Seeking Neural Nuggets: Knowledge Transfer in Large Language Models from a Parametric Perspective
2310.11451
0
0
🧠
Abstract
Large Language Models (LLMs) inherently encode a wealth of knowledge within their parameters through pre-training on extensive corpora. While prior research has delved into operations on these parameters to manipulate the underlying implicit knowledge (encompassing detection, editing, and merging), there remains an ambiguous understanding regarding their transferability across models with varying scales. In this paper, we seek to empirically investigate knowledge transfer from larger to smaller models through a parametric perspective. To achieve this, we employ sensitivity-based techniques to extract and align knowledge-specific parameters between different LLMs. Moreover, the LoRA module is used as the intermediary mechanism for injecting the extracted knowledge into smaller models. Evaluations across four benchmarks validate the efficacy of our proposed method. Our findings highlight the critical factors contributing to the process of parametric knowledge transfer, underscoring the transferability of model parameters across LLMs of different scales. Project website: https://maszhongming.github.io/ParaKnowTransfer.
Create account to get full access
Overview
- Large language models (LLMs) contain a wealth of knowledge from their extensive pre-training on large datasets.
- Prior research has explored ways to manipulate this implicit knowledge, such as detection, editing, and merging.
- However, the transferability of this knowledge across LLMs of different scales remains unclear.
- This paper aims to empirically investigate knowledge transfer from larger to smaller LLMs using a parametric perspective.
Plain English Explanation
Large language models (LLMs) are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. These models have essentially absorbed a lot of knowledge during their training process, and researchers have been exploring ways to access and manipulate this knowledge.
For example, previous studies have looked at detecting specific types of knowledge in LLMs, editing or changing that knowledge, and even combining knowledge from different models. However, one key question that hasn't been fully answered is how well this knowledge can be transferred between LLMs of different sizes or scales.
This paper sets out to investigate this idea of knowledge transfer across LLMs. The researchers use techniques that focus on the actual parameters or internal settings of the models to try to extract and align the knowledge-specific parts. They then use a special module called LoRA to inject this extracted knowledge into smaller LLMs.
By evaluating the performance of these smaller models on various benchmarks, the researchers were able to show that their approach was effective at transferring knowledge from larger to smaller LLMs. This sheds light on the critical factors that influence this knowledge transfer process and suggests that the parameters of LLMs can indeed be shared across models of different sizes.
Technical Explanation
The researchers in this paper aimed to empirically investigate the transferability of knowledge from larger to smaller large language models (LLMs). To achieve this, they employed sensitivity-based techniques to extract and align knowledge-specific parameters between different LLMs.
Specifically, the researchers used a unified framework for revealing parametric knowledge in language models to identify the most influential parameters for specific types of knowledge. They then leveraged the LoRA module as an intermediary mechanism to inject the extracted knowledge into smaller LLMs.
The efficacy of this approach was validated across four different benchmarks, demonstrating the successful transfer of knowledge from larger to smaller models. The findings highlight the critical factors that contribute to the parametric knowledge transfer process, underscoring the transferability of model parameters across LLMs of varying scales.
This research builds upon prior work on knowledge migration across heterogeneous models and tasks and techniques for teaching large language models new languages, further advancing our understanding of how to effectively leverage and share the wealth of knowledge contained within LLMs.
Critical Analysis
The researchers in this paper have presented an intriguing approach to transferring knowledge from larger to smaller LLMs. By focusing on the model parameters, they were able to identify and align the knowledge-specific components, which is a novel and promising avenue of research.
However, the paper does not delve deeply into the potential limitations or caveats of this approach. For instance, it would be valuable to understand how the quality and transferability of the knowledge might be affected by factors such as the degree of difference in scale between the source and target LLMs, the specific types of knowledge being transferred, or the sensitivity of the extraction and alignment techniques.
Additionally, the paper could have explored the potential implications and applications of this knowledge transfer process, such as its impact on model efficiency, performance, or the ability to quickly adapt smaller LLMs to new domains or tasks. Discussing these broader considerations would help contextualize the significance of the research and its potential real-world impact.
