Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
2402.10110
0
0
Abstract
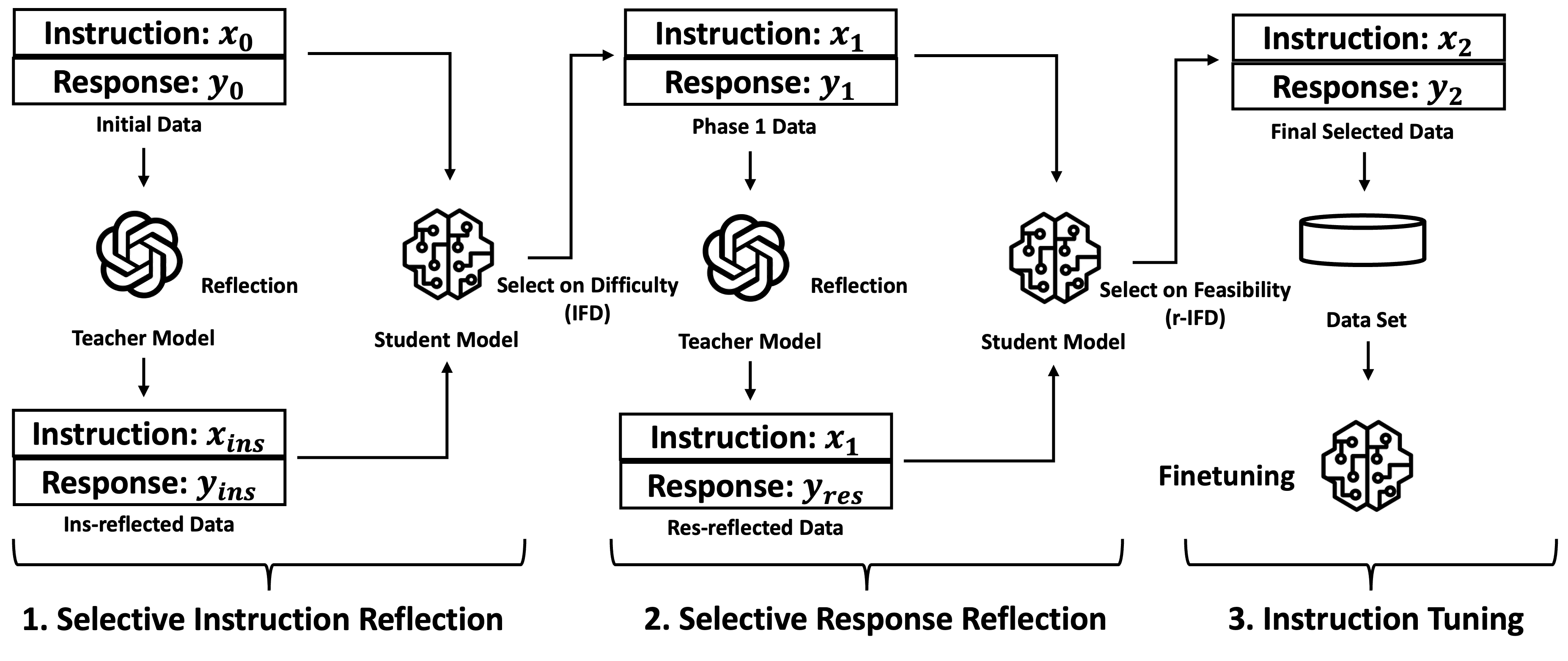
Instruction tuning is critical to large language models (LLMs) for achieving better instruction following and task adaptation capabilities but its success heavily relies on the training data quality. Many recent methods focus on improving the data quality but often overlook the compatibility of the data with the student model being finetuned. This paper introduces Selective Reflection-Tuning, a novel paradigm that synergizes a teacher LLM's reflection and introspection for improving existing data quality with the data selection capability of the student LLM, to automatically refine existing instruction-tuning data. This teacher-student collaboration produces high-quality and student-compatible instruction-response pairs, resulting in sample-efficient instruction tuning and LLMs of superior performance. Selective Reflection-Tuning is a data augmentation and synthesis that generally improves LLM finetuning and self-improvement without collecting brand-new data. We apply our method to Alpaca and WizardLM data and achieve much stronger and top-tier 7B and 13B LLMs.
Create account to get full access
Overview
- This paper proposes a novel approach called "Selective Reflection-Tuning" (SRT) for improving the performance of large language models (LLMs) through instruction-tuning.
- SRT allows students to select data they find useful for fine-tuning the LLM, rather than relying on a fixed dataset.
- The authors hypothesize that this student-driven data selection can lead to more effective and personalized model updates compared to traditional instruction-tuning approaches.
Plain English Explanation
The paper introduces a new way to improve the capabilities of large language models (LLMs) - the powerful AI systems that can understand and generate human-like text. The key idea is to let students (or users) choose the data that the model is trained on, rather than using a fixed dataset.
Normally, when you want to teach an LLM a new skill, you would provide it with a set of example instructions and data. The model would then learn from this data through a process called "instruction-tuning." However, the authors argue that a one-size-fits-all dataset may not be optimal for every student.
Their solution, called "Selective Reflection-Tuning" (SRT), allows students to choose the specific data they find most useful for learning a new task. The model then focuses on learning from this student-selected data, rather than a generic dataset. The authors believe this approach can lead to more personalized and effective model updates, tailored to each student's needs and preferences.
By giving students more control over the learning process, SRT aims to make LLMs more adaptable and responsive to individual users' requirements. This could be particularly useful in educational settings, where students have diverse backgrounds and learning styles.
Technical Explanation
The paper introduces a novel approach called "Selective Reflection-Tuning" (SRT) for improving the performance of large language models (LLMs) through instruction-tuning. SRT allows students to select the data they find useful for fine-tuning the LLM, rather than relying on a fixed dataset.
