Seeing the Forest through the Trees: Data Leakage from Partial Transformer Gradients

0

Sign in to get full access
Overview
- This paper investigates how data can be leaked from partial transformer gradients during training.
- The authors show that even a small subset of the gradients from a transformer model can reveal sensitive information about the training data.
- This raises concerns about the security and privacy of transformer models, especially in federated learning settings where gradients are shared across devices.
Plain English Explanation
Transformer models are a type of machine learning algorithm that have become very popular in recent years, powering everything from language translation to image recognition. These models are trained on large datasets, and during the training process, they compute gradients - which are essentially the changes that need to be made to the model's parameters to improve its performance.
The researchers in this paper discovered that even if you only have access to a small subset of these gradients, you can potentially recover sensitive information about the data that was used to train the model. This is known as "data leakage," and it's a significant privacy concern, especially in settings like federated learning, where the gradients are shared across multiple devices.
Imagine you're training a language model on a dataset of people's private messages. Even if an attacker only has access to a small portion of the gradients, they may be able to reconstruct some of the original messages. This could be a major problem for applications that deal with sensitive personal data.
The researchers show several techniques that can be used to extract this kind of information from partial gradients, and they demonstrate the issue on a range of different transformer models and datasets. Their findings highlight the importance of carefully considering privacy and security when deploying these powerful AI models in the real world.
Technical Explanation
The paper Seeing the Forest through the Trees: Data Leakage from Partial Transformer Gradients investigates the problem of data leakage from partial transformer gradients. The authors show that even a small subset of the gradients computed during training can reveal sensitive information about the underlying training data.
The researchers experiment with several different transformer architectures, including BERT, GPT-2, and T5, and they evaluate the data leakage on a variety of datasets, including IMDb movie reviews, Gab posts, and Wikipedia articles. They use techniques like gradient inversion and transpose attacks to extract information from the partial gradients.
Their results demonstrate that significant amounts of information can be recovered from just a small fraction of the gradients, including the presence of specific words or phrases in the training data. This raises serious concerns about the privacy and security implications of gradient leakage in transformer models, especially in federated learning scenarios.
Critical Analysis
The paper provides a thorough and well-designed investigation of data leakage from transformer gradients. The authors carefully consider the potential implications of their findings, particularly in the context of federated learning, where gradients are shared across devices.
However, one limitation of the study is that it focuses primarily on gradients and does not explore other potential sources of data leakage, such as information leakage from embedding models. Additionally, the authors do not delve into potential mitigation strategies, such as the use of differential privacy or other privacy-preserving techniques.
Another area for further research could be the impact of these data leakage issues on the real-world deployment of transformer models. The paper demonstrates the technical feasibility of these attacks, but more work is needed to understand the practical risks and how they might manifest in deployed systems.
Conclusion
The findings in this paper highlight a significant security and privacy challenge for transformer models, especially in federated learning settings. The ability to extract sensitive information from partial gradients raises serious concerns about the potential misuse of these powerful AI models.
The researchers have made an important contribution to our understanding of this problem, but more work is needed to develop robust solutions that can protect the privacy of training data while still allowing the benefits of transformer models to be realized. As these models become increasingly ubiquitous, ensuring their safe and responsible deployment will be a critical priority for the AI research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seeing the Forest through the Trees: Data Leakage from Partial Transformer Gradients
Weijun Li, Qiongkai Xu, Mark Dras
Recent studies have shown that distributed machine learning is vulnerable to gradient inversion attacks, where private training data can be reconstructed by analyzing the gradients of the models shared in training. Previous attacks established that such reconstructions are possible using gradients from all parameters in the entire models. However, we hypothesize that most of the involved modules, or even their sub-modules, are at risk of training data leakage, and we validate such vulnerabilities in various intermediate layers of language models. Our extensive experiments reveal that gradients from a single Transformer layer, or even a single linear component with 0.54% parameters, are susceptible to training data leakage. Additionally, we show that applying differential privacy on gradients during training offers limited protection against the novel vulnerability of data disclosure.
Read more6/4/2024

