SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension

0
💬
Sign in to get full access
Overview
- Introduces a new benchmark called SEED-Bench-2-Plus for evaluating the text-rich visual comprehension capabilities of Multimodal Large Language Models (MLLMs)
- The benchmark covers a range of real-world text-rich scenarios across three categories: Charts, Maps, and Webs
- Provides a comprehensive evaluation of 34 prominent MLLMs, highlighting their current limitations in text-rich visual comprehension
Plain English Explanation
Multimodal Large Language Models (MLLMs) are advanced AI systems that can understand and process information from multiple sources, such as text and images. As these models become increasingly versatile, it's important to thoroughly assess their capabilities in real-world scenarios, especially those involving extensive text embedded within visual content.
The researchers behind this study recognized that existing MLLM benchmarks primarily focus on general visual comprehension, and they saw a need for a more targeted evaluation of text-rich visual understanding. To address this, they created the SEED-Bench-2-Plus benchmark, which consists of over 2,300 multiple-choice questions covering three broad categories of text-rich visuals: Charts, Maps, and Webs.
These categories were chosen because they represent the kinds of complex, real-world scenarios that people encounter regularly, such as interpreting data visualizations, navigating digital maps, and comprehending information-rich web pages. By evaluating the performance of 34 prominent MLLMs, including GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus, the researchers were able to identify the current limitations of these models in understanding text-rich visual content.
The findings from this study can serve as a valuable addition to existing MLLM benchmarks, providing a more comprehensive assessment of these models' capabilities and inspiring further research in the area of text-rich visual comprehension.
Technical Explanation
The researchers introduced a new benchmark called SEED-Bench-2-Plus, which is specifically designed to evaluate the text-rich visual comprehension capabilities of Multimodal Large Language Models (MLLMs). The benchmark consists of 2.3K multiple-choice questions with precise human annotations, covering three broad categories: Charts, Maps, and Webs.
These categories were chosen to simulate real-world text-rich environments, as they are characterized by the presence of extensive texts embedded within images. The Charts category includes questions related to understanding data visualizations, the Maps category focuses on navigating digital maps, and the Webs category covers the comprehension of information-rich web pages.
The researchers conducted a thorough evaluation involving 34 prominent MLLMs, including GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus. The evaluation results highlighted the current limitations of these models in text-rich visual comprehension, indicating that there is still room for improvement in this area.
The dataset and evaluation code for SEED-Bench-2-Plus are publicly available on GitHub, allowing other researchers to build upon this work and further explore the challenges of text-rich visual comprehension in the context of MLLMs.
Critical Analysis
The SEED-Bench-2-Plus benchmark represents a valuable addition to the existing MLLM evaluation landscape, as it focuses on a specific and practical aspect of these models' capabilities – their performance in text-rich visual scenarios. The researchers have designed the benchmark to accurately simulate real-world situations, which is crucial for assessing the practical application of MLLMs.
However, it's important to note that the benchmark may not capture all the nuances and complexities of real-world text-rich environments. For instance, the categories used in the benchmark (Charts, Maps, and Webs) may not encompass the full breadth of text-rich scenarios that MLLMs may encounter in the real world.
Additionally, the evaluation of 34 MLLMs, while comprehensive, may not include the latest advancements in the field. As the technology continues to evolve rapidly, it would be beneficial to have regular updates to the benchmark and a more extensive evaluation of the most recent MLLM models.
Nonetheless, the insights gained from this study can serve as a valuable starting point for further research and development in the area of text-rich visual comprehension with MLLMs. The findings can inform the design of more effective training strategies and the development of novel architectures to address the current limitations identified in the study.
Conclusion
The introduction of the SEED-Bench-2-Plus benchmark is a significant step forward in the comprehensive evaluation of Multimodal Large Language Models (MLLMs). By focusing on text-rich visual scenarios, the benchmark provides a more realistic assessment of these models' capabilities in practical applications.
The researchers' thorough evaluation of 34 prominent MLLMs has revealed the current limitations of these models in understanding text-rich visual content, highlighting the need for further advancements in this area. The insights gained from this study can inspire researchers and developers to explore new approaches and strategies to improve the text-rich visual comprehension capabilities of MLLMs.
