SEGAN: semi-supervised learning approach for missing data imputation
2405.13089
0
0
📊
Abstract
In many practical real-world applications, data missing is a very common phenomenon, making the development of data-driven artificial intelligence theory and technology increasingly difficult. Data completion is an important method for missing data preprocessing. Most existing miss-ing data completion models directly use the known information in the missing data set but ignore the impact of the data label information contained in the data set on the missing data completion model. To this end, this paper proposes a missing data completion model SEGAN based on semi-supervised learning, which mainly includes three important modules: generator, discriminator and classifier. In the SEGAN model, the classifier enables the generator to make more full use of known data and its label information when predicting missing data values. In addition, the SE-GAN model introduces a missing hint matrix to allow the discriminator to more effectively distinguish between known data and data filled by the generator. This paper theoretically proves that the SEGAN model that introduces a classifier and a missing hint matrix can learn the real known data distribution characteristics when reaching Nash equilibrium. Finally, a large number of experiments were conducted in this article, and the experimental results show that com-pared with the current state-of-the-art multivariate data completion method, the performance of the SEGAN model is improved by more than 3%.
Create account to get full access
Overview
- Data missing is a common problem in real-world applications, making it difficult to develop effective data-driven AI.
- Data completion is an important method for preprocessing missing data.
- Existing models use known information in the missing data set but ignore the impact of data label information.
- This paper proposes a missing data completion model called SEGAN based on semi-supervised learning.
Plain English Explanation
In many real-world situations, data can be incomplete or missing, which makes it challenging to develop effective artificial intelligence (AI) systems that rely on data. Data completion is a way to address this problem by filling in the missing parts of the data.
Most existing models for completing missing data directly use the available information in the data set, but they don't consider how the labels or categories assigned to the data might affect the completion process. The paper introduces a new model called SEGAN that incorporates label information to improve the accuracy of missing data completion.
The SEGAN model has three key components: a generator, a discriminator, and a classifier. The classifier helps the generator make better use of the known data and its labels when predicting the missing values. The model also uses a "missing hint matrix" to allow the discriminator to more effectively distinguish between the original data and the data filled in by the generator.
The paper shows that the SEGAN model can learn the real distribution of the known data when it reaches an equilibrium state. In experiments, SEGAN outperformed other state-of-the-art methods for completing multivariate data by more than 3%.
Technical Explanation
The SEGAN model proposed in the paper is based on semi-supervised learning, which means it uses both labeled and unlabeled data to train the model. The three key components of SEGAN are:
- Generator: This module is responsible for predicting the missing values in the data.
- Discriminator: This module tries to distinguish between the original known data and the data filled in by the generator.
- Classifier: This module enables the generator to make better use of the known data and its label information when predicting the missing values.
The paper also introduces a "missing hint matrix" that provides additional information to the discriminator to help it better identify the generated data.
The authors provide a theoretical proof showing that the SEGAN model can learn the true distribution of the known data when it reaches a Nash equilibrium, which is a state where no player (in this case, the generator or discriminator) can improve their performance by changing their strategy unilaterally.
The experimental results demonstrate that SEGAN outperforms other state-of-the-art multivariate data completion methods by more than 3% in terms of performance metrics.
Critical Analysis
The paper presents a novel approach to missing data completion by incorporating label information and a missing hint matrix into a semi-supervised generative adversarial network (GAN) model. This is a promising direction, as label information can provide valuable insights that can improve the accuracy of data completion.
However, the paper does not discuss the limitations of the SEGAN model or potential issues that may arise in real-world applications. For example, the model may struggle with data sets that have complex or nonlinear relationships between features and labels, or in situations where the label information is noisy or unreliable.
Additionally, the paper does not explore the computational complexity of the SEGAN model or its training time, which could be important considerations for practical deployment. Further research is needed to understand the scalability and robustness of the SEGAN approach in diverse data scenarios.
Despite these potential limitations, the SEGAN model represents a valuable contribution to the field of data imputation and federated learning with incomplete data. The incorporation of label information and the missing hint matrix are novel and promising ideas that could inspire further advancements in this area of research.
Conclusion
This paper introduces a novel missing data completion model called SEGAN that leverages semi-supervised learning to make better use of both labeled and unlabeled data. By incorporating a classifier module and a missing hint matrix, SEGAN can learn the true distribution of the known data more effectively than existing methods, resulting in improved performance on multivariate data completion tasks.
