, robustness, and generalizability in speech enhancement systems.
- The authors highlight the importance of developing speech enhancement models that can perform well across diverse environments, accents, and noise conditions, rather than just optimizing for specific benchmarks.
- The paper outlines the key objectives and evaluation criteria for the URGENT challenge, providing a roadmap for researchers to advance the field of speech enhancement.
Plain English Explanation
The URGENT challenge is an important effort to improve speech enhancement systems, which are used to enhance the quality of speech recordings by filtering out background noise and other distortions.
Beyond Performance Plateaus: A Comprehensive Study of Scalability in Speech Enhancement and Speech Enhancement with Deep Learning: An Architecture for Efficient Edge Deployment have shown the potential of deep learning techniques to achieve state-of-the-art performance in speech enhancement. However, these models often struggle to generalize well to diverse real-world conditions, such as different accents, environments, and noise types.
The URGENT challenge aims to address this by encouraging researchers to develop speech enhancement models that are universal (work well across diverse scenarios), robust (maintain performance even in challenging conditions), and generalizable (can adapt to new environments without retraining). This is crucial for making speech enhancement technologies widely accessible and reliable, especially for applications like Universally Universal Spoken Language Understanding for Diverse Tasks and Advancing African-Accented Speech Recognition with Epistemic Uncertainty.
By setting clear evaluation criteria and providing a benchmark dataset, the URGENT challenge aims to drive innovation in speech enhancement, leading to more versatile and reliable systems that can perform well in a wide range of real-world scenarios.
Technical Explanation
The URGENT challenge is designed to address three key aspects of speech enhancement systems:
- Universality: The ability of a model to perform well across diverse environments, speakers, and noise conditions, rather than just optimizing for specific benchmarks.
- Robustness: The model's ability to maintain high performance even in challenging conditions, such as extreme noise levels or unseen speaker characteristics.
- Generalizability: The capacity of the model to adapt to new environments and scenarios without the need for extensive retraining.
To evaluate these properties, the URGENT challenge will provide a comprehensive dataset that covers a wide range of acoustic environments, speaker characteristics, and noise types. Participating models will be assessed on their ability to maintain high performance across this diverse set of test conditions, rather than just optimizing for a single benchmark.
The challenge also encourages the development of speech enhancement architectures that are efficient and scalable, as highlighted in Beyond Performance Plateaus: A Comprehensive Study of Scalability in Speech Enhancement and Speech Enhancement with Deep Learning: An Architecture for Efficient Edge Deployment. This is particularly important for real-world applications, where speech enhancement models may need to run on resource-constrained devices, such as smartphones or edge computing platforms.
By addressing the key issues of universality, robustness, and generalizability, the URGENT challenge aims to drive the development of speech enhancement systems that are more versatile, reliable, and accessible across a wide range of use cases, including Noise-Aware Speech Enhancement using Diffusion Probabilistic Models and Advancing African-Accented Speech Recognition with Epistemic Uncertainty.
Critical Analysis
The URGENT challenge is a valuable initiative that addresses important limitations in current speech enhancement systems. By focusing on universality, robustness, and generalizability, the challenge encourages researchers to develop models that can perform well in diverse real-world scenarios, rather than just optimizing for specific benchmarks.
One potential limitation of the challenge is the availability and diversity of the dataset. While the authors mention that the dataset will cover a wide range of acoustic environments, speakers, and noise types, the actual composition and quality of the dataset will be crucial in determining the success of the challenge. Researchers will need to carefully evaluate the dataset to ensure that it adequately represents the intended diversity and challenges.
Additionally, the challenge may face the risk of overfitting, where models perform well on the challenge dataset but struggle to generalize to completely new environments. The authors could consider incorporating additional mechanisms, such as out-of-distribution testing or meta-learning techniques, to better assess the true generalizability of the participating models.
Overall, the URGENT challenge is a valuable and much-needed initiative that has the potential to drive significant advancements in the field of speech enhancement. By encouraging the development of more universal, robust, and generalizable models, the challenge can contribute to the widespread adoption and reliable performance of speech enhancement technologies in a wide range of real-world applications.