Overall, the research presented in this paper is a promising step towards understanding and leveraging the wealth of knowledge encoded in LLMs. Further investigation into the limitations, nuances, and broader implications of this knowledge transfer approach could lead to valuable insights for the field of natural language processing and AI systems development.
Conclusion
This paper presents a novel approach to transferring knowledge from larger to smaller large language models (LLMs) using a parametric perspective. By employing sensitivity-based techniques to extract and align knowledge-specific parameters, the researchers were able to successfully inject this knowledge into smaller LLMs, as demonstrated by their evaluation across multiple benchmarks.
The findings highlight the critical factors that contribute to the process of parametric knowledge transfer, underscoring the transferability of model parameters across LLMs of different scales. This research builds upon and complements previous work on knowledge migration and language model adaptation, further advancing our understanding of how to effectively leverage the wealth of knowledge contained within these powerful AI systems.
The implications of this research could be far-reaching, potentially leading to more efficient and adaptable LLM architectures, as well as new strategies for quickly tailoring smaller models to specific domains or tasks. As the field of natural language processing continues to evolve, studies like this one will play a crucial role in unlocking the full potential of large language models and their myriad applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating the External and Parametric Knowledge Fusion of Large Language Models
Hao Zhang, Yuyang Zhang, Xiaoguang Li, Wenxuan Shi, Haonan Xu, Huanshuo Liu, Yasheng Wang, Lifeng Shang, Qun Liu, Yong Liu, Ruiming Tang
0
0
Integrating external knowledge into large language models (LLMs) presents a promising solution to overcome the limitations imposed by their antiquated and static parametric memory. Prior studies, however, have tended to over-reliance on external knowledge, underestimating the valuable contributions of an LLMs' intrinsic parametric knowledge. The efficacy of LLMs in blending external and parametric knowledge remains largely unexplored, especially in cases where external knowledge is incomplete and necessitates supplementation by their parametric knowledge. We propose to deconstruct knowledge fusion into four distinct scenarios, offering the first