SEED: A Simple and Effective 3D DETR in Point Clouds

0

Sign in to get full access
Overview
- This paper presents SEED (Simple and Effective 3D DETR in Point Clouds), a 3D object detection model that utilizes a DETR (DEtection Transformer) architecture to achieve state-of-the-art performance on point cloud datasets.
- SEED introduces several key innovations, including a novel Spatial-Temporal Graph Attention (STGA) module and a Sparse-to-Dense (S2D) module, which work together to enhance the model's ability to detect objects in complex point cloud scenes.
- The paper demonstrates SEED's superior performance compared to other 3D object detection approaches across multiple benchmarks, making it a promising solution for applications like autonomous driving and robotics.
Plain English Explanation
The paper introduces a new 3D object detection model called SEED, which uses a transformer-based architecture to identify and locate objects in point cloud data. Point clouds are 3D representations of the physical world, often collected by sensors like LiDAR in autonomous vehicles or robots.
SEED's key innovations are the Spatial-Temporal Graph Attention (STGA) module and the Sparse-to-Dense (S2D) module. The STGA module helps the model better understand the spatial and temporal relationships between different objects and parts of the point cloud. The S2D module takes the sparse point cloud data and efficiently converts it into a more dense, structured format that the transformer can process more effectively.
By using these novel components, SEED is able to outperform other state-of-the-art 3D object detection models on several benchmark datasets. This means SEED can more accurately identify and locate objects like cars, pedestrians, and traffic signs in complex 3D environments, which is crucial for applications like self-driving cars and robotic navigation.
The paper's findings suggest that SEED's simple yet effective design makes it a promising solution for 3D object detection tasks, with the potential to have a significant impact on the development of advanced perception systems for autonomous systems.
Technical Explanation
The authors of this paper present SEED, a 3D object detection model that utilizes a DETR (DEtection Transformer) architecture to achieve state-of-the-art performance on point cloud datasets. SEED introduces two key innovations: a Spatial-Temporal Graph Attention (STGA) module and a Sparse-to-Dense (S2D) module.
The STGA module is designed to better capture the spatial and temporal relationships between objects in the point cloud data. It constructs a graph representation of the scene and applies attention mechanisms to learn the interdependencies between different parts of the point cloud. This allows the model to more effectively reason about the 3D environment and the interactions between objects.
The S2D module, on the other hand, addresses the challenge of processing sparse point cloud data with the transformer-based architecture. It efficiently converts the sparse input into a dense feature representation, which can then be better processed by the transformer layers. This conversion step helps to improve the model's performance and robustness.
The authors evaluate SEED on several 3D object detection benchmarks, including the popular KITTI and nuScenes datasets. The results demonstrate that SEED outperforms other state-of-the-art 3D object detection approaches, such as Spatial-Temporal Graph Enhanced DETR, Sparse Semi-DETR, and DQ-DETR, across a range of metrics. This suggests that SEED's simple yet effective design makes it a promising solution for 3D object detection tasks.
Critical Analysis
The paper provides a thorough evaluation of SEED's performance on multiple benchmark datasets, demonstrating its effectiveness in 3D object detection tasks. However, the authors do not address certain limitations or potential issues with the proposed approach.
For example, the paper does not discuss the computational complexity or inference time of SEED, which could be an important consideration for real-time applications like autonomous driving. Additionally, the authors do not explore the model's robustness to noisy or incomplete point cloud data, which is a common challenge in real-world scenarios.
Furthermore, the paper could benefit from a more in-depth analysis of the contributions of the STGA and S2D modules, as well as a comparison to alternative techniques for handling sparse point cloud data, such as those discussed in Sparse Points to Dense Clouds or CT3D.
Overall, while the paper presents a promising approach to 3D object detection, further research and evaluation would be needed to fully assess the potential advantages and limitations of the SEED model.
Conclusion
The SEED (Simple and Effective 3D DETR in Point Clouds) model introduced in this paper offers a novel solution for 3D object detection in point cloud data. By incorporating a Spatial-Temporal Graph Attention module and a Sparse-to-Dense module, SEED is able to outperform other state-of-the-art 3D detection approaches on several benchmark datasets.
The paper's findings suggest that SEED's simple yet effective design makes it a promising candidate for real-world applications like autonomous driving and robotics, where accurate 3D object detection is crucial. The model's ability to effectively process and reason about complex point cloud data could have significant implications for the development of advanced perception systems for autonomous systems.