The key steps of the SRT process are:
-
Instruction-Tuning: The LLM is first fine-tuned on a generic dataset of instructions and corresponding outputs, using standard instruction-tuning techniques.
-
Reflection and Selection: The student is then presented with a set of sample instructions and model outputs. They are asked to reflect on and select the data they find most useful for improving the model's performance on their specific needs.
-
Selective Tuning: The LLM is then further fine-tuned using only the student-selected data, allowing the model to focus on learning from the most relevant information.
The authors hypothesize that this student-driven data selection can lead to more effective and personalized model updates compared to traditional instruction-tuning approaches. By giving students more control over the learning process, SRT aims to make LLMs more adaptable and responsive to individual users' requirements.
The paper includes experiments on various language understanding and generation tasks, demonstrating the benefits of SRT over standard instruction-tuning methods. The results suggest that SRT can lead to significant performance improvements, especially for students with specific learning needs or preferences.
Critical Analysis
The paper presents a promising approach to improving the effectiveness of instruction-tuning for large language models. By allowing students to select the data used for fine-tuning, SRT addresses a key limitation of traditional instruction-tuning methods, which rely on a fixed dataset that may not be optimal for all users.
One potential concern raised in the paper is the potential for bias in the student-selected data. If students systematically choose data that aligns with their own biases or preferences, this could lead to models that perform well on those specific tasks but generalize poorly to broader applications. The authors acknowledge this challenge and suggest potential mitigation strategies, such as providing guidance to students on selecting a diverse and representative set of data.
Another area for further research is the scalability of the SRT approach. While the paper demonstrates the benefits of SRT on a relatively small scale, it's unclear how well the method would scale to large-scale, real-world deployments with thousands or millions of users. Practical considerations around data storage, computation, and model updates would need to be addressed.
Overall, the Selective Reflection-Tuning approach presented in this paper represents an interesting and potentially impactful direction for improving the personalization and effectiveness of large language models. As the field of AI continues to evolve, techniques like SRT that empower users and promote more collaborative learning between humans and machines may become increasingly important.
Conclusion
The "Selective Reflection-Tuning" (SRT) approach proposed in this paper offers a novel way to enhance the performance of large language models through instruction-tuning. By allowing students to select the data used for fine-tuning, SRT aims to create more personalized and effective model updates, tailored to individual users' needs and preferences.
The key innovation of SRT is its focus on student-driven data selection, which contrasts with traditional instruction-tuning methods that rely on fixed datasets. This student-centric approach has the potential to make LLMs more adaptable and responsive to diverse user requirements, particularly in educational and other personalized learning contexts.
While the paper identifies some potential challenges, such as data bias, the overall findings suggest that SRT could lead to significant performance improvements compared to standard instruction-tuning techniques. As the field of AI continues to evolve, approaches like SRT that empower users and promote more collaborative learning between humans and machines may become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024
🚀
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, Jing Xiao
0
0
In the realm of Large Language Models (LLMs), the balance between instruction data quality and quantity is a focal point. Recognizing this, we introduce a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, effectively minimizing manual curation and potential cost for instruction tuning an LLM. Our key innovation, the Instruction-Following Difficulty (IFD) metric, emerges as a pivotal metric to identify discrepancies between a model's expected responses and its intrinsic generation capability. Through the application of IFD, cherry samples can be pinpointed, leading to a marked uptick in model training efficiency. Empirical validations on datasets like Alpaca and WizardLM underpin our findings; with a mere $10%$ of original data input, our strategy showcases improved results. This synthesis of self-guided cherry-picking and the IFD metric signifies a transformative leap in the instruction tuning of LLMs, promising both efficiency and resource-conscious advancements. Codes, data, and models are available: https://github.com/tianyi-lab/Cherry_LLM
4/9/2024
💬
Supporting Self-Reflection at Scale with Large Language Models: Insights from Randomized Field Experiments in Classrooms
Harsh Kumar, Ruiwei Xiao, Benjamin Lawson, Ilya Musabirov, Jiakai Shi, Xinyuan Wang, Huayin Luo, Joseph Jay Williams, Anna Rafferty, John Stamper, Michael Liut
0
0
Self-reflection on learning experiences constitutes a fundamental cognitive process, essential for the consolidation of knowledge and the enhancement of learning efficacy. However, traditional methods to facilitate reflection often face challenges in personalization, immediacy of feedback, engagement, and scalability. Integration of Large Language Models (LLMs) into the reflection process could mitigate these limitations. In this paper, we conducted two randomized field experiments in undergraduate computer science courses to investigate the potential of LLMs to help students engage in post-lesson reflection. In the first experiment (N=145), students completed a take-home assignment with the support of an LLM assistant; half of these students were then provided access to an LLM designed to facilitate self-reflection. The results indicated that the students assigned to LLM-guided reflection reported increased self-confidence and performed better on a subsequent exam two weeks later than their peers in the control condition. In the second experiment (N=112), we evaluated the impact of LLM-guided self-reflection against other scalable reflection methods, such as questionnaire-based activities and review of key lecture slides, after assignment. Our findings suggest that the students in the questionnaire and LLM-based reflection groups performed equally well and better than those who were only exposed to lecture slides, according to their scores on a proctored exam two weeks later on the same subject matter. These results underscore the utility of LLM-guided reflection and questionnaire-based activities in improving learning outcomes. Our work highlights that focusing solely on the accuracy of LLMs can overlook their potential to enhance metacognitive skills through practices such as self-reflection. We discuss the implications of our research for the Edtech community.
6/13/2024

Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Yipeng Zhang, Haitao Mi, Helen Meng
0
0
Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM's ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. In addition, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM's knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
6/18/2024