thorough investigation of LLM behavior across each. We develop a systematic pipeline for data construction and knowledge infusion to simulate these fusion scenarios, facilitating a series of controlled experiments. Our investigation reveals that enhancing parametric knowledge within LLMs can significantly bolster their capability for knowledge integration. Nonetheless, we identify persistent challenges in memorizing and eliciting parametric knowledge, and determining parametric knowledge boundaries. Our findings aim to steer future explorations on harmonizing external and parametric knowledge within LLMs.
5/30/2024

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024
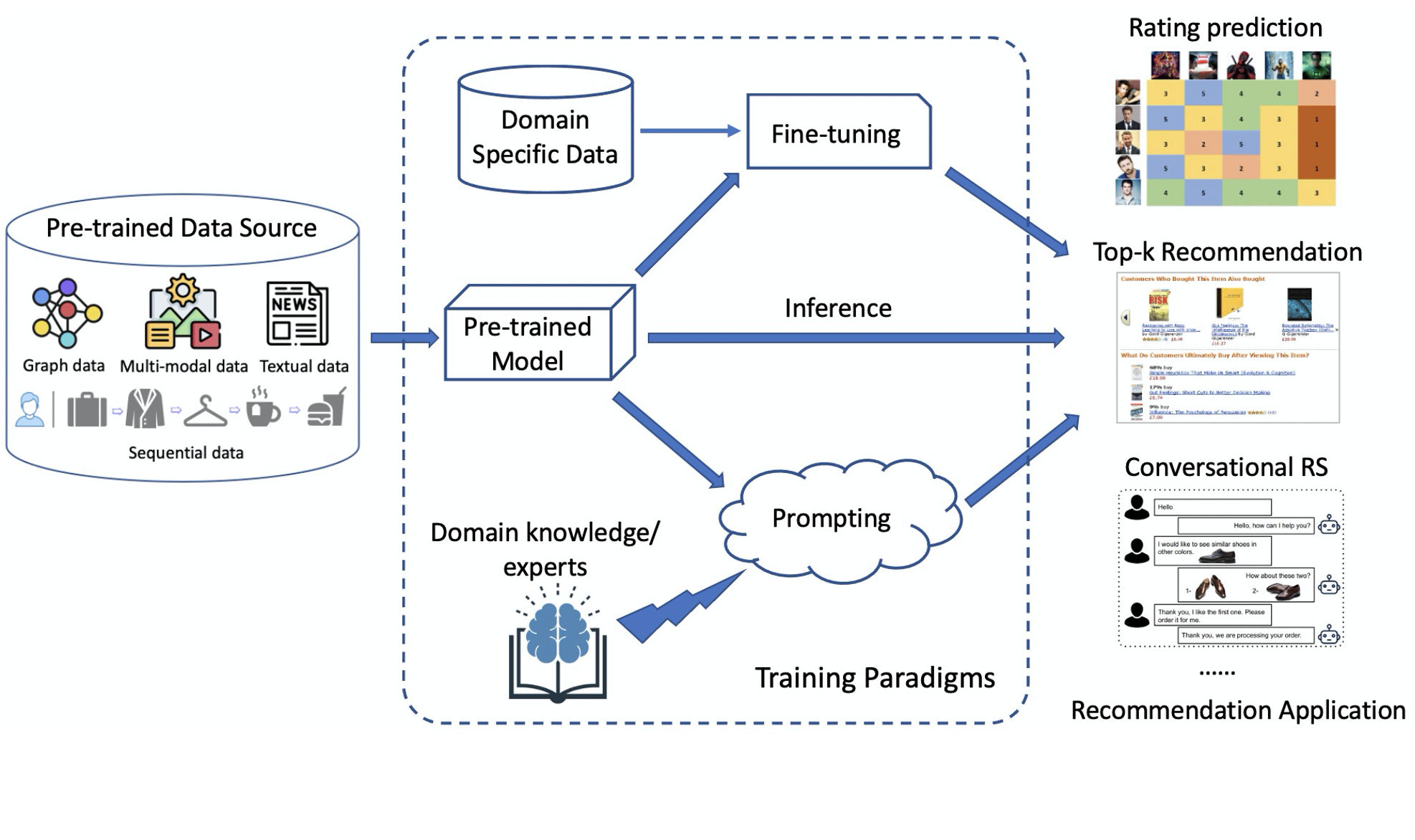
Understanding Language Modeling Paradigm Adaptations in Recommender Systems: Lessons Learned and Open Challenges
Lemei Zhang, Peng Liu, Yashar Deldjoo, Yong Zheng, Jon Atle Gulla
0
0
The emergence of Large Language Models (LLMs) has achieved tremendous success in the field of Natural Language Processing owing to diverse training paradigms that empower LLMs to effectively capture intricate linguistic patterns and semantic representations. In particular, the recent pre-train, prompt and predict training paradigm has attracted significant attention as an approach for learning generalizable models with limited labeled data. In line with this advancement, these training paradigms have recently been adapted to the recommendation domain and are seen as a promising direction in both academia and industry. This half-day tutorial aims to provide a thorough understanding of extracting and transferring knowledge from pre-trained models learned through different training paradigms to improve recommender systems from various perspectives, such as generality, sparsity, effectiveness and trustworthiness. In this tutorial, we first introduce the basic concepts and a generic architecture of the language modeling paradigm for recommendation purposes. Then, we focus on recent advancements in adapting LLM-related training strategies and optimization objectives for different recommendation tasks. After that, we will systematically introduce ethical issues in LLM-based recommender systems and discuss possible approaches to assessing and mitigating them. We will also summarize the relevant datasets, evaluation metrics, and an empirical study on the recommendation performance of training paradigms. Finally, we will conclude the tutorial with a discussion of open challenges and future directions.
4/8/2024