While the paper provides a thorough evaluation of SEED's performance, further research is needed to address potential limitations, such as computational complexity and robustness to noisy or incomplete data. Overall, the SEED model represents an important contribution to the field of 3D object detection and a significant step forward in the development of more capable and reliable perception systems for autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SEED: A Simple and Effective 3D DETR in Point Clouds
Zhe Liu, Jinghua Hou, Xiaoqing Ye, Tong Wang, Jingdong Wang, Xiang Bai
Recently, detection transformers (DETRs) have gradually taken a dominant position in 2D detection thanks to their elegant framework. However, DETR-based detectors for 3D point clouds are still difficult to achieve satisfactory performance. We argue that the main challenges are twofold: 1) How to obtain the appropriate object queries is challenging due to the high sparsity and uneven distribution of point clouds; 2) How to implement an effective query interaction by exploiting the rich geometric structure of point clouds is not fully explored. To this end, we propose a simple and effective 3D DETR method (SEED) for detecting 3D objects from point clouds, which involves a dual query selection (DQS) module and a deformable grid attention (DGA) module. More concretely, to obtain appropriate queries, DQS first ensures a high recall to retain a large number of queries by the predicted confidence scores and then further picks out high-quality queries according to the estimated quality scores. DGA uniformly divides each reference box into grids as the reference points and then utilizes the predicted offsets to achieve a flexible receptive field, allowing the network to focus on relevant regions and capture more informative features. Extensive ablation studies on DQS and DGA demonstrate its effectiveness. Furthermore, our SEED achieves state-of-the-art detection performance on both the large-scale Waymo and nuScenes datasets, illustrating the superiority of our proposed method. The code is available at https://github.com/happinesslz/SEED
Read more7/16/2024

0
Diff3DETR:Agent-based Diffusion Model for Semi-supervised 3D Object Detection
Jiacheng Deng, Jiahao Lu, Tianzhu Zhang