Conclusion
The URGENT challenge is a critical initiative that aims to address the key limitations of current speech enhancement systems, focusing on the crucial aspects of universality, robustness, and generalizability. By providing a comprehensive dataset and clear evaluation criteria, the challenge encourages researchers to develop models that can perform well across diverse acoustic environments, speakers, and noise conditions, rather than just optimizing for specific benchmarks.
The success of the URGENT challenge has the potential to significantly advance the field of speech enhancement, leading to more versatile and reliable systems that can be widely deployed in a variety of applications, from Noise-Aware Speech Enhancement using Diffusion Probabilistic Models to Advancing African-Accented Speech Recognition with Epistemic Uncertainty. This, in turn, can contribute to the broader goal of making speech technologies more accessible and inclusive, benefiting a wide range of users and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
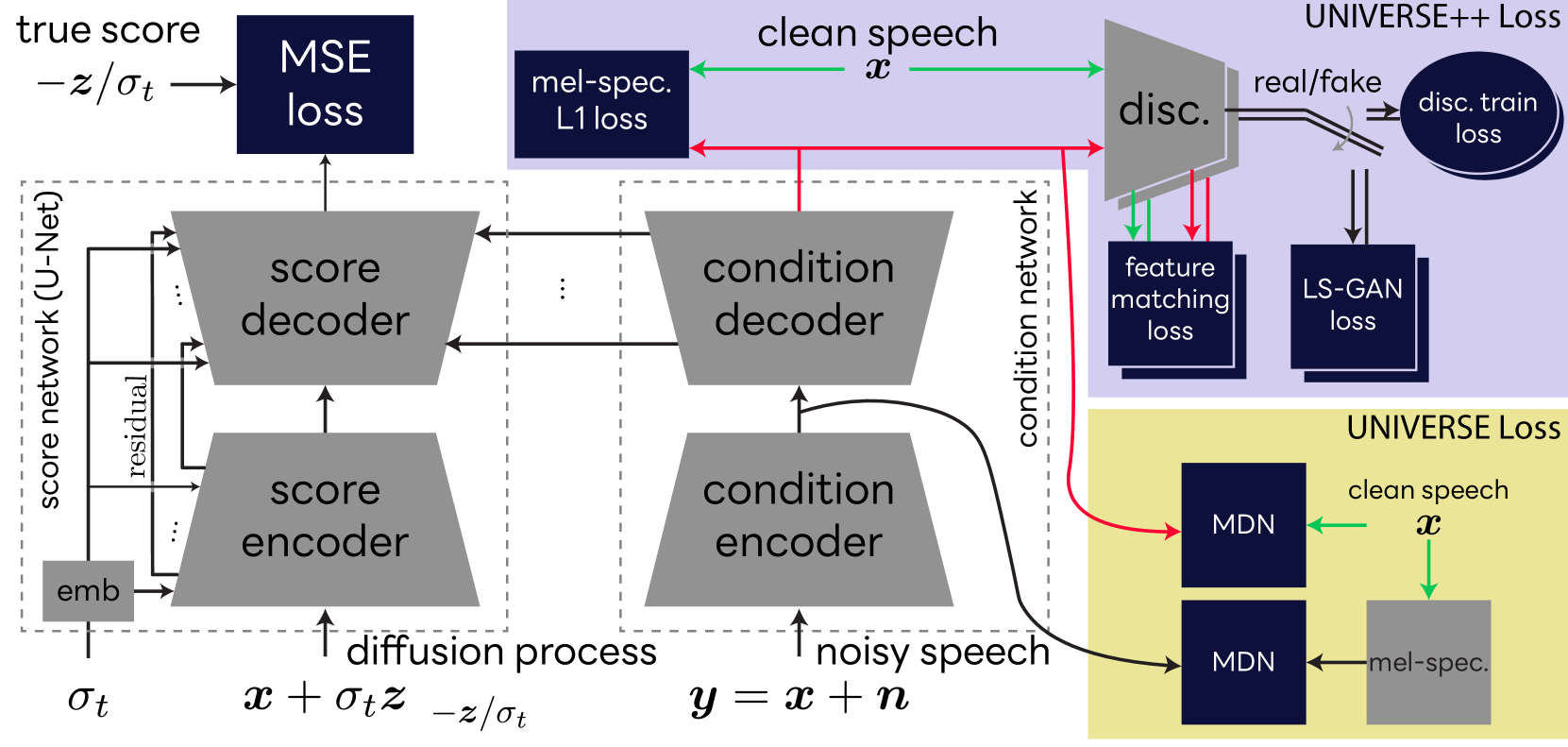
Universal Score-based Speech Enhancement with High Content Preservation
Robin Scheibler, Yusuke Fujita, Yuma Shirahata, Tatsuya Komatsu
0
0
We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
6/19/2024
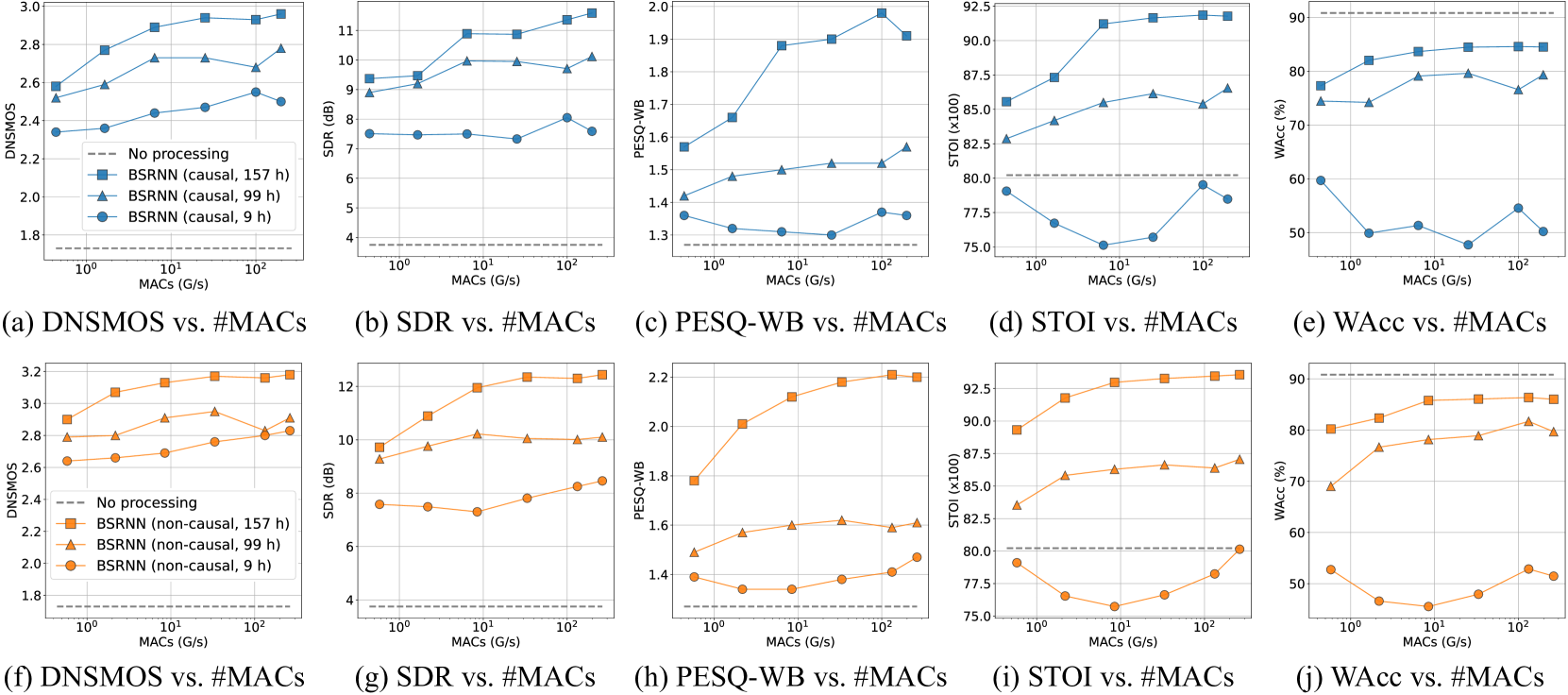
Beyond Performance Plateaus: A Comprehensive Study on Scalability in Speech Enhancement
Wangyou Zhang, Kohei Saijo, Jee-weon Jung, Chenda Li, Shinji Watanabe, Yanmin Qian
0
0
Deep learning-based speech enhancement (SE) models have achieved impressive performance in the past decade. Numerous advanced architectures have been designed to deliver state-of-the-art performance; however, their scalability potential remains unrevealed. Meanwhile, the majority of research focuses on small-sized datasets with restricted diversity, leading to a plateau in