While the paper presents promising results, further research is needed to address potential limitations and explore the scalability and robustness of the SEGAN approach in real-world applications. Nevertheless, the ideas introduced in this paper represent an important step forward in the development of robust and accurate data imputation techniques, which are essential for building reliable AI systems in the face of incomplete or missing data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
Ruikai Yang, Fan He, Mingzhen He, Kaijie Wang, Xiaolin Huang
0
0
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60% of the features
5/14/2024
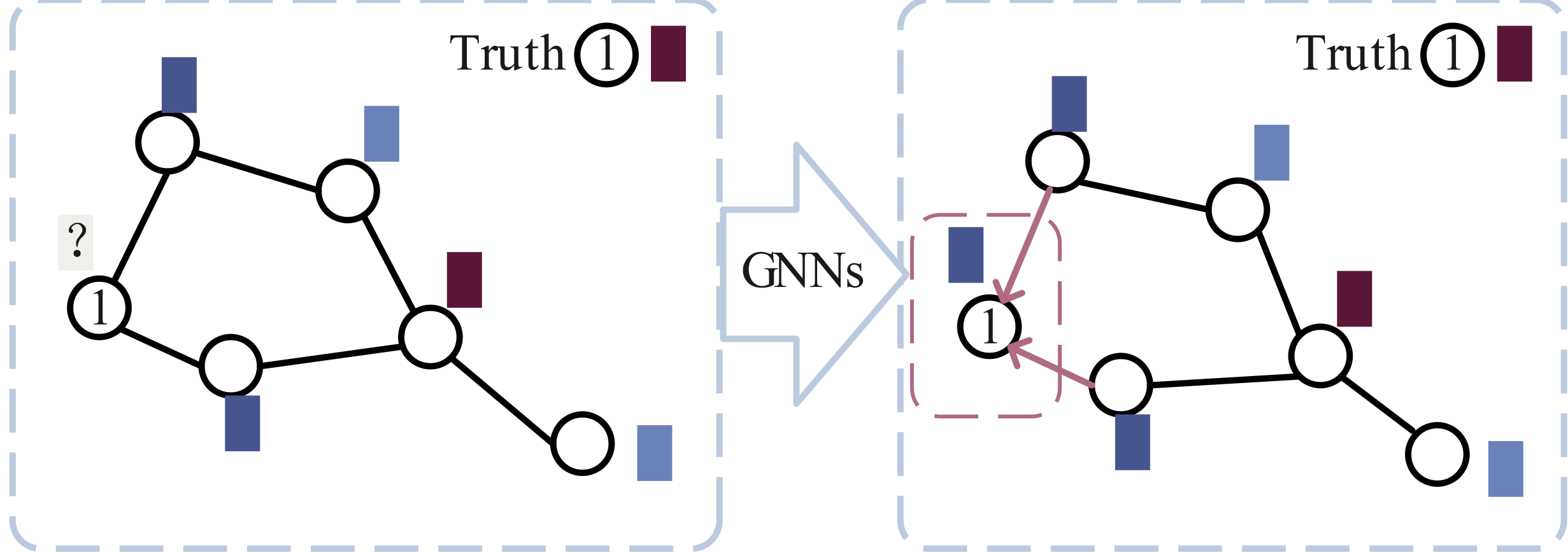
DPGAN: A Dual-Path Generative Adversarial Network for Missing Data Imputation in Graphs
Xindi Zheng, Yuwei Wu, Yu Pan, Wanyu Lin, Lei Ma, Jianjun Zhao
0
0
Missing data imputation poses a paramount challenge when dealing with graph data. Prior works typically are based on feature propagation or graph autoencoders to address this issue. However, these methods usually encounter the over-smoothing issue when dealing with missing data, as the graph neural network (GNN) modules are not explicitly designed for handling missing data. This paper proposes a novel framework, called Dual-Path Generative Adversarial Network (DPGAN), that can deal simultaneously with missing data and avoid over-smoothing problems. The crux of our work is that it admits both global and local representations of the input graph signal, which can capture the long-range dependencies. It is realized via our proposed generator, consisting of two key components, i.e., MLPUNet++ and GraphUNet++. Our generator is trained with a designated discriminator via an adversarial process. In particular, to avoid assessing the entire graph as did in the literature, our discriminator focuses on the local subgraph fidelity, thereby boosting the quality of the local imputation. The subgraph size is adjustable, allowing for control over the intensity of adversarial regularization. Comprehensive experiments across various benchmark datasets substantiate that DPGAN consistently rivals, if not outperforms, existing state-of-the-art imputation algorithms. The code is provided at url{https://github.com/momoxia/DPGAN}.