3D object detection is essential for understanding 3D scenes. Contemporary techniques often require extensive annotated training data, yet obtaining point-wise annotations for point clouds is time-consuming and laborious. Recent developments in semi-supervised methods seek to mitigate this problem by employing a teacher-student framework to generate pseudo-labels for unlabeled point clouds. However, these pseudo-labels frequently suffer from insufficient diversity and inferior quality. To overcome these hurdles, we introduce an Agent-based Diffusion Model for Semi-supervised 3D Object Detection (Diff3DETR). Specifically, an agent-based object query generator is designed to produce object queries that effectively adapt to dynamic scenes while striking a balance between sampling locations and content embedding. Additionally, a box-aware denoising module utilizes the DDIM denoising process and the long-range attention in the transformer decoder to refine bounding boxes incrementally. Extensive experiments on ScanNet and SUN RGB-D datasets demonstrate that Diff3DETR outperforms state-of-the-art semi-supervised 3D object detection methods.
Read more8/2/2024
0
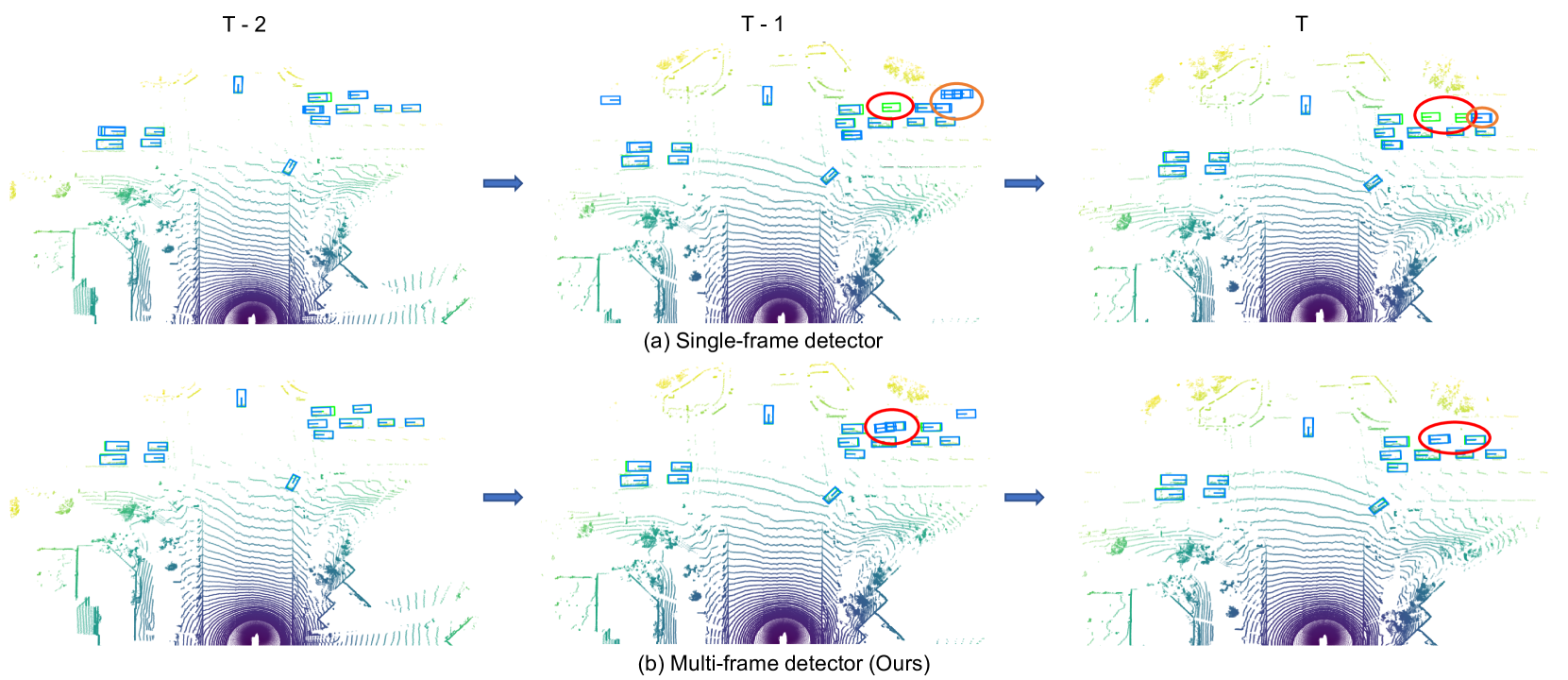
Spatial-Temporal Graph Enhanced DETR Towards Multi-Frame 3D Object Detection
Yifan Zhang, Zhiyu Zhu, Junhui Hou, Dapeng Wu
The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework that enhances the DETR-like paradigm for multi-frame 3D object detection by addressing three key aspects specifically tailored for this task. First, to model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network, which represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. To solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Finally, it poses a challenge for the network to distinguish between the positive query and other highly similar queries that are not the best match. And similar queries are insufficiently suppressed and turn into redundant prediction boxes. To address this issue, our proposed IoU regularization term encourages similar queries to be distinct during the refinement. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code is publicly available at https://github.com/Eaphan/STEMD.
Read more8/14/2024
0
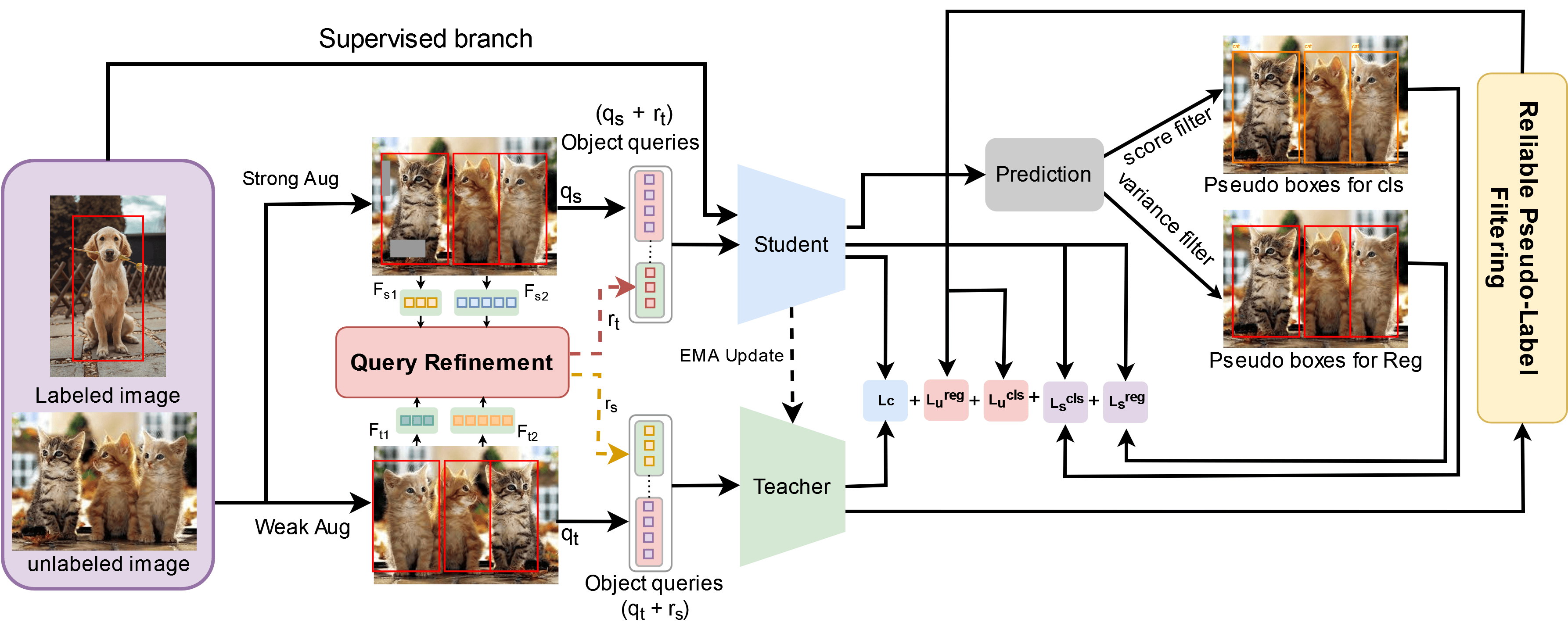
Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
Tahira Shehzadi, Khurram Azeem Hashmi, Didier Stricker, Muhammad Zeshan Afzal
In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
Read more4/3/2024