performance improvement. In this paper, we aim to provide new insights for addressing the above issues by exploring the scalability of SE models in terms of architectures, model sizes, compute budgets, and dataset sizes. Our investigation involves several popular SE architectures and speech data from different domains. Experiments reveal both similarities and distinctions between the scaling effects in SE and other tasks such as speech recognition. These findings further provide insights into the under-explored SE directions, e.g., larger-scale multi-domain corpora and efficiently scalable architectures.
6/7/2024
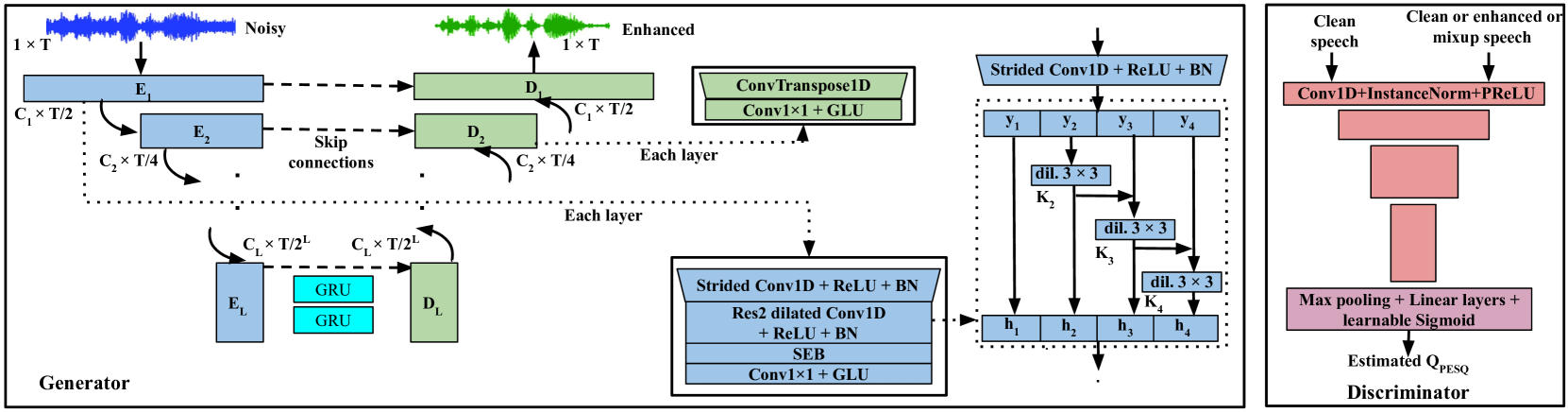
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
0
0
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
5/28/2024
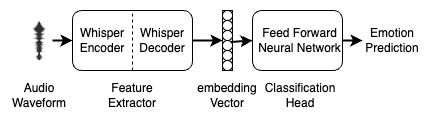
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
0
0
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
6/17/2024