MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and Modalities
2404.13322
0
0

Abstract
In this study, we focus on heterogeneous knowledge transfer across entirely different model architectures, tasks, and modalities. Existing knowledge transfer methods (e.g., backbone sharing, knowledge distillation) often hinge on shared elements within model structures or task-specific features/labels, limiting transfers to complex model types or tasks. To overcome these challenges, we present MergeNet, which learns to bridge the gap of parameter spaces of heterogeneous models, facilitating the direct interaction, extraction, and application of knowledge within these parameter spaces. The core mechanism of MergeNet lies in the parameter adapter, which operates by querying the source model's low-rank parameters and adeptly learning to identify and map parameters into the target model. MergeNet is learned alongside both models, allowing our framework to dynamically transfer and adapt knowledge relevant to the current stage, including the training trajectory knowledge of the source model. Extensive experiments on heterogeneous knowledge transfer demonstrate significant improvements in challenging settings, where representative approaches may falter or prove less applicable.
Create account to get full access
Overview
- The provided paper, "MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and Modalities," explores a novel approach to enable knowledge transfer between different types of machine learning models, tasks, and data modalities.
- The researchers introduce MergeNet, a framework that allows for "knowledge migration" by finding and aligning the shared parameter subspaces between heterogeneous models.
- This enables efficient transfer learning, where knowledge from one model can be leveraged to improve the performance of another, even if the models were trained on different tasks or data.
Plain English Explanation
In the world of artificial intelligence and machine learning, there is a growing need for models that can effectively transfer knowledge between different tasks and data types. Cross-Modal Adapter, Conv-Adapter, and Overcoming Generic Knowledge Loss have all explored ways to enable this type of "knowledge migration" between models.
The researchers in this paper propose a new approach called MergeNet, which takes a step further by allowing knowledge transfer not just between similar models, but across completely different types of models, tasks, and data modalities. The key idea is to find the shared "parameter subspaces" between the models, and then use these alignments to efficiently transfer knowledge from one model to another.
Imagine you have a model that has been trained to recognize objects in images, and another model that has been trained to generate text descriptions of those objects. MergeNet could help you leverage the knowledge from the image recognition model to improve the performance of the text generation model, even though they were trained on completely different tasks.
This type of cross-modal knowledge transfer could be incredibly useful in a wide range of applications, from Data-Efficient Multimodal Fusion to Merging By Matching Models. By enabling models to share and build upon each other's knowledge, we can make machine learning systems more efficient, versatile, and capable of tackling increasingly complex real-world problems.
Technical Explanation
The key innovation in the "MergeNet" framework is the use of a novel "model merging" technique that allows for efficient knowledge transfer between heterogeneous models, tasks, and modalities.
The core idea is to identify and align the shared "parameter subspaces" between the source and target models, even if they have very different architectures. This is accomplished through a process of "matching" the models' parameter subspaces, which involves finding the optimal linear transformations that can map the parameters of one model to the other.
Once the parameter subspaces are aligned, the researchers can then selectively transfer the relevant knowledge from the source model to the target model, without needing to retrain the entire target model from scratch. This "parameter-efficient" approach is crucial, as it allows for rapid and flexible knowledge transfer, even in situations where the models were trained on very different tasks or data.
The researchers evaluate MergeNet across a range of experimental settings, demonstrating its ability to effectively transfer knowledge between diverse models and modalities, including computer vision, natural language processing, and multi-modal tasks. The results show that MergeNet can significantly improve the performance of target models, while maintaining a high degree of parameter efficiency.
Critical Analysis
The MergeNet framework represents an important step forward in the field of cross-modal and cross-task knowledge transfer. By enabling efficient knowledge migration between heterogeneous models, the researchers have opened up new possibilities for building more versatile and capable AI systems.
However, it's worth noting that the technique is not without its limitations. The success of the knowledge transfer is heavily dependent on the ability to accurately align the parameter subspaces between the source and target models. In cases where the models are highly dissimilar, or the shared parameter subspaces are not easily identifiable, the performance gains may be more modest.
Additionally, the paper does not delve deeply into the potential for negative transfer, where the knowledge from the source model could actually hinder the performance of the target model. This is an important consideration, as indiscriminate knowledge transfer could potentially lead to suboptimal or even detrimental results.
Future research in this area could explore ways to better identify and mitigate the risks of negative transfer, as well as investigate the scalability of the MergeNet approach as the complexity and diversity of the models and tasks continue to grow. Overcoming Generic Knowledge Loss and Merging By Matching Models have also explored similar challenges in this domain.
Conclusion
The "MergeNet" framework represents a significant advance in the field of cross-modal and cross-task knowledge transfer. By enabling efficient knowledge migration between heterogeneous models, the researchers have opened up new possibilities for building more versatile and capable AI systems.
The ability to leverage knowledge from one model to improve the performance of another, even if they were trained on very different tasks or data, has the potential to drive significant improvements in the efficiency and effectiveness of machine learning systems. This could have wide-ranging implications for a variety of applications, from Data-Efficient Multimodal Fusion to Cross-Modal Adapter and beyond.
