Seeing the Unseen: Visual Metaphor Captioning for Videos

0

Sign in to get full access
Overview
- The paper "Seeing the Unseen: Visual Metaphor Captioning for Videos" explores a novel task of generating visual metaphor captions for videos.
- It introduces a new dataset of video-metaphor pairs and proposes a model to generate creative and expressive captions that go beyond literal descriptions.
- The model aims to capture the underlying metaphorical meaning in videos and translate it into concise, metaphorical language.
Plain English Explanation
This research focuses on a unique challenge: generating creative, metaphorical captions for videos. Typically, video captions describe the literal content, but the researchers wanted to develop a system that could capture the deeper, figurative meaning behind the visuals.
To do this, they created a new dataset that pairs videos with metaphorical captions. For example, a video of a person struggling to climb a steep hill might be paired with the caption "Scaling the mountain of life." The researchers then built a model that can analyze the video and generate a concise, metaphorical description that goes beyond just listing the objects and actions.
The key idea is that by understanding the underlying metaphorical meaning in the video, the model can produce captions that are more expressive, insightful, and engaging than a literal description. This could have applications in areas like video summarization, video retrieval, and video-based language learning.
Technical Explanation
The paper introduces a new task called "Visual Metaphor Captioning" (VMC), where the goal is to generate metaphorical captions for videos. To support this task, the researchers created a new dataset called "Metaphor-Video" that contains over 20,000 video-metaphor pairs.
The proposed VMC model takes a video as input and generates a metaphorical caption that captures the underlying meaning of the video. The model is built upon a transformer-based architecture, with a video encoder and a text decoder. The video encoder uses a 3D convolutional network to extract visual features, which are then combined with temporal information to create a video representation.
The text decoder is trained to generate the metaphorical caption given the video representation. The researchers experimented with different techniques to improve the model's ability to generate creative and expressive captions, including using contrastive learning to encourage the model to discover meaningful metaphorical connections.
The evaluation of the VMC model shows that it can generate captions that are more metaphorical, creative, and expressive compared to baseline methods. The model also demonstrates the ability to generate relevant and interpretable metaphors for a wide range of video content.
Critical Analysis
The paper presents a novel and promising approach to video captioning, but there are a few potential limitations and areas for further research:
-
The dataset size and diversity: While the Metaphor-Video dataset is a valuable resource, it may not capture the full breadth of metaphorical expressions used in real-world videos. Expanding the dataset with more videos and metaphors could help the model generalize better.
-
Evaluation metrics: The paper uses subjective human evaluation to assess the quality of the generated captions. Developing more objective, automated metrics for metaphor generation could provide a more comprehensive evaluation.
-
Interpretability and transparency: While the paper highlights the model's ability to generate interpretable metaphors, it would be interesting to further explore the model's inner workings and the reasoning behind the generated captions.
-
Applications and real-world deployment: The paper focuses on the technical aspects of the VMC task, but more research is needed to understand the practical implications and potential use cases of this technology, such as in video summarization or video-based language learning.
Conclusion
The "Seeing the Unseen" paper presents an innovative approach to video captioning that goes beyond literal descriptions and aims to capture the underlying metaphorical meaning in videos. By introducing the Visual Metaphor Captioning task and a new dataset, the researchers have opened up new possibilities for more expressive and creative video understanding. While there are some areas for further research, this work represents an important step towards developing AI systems that can truly "see the unseen" in visual content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seeing the Unseen: Visual Metaphor Captioning for Videos
Abisek Rajakumar Kalarani, Pushpak Bhattacharyya, Sumit Shekhar
Metaphors are a common communication tool used in our day-to-day life. The detection and generation of metaphors in textual form have been studied extensively but metaphors in other forms have been under-explored. Recent studies have shown that Vision-Language (VL) models cannot understand visual metaphors in memes and adverts. As of now, no probing studies have been done that involve complex language phenomena like metaphors with videos. Hence, we introduce a new VL task of describing the metaphors present in the videos in our work. To facilitate this novel task, we construct and release a manually created dataset with 705 videos and 2115 human-written captions, along with a new metric called Average Concept Distance (ACD), to automatically evaluate the creativity of the metaphors generated. We also propose a novel low-resource video metaphor captioning system: GIT-LLaVA, which obtains comparable performance to SoTA video language models on the proposed task. We perform a comprehensive analysis of existing video language models on this task and publish our dataset, models, and benchmark results to enable further research.
Read more6/10/2024