4/29/2024
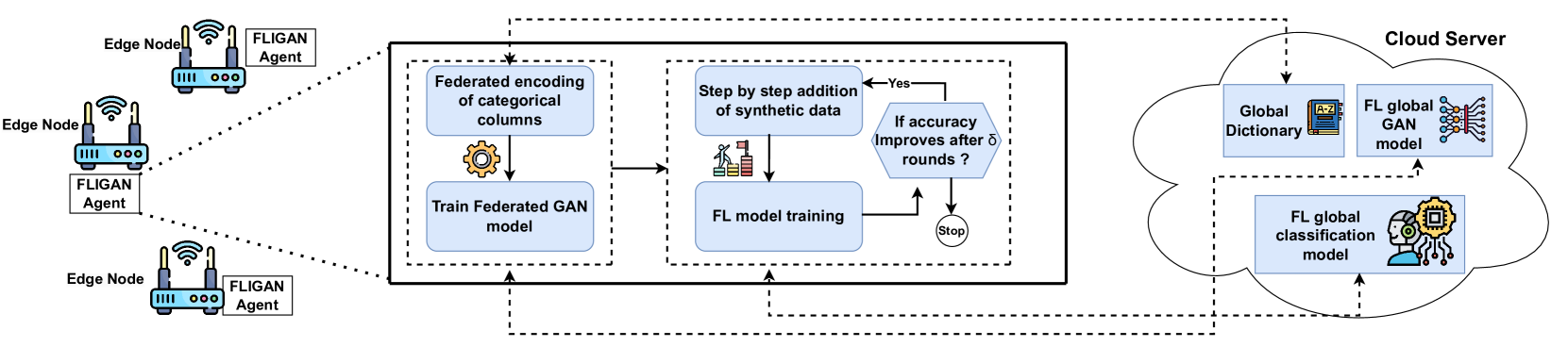
FLIGAN: Enhancing Federated Learning with Incomplete Data using GAN
Paul Joe Maliakel, Shashikant Ilager, Ivona Brandic
0
0
Federated Learning (FL) provides a privacy-preserving mechanism for distributed training of machine learning models on networked devices (e.g., mobile devices, IoT edge nodes). It enables Artificial Intelligence (AI) at the edge by creating models without sharing actual data across the network. Existing research typically focuses on generic aspects of non-IID data and heterogeneity in client's system characteristics, but they often neglect the issue of insufficient data for model development, which can arise from uneven class label distribution and highly variable data volumes across edge nodes. In this work, we propose FLIGAN, a novel approach to address the issue of data incompleteness in FL. First, we leverage Generative Adversarial Networks (GANs) to adeptly capture complex data distributions and generate synthetic data that closely resemble real-world data. Then, we use synthetic data to enhance the robustness and completeness of datasets across nodes. Our methodology adheres to FL's privacy requirements by generating synthetic data in a federated manner without sharing the actual data in the process. We incorporate techniques such as classwise sampling and node grouping, designed to improve the federated GAN's performance, enabling the creation of high-quality synthetic datasets and facilitating efficient FL training. Empirical results from our experiments demonstrate that FLIGAN significantly improves model accuracy, especially in scenarios with high class imbalances, achieving up to a 20% increase in model accuracy over traditional FL baselines.
4/3/2024
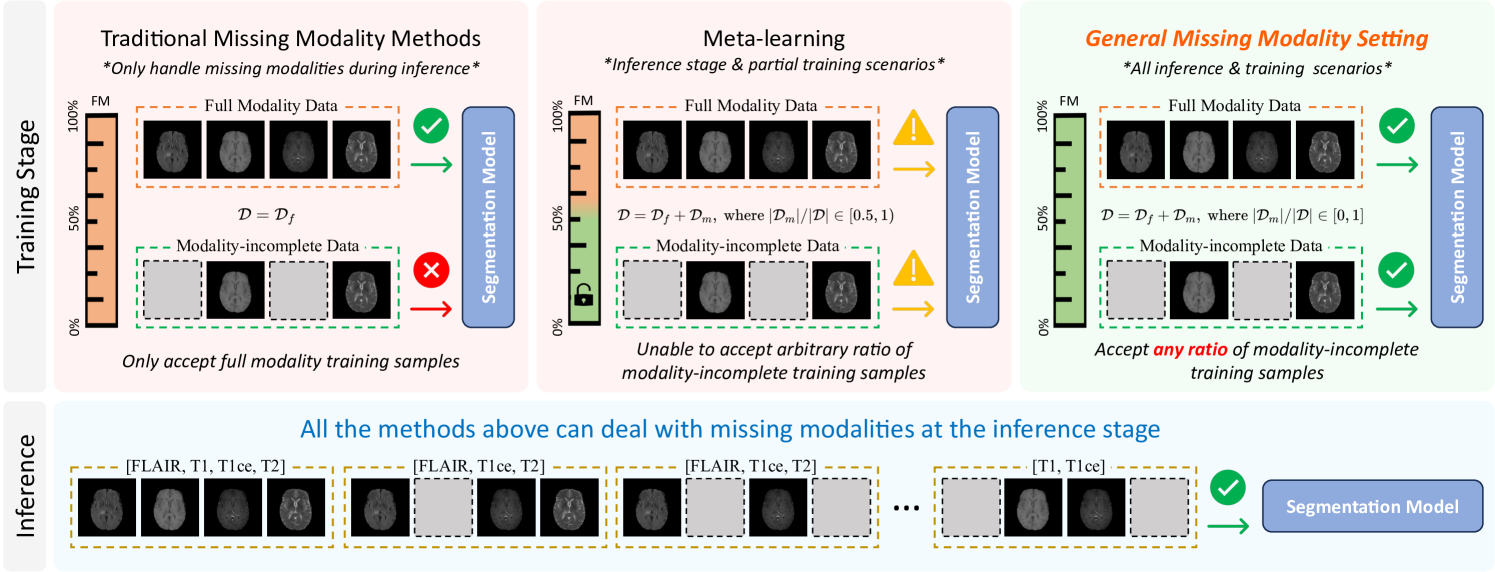
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024