As the field of AI continues to evolve, the ability to seamlessly transfer knowledge across models, tasks, and modalities will become increasingly crucial. The MergeNet framework represents an important step in this direction, and future research building on these ideas could lead to even more powerful and versatile machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, Yu Cheng
0
0
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
6/26/2024
🎯
Enhancing Accuracy in Generative Models via Knowledge Transfer
Xinyu Tian, Xiaotong Shen
0
0
This paper investigates the accuracy of generative models and the impact of knowledge transfer on their generation precision. Specifically, we examine a generative model for a target task, fine-tuned using a pre-trained model from a source task. Building on the Shared Embedding concept, which bridges the source and target tasks, we introduce a novel framework for transfer learning under distribution metrics such as the Kullback-Leibler divergence. This framework underscores the importance of leveraging inherent similarities between diverse tasks despite their distinct data distributions. Our theory suggests that the shared structures can augment the generation accuracy for a target task, reliant on the capability of a source model to identify shared structures and effective knowledge transfer from source to target learning. To demonstrate the practical utility of this framework, we explore the theoretical implications for two specific generative models: diffusion and normalizing flows. The results show enhanced performance in both models over their non-transfer counterparts, indicating advancements for diffusion models and providing fresh insights into normalizing flows in transfer and non-transfer settings. These results highlight the significant contribution of knowledge transfer in boosting the generation capabilities of these models.
5/28/2024
🧠
Seeking Neural Nuggets: Knowledge Transfer in Large Language Models from a Parametric Perspective
Ming Zhong, Chenxin An, Weizhu Chen, Jiawei Han, Pengcheng He
0
0
Large Language Models (LLMs) inherently encode a wealth of knowledge within their parameters through pre-training on extensive corpora. While prior research has delved into operations on these parameters to manipulate the underlying implicit knowledge (encompassing detection, editing, and merging), there remains an ambiguous understanding regarding their transferability across models with varying scales. In this paper, we seek to empirically investigate knowledge transfer from larger to smaller models through a parametric perspective. To achieve this, we employ sensitivity-based techniques to extract and align knowledge-specific parameters between different LLMs. Moreover, the LoRA module is used as the intermediary mechanism for injecting the extracted knowledge into smaller models. Evaluations across four benchmarks validate the efficacy of our proposed method. Our findings highlight the critical factors contributing to the process of parametric knowledge transfer, underscoring the transferability of model parameters across LLMs of different scales. Project website: https://maszhongming.github.io/ParaKnowTransfer.
5/9/2024
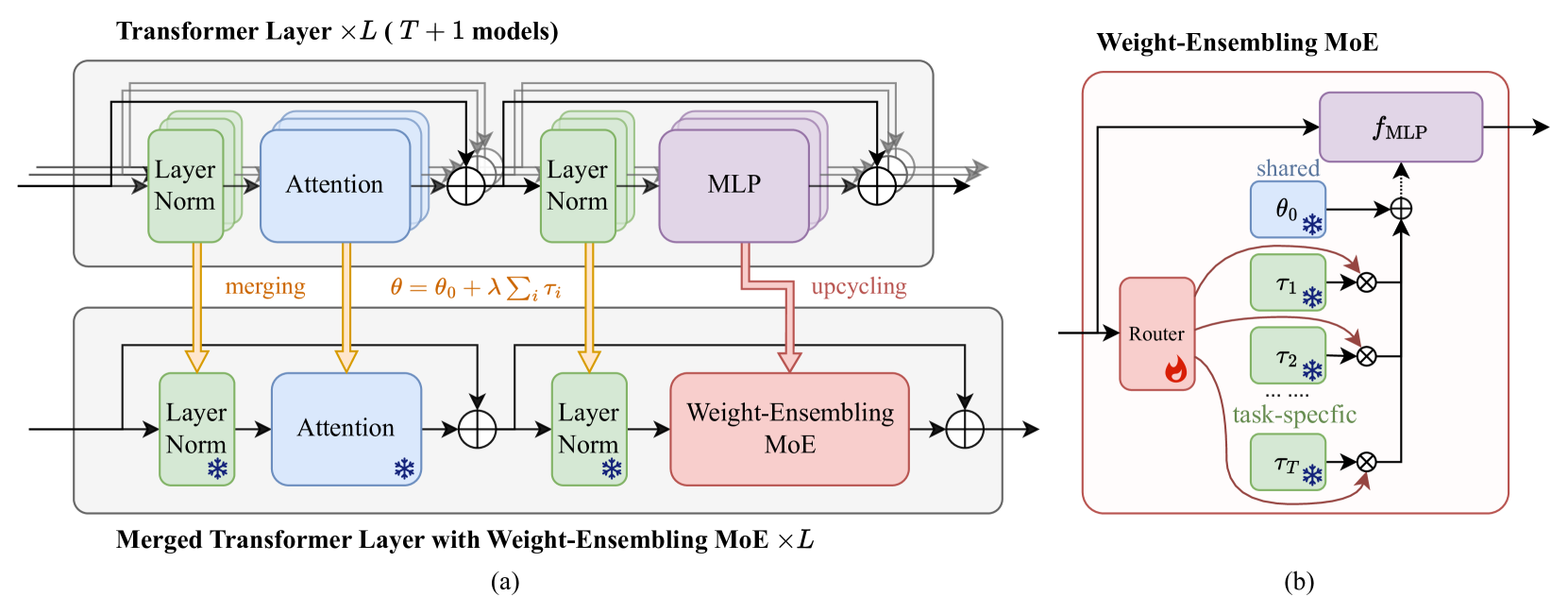
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024