0
Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
Read more4/17/2024
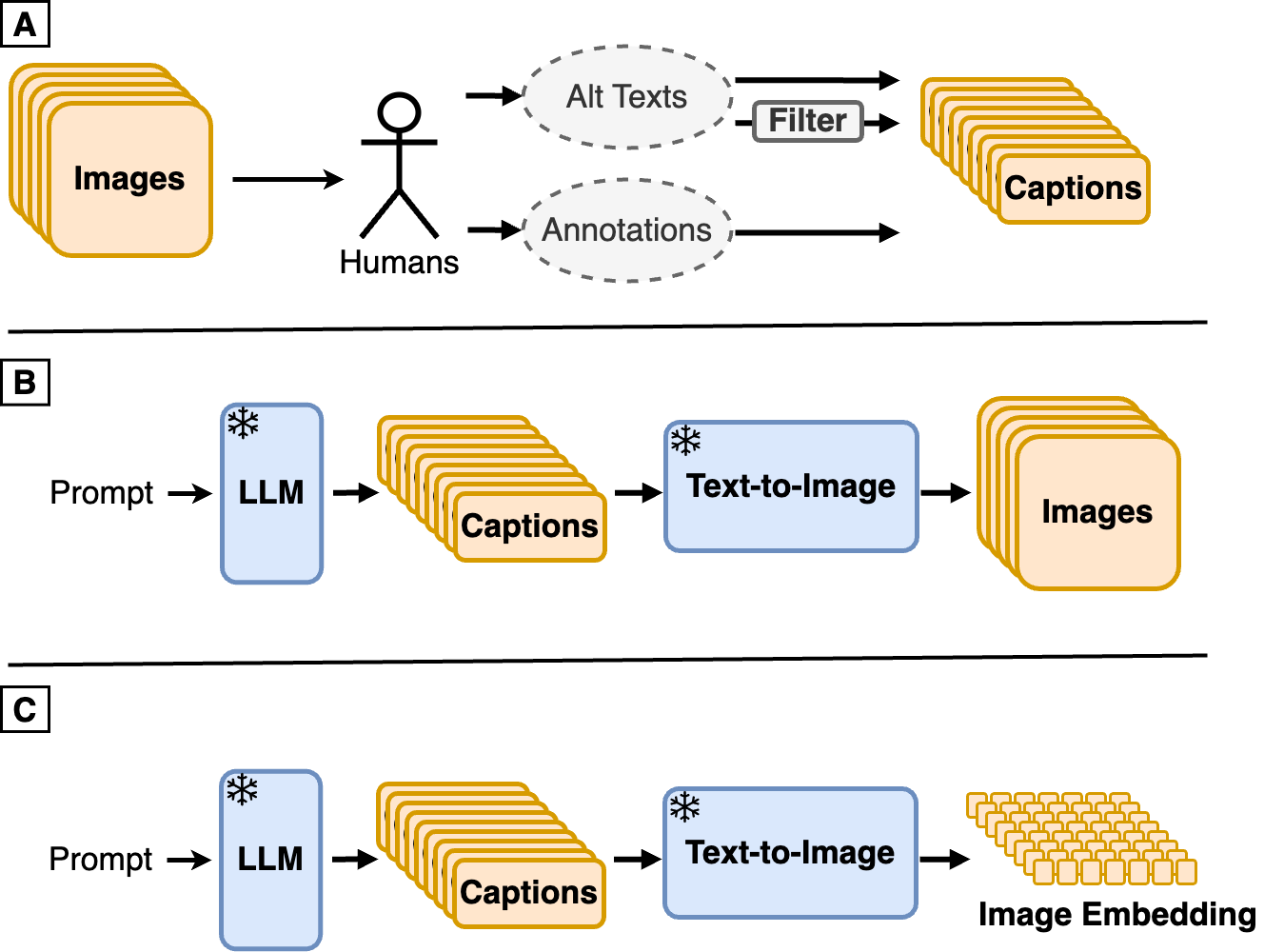
0
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024

0
V-FLUTE: Visual Figurative Language Understanding with Textual Explanations
Arkadiy Saakyan, Shreyas Kulkarni, Tuhin Chakrabarty, Smaranda Muresan
Large Vision-Language models (VLMs) have demonstrated strong reasoning capabilities in tasks requiring a fine-grained understanding of literal images and text, such as visual question-answering or visual entailment. However, there has been little exploration of these models' capabilities when presented with images and captions containing figurative phenomena such as metaphors or humor, the meaning of which is often implicit. To close this gap, we propose a new task and a high-quality dataset: Visual Figurative Language Understanding with Textual Explanations (V-FLUTE). We frame the visual figurative language understanding problem as an explainable visual entailment task, where the model has to predict whether the image (premise) entails a claim (hypothesis) and justify the predicted label with a textual explanation. Using a human-AI collaboration framework, we build a high-quality dataset, V-FLUTE, that contains 6,027 instances spanning five diverse multimodal figurative phenomena: metaphors, similes, idioms, sarcasm, and humor. The figurative phenomena can be present either in the image, the caption, or both. We further conduct both automatic and human evaluations to assess current VLMs' capabilities in understanding figurative phenomena.
Read more5/3/2024