Overall, the SEED-Bench-2-Plus benchmark and the findings from this study represent a valuable contribution to the field of Multimodal AI, paving the way for more robust and practical applications of these powerful models in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension
Bohao Li, Yuying Ge, Yi Chen, Yixiao Ge, Ruimao Zhang, Ying Shan
Comprehending text-rich visual content is paramount for the practical application of Multimodal Large Language Models (MLLMs), since text-rich scenarios are ubiquitous in the real world, which are characterized by the presence of extensive texts embedded within images. Recently, the advent of MLLMs with impressive versatility has raised the bar for what we can expect from MLLMs. However, their proficiency in text-rich scenarios has yet to be comprehensively and objectively assessed, since current MLLM benchmarks primarily focus on evaluating general visual comprehension. In this work, we introduce SEED-Bench-2-Plus, a benchmark specifically designed for evaluating textbf{text-rich visual comprehension} of MLLMs. Our benchmark comprises 2.3K multiple-choice questions with precise human annotations, spanning three broad categories: Charts, Maps, and Webs, each of which covers a wide spectrum of text-rich scenarios in the real world. These categories, due to their inherent complexity and diversity, effectively simulate real-world text-rich environments. We further conduct a thorough evaluation involving 34 prominent MLLMs (including GPT-4V, Gemini-Pro-Vision and Claude-3-Opus) and emphasize the current limitations of MLLMs in text-rich visual comprehension. We hope that our work can serve as a valuable addition to existing MLLM benchmarks, providing insightful observations and inspiring further research in the area of text-rich visual comprehension with MLLMs. The dataset and evaluation code can be accessed at https://github.com/AILab-CVC/SEED-Bench.
Read more4/26/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024
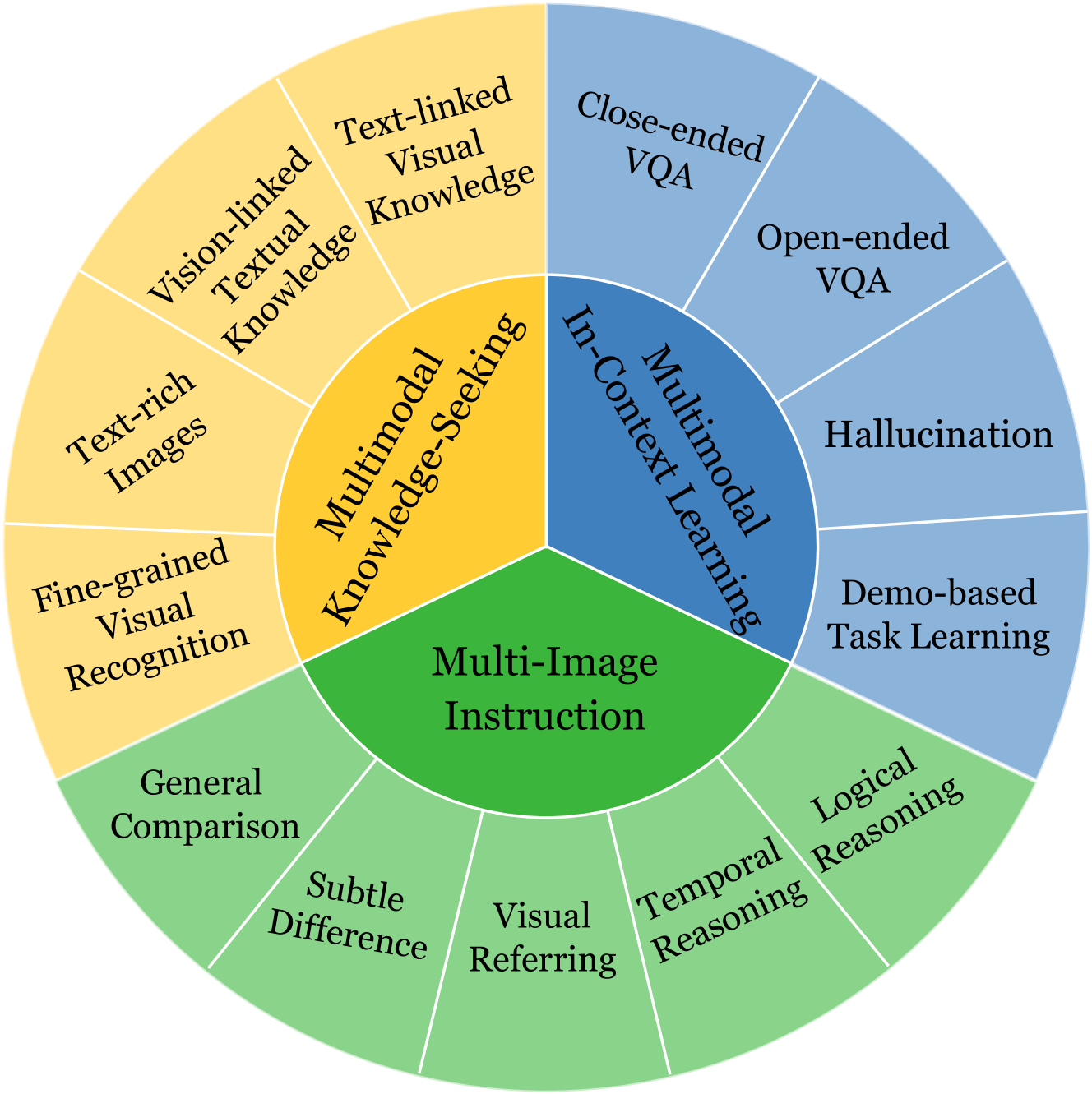
0
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, Weiming Hu
Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Read more7/23/2024

0
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Read more4/10/2024