0
Analyzing Inference Privacy Risks Through Gradients in Machine Learning
Zhuohang Li, Andrew Lowy, Jing Liu, Toshiaki Koike-Akino, Kieran Parsons, Bradley Malin, Ye Wang
In distributed learning settings, models are iteratively updated with shared gradients computed from potentially sensitive user data. While previous work has studied various privacy risks of sharing gradients, our paper aims to provide a systematic approach to analyze private information leakage from gradients. We present a unified game-based framework that encompasses a broad range of attacks including attribute, property, distributional, and user disclosures. We investigate how different uncertainties of the adversary affect their inferential power via extensive experiments on five datasets across various data modalities. Our results demonstrate the inefficacy of solely relying on data aggregation to achieve privacy against inference attacks in distributed learning. We further evaluate five types of defenses, namely, gradient pruning, signed gradient descent, adversarial perturbations, variational information bottleneck, and differential privacy, under both static and adaptive adversary settings. We provide an information-theoretic view for analyzing the effectiveness of these defenses against inference from gradients. Finally, we introduce a method for auditing attribute inference privacy, improving the empirical estimation of worst-case privacy through crafting adversarial canary records.
Read more9/2/2024
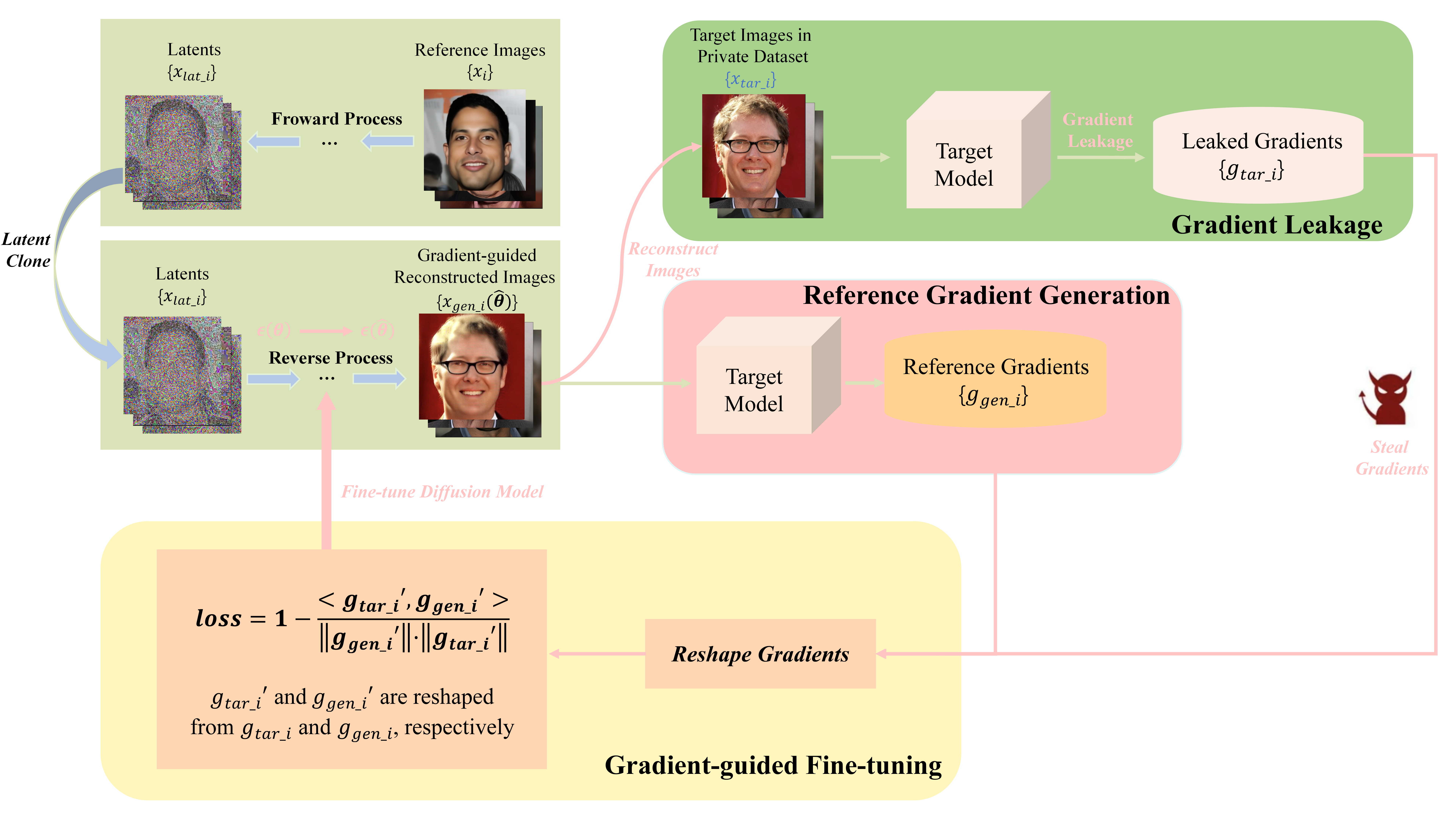
0
Is Diffusion Model Safe? Severe Data Leakage via Gradient-Guided Diffusion Model
Jiayang Meng, Tao Huang, Hong Chen, Cuiping Li
Gradient leakage has been identified as a potential source of privacy breaches in modern image processing systems, where the adversary can completely reconstruct the training images from leaked gradients. However, existing methods are restricted to reconstructing low-resolution images where data leakage risks of image processing systems are not sufficiently explored. In this paper, by exploiting diffusion models, we propose an innovative gradient-guided fine-tuning method and introduce a new reconstruction attack that is capable of stealing private, high-resolution images from image processing systems through leaked gradients where severe data leakage encounters. Our attack method is easy to implement and requires little prior knowledge. The experimental results indicate that current reconstruction attacks can steal images only up to a resolution of $128 times 128$ pixels, while our attack method can successfully recover and steal images with resolutions up to $512 times 512$ pixels. Our attack method significantly outperforms the SOTA attack baselines in terms of both pixel-wise accuracy and time efficiency of image reconstruction. Furthermore, our attack can render differential privacy ineffective to some extent.
Read more6/17/2024
✅
0
Delving into Differentially Private Transformer
Youlong Ding, Xueyang Wu, Yining Meng, Yonggang Luo, Hao Wang, Weike Pan
Deep learning with differential privacy (DP) has garnered significant attention over the past years, leading to the development of numerous methods aimed at enhancing model accuracy and training efficiency. This paper delves into the problem of training Transformer models with differential privacy. Our treatment is modular: the logic is to `reduce' the problem of training DP Transformer to the more basic problem of training DP vanilla neural nets. The latter is better understood and amenable to many model-agnostic methods. Such `reduction' is done by first identifying the hardness unique to DP Transformer training: the attention distraction phenomenon and a lack of compatibility with existing techniques for efficient gradient clipping. To deal with these two issues, we propose the Re-Attention Mechanism and Phantom Clipping, respectively. We believe that our work not only casts new light on training DP Transformers but also promotes a modular treatment to advance research in the field of differentially private deep learning.
Read more8/27/2024