Self-Cognition in Large Language Models: An Exploratory Study
2407.01505
0
0

Abstract
While Large Language Models (LLMs) have achieved remarkable success across various applications, they also raise concerns regarding self-cognition. In this paper, we perform a pioneering study to explore self-cognition in LLMs. Specifically, we first construct a pool of self-cognition instruction prompts to evaluate where an LLM exhibits self-cognition and four well-designed principles to quantify LLMs' self-cognition. Our study reveals that 4 of the 48 models on Chatbot Arena--specifically Command R, Claude3-Opus, Llama-3-70b-Instruct, and Reka-core--demonstrate some level of detectable self-cognition. We observe a positive correlation between model size, training data quality, and self-cognition level. Additionally, we also explore the utility and trustworthiness of LLM in the self-cognition state, revealing that the self-cognition state enhances some specific tasks such as creative writing and exaggeration. We believe that our work can serve as an inspiration for further research to study the self-cognition in LLMs.
Create account to get full access
Overview
• This paper explores the concept of "self-cognition" in large language models (LLMs), which refers to the models' ability to understand and reason about their own inner workings and capabilities.
• The researchers conducted a series of experiments to investigate how well LLMs can comprehend their own knowledge, limitations, and decision-making processes.
• The findings shed light on the potential and challenges of developing LLMs with stronger self-awareness and self-evaluation capabilities.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a variety of language-related tasks. However, these models often operate as "black boxes," where their inner workings and decision-making processes are not fully transparent to their human users.
The researchers in this study wanted to explore whether LLMs can develop a better understanding of their own capabilities and limitations. They call this "self-cognition" - the ability of the model to comprehend its own knowledge, strengths, and weaknesses.
To investigate this, the researchers conducted a series of experiments where they asked the LLMs to evaluate their own performance on various tasks, such as answering questions or generating text. The models were also asked to assess their own confidence in their responses and to identify areas where they might be uncertain or make mistakes.
The findings suggest that LLMs can indeed develop some level of self-awareness and self-evaluation capabilities, but there are also significant limitations. The models were often overconfident in their abilities and struggled to accurately identify their own mistakes or knowledge gaps.
The researchers believe that improving self-cognition in LLMs could have important implications for making these systems more transparent, reliable, and trustworthy. By better understanding their own strengths and weaknesses, LLMs could become more accountable and better aligned with human values and goals.
However, developing robust self-cognition in LLMs is a challenging task, and more research is needed to overcome the current limitations. The paper provides a valuable starting point for exploring this important aspect of AI development.
Technical Explanation
The researchers conducted a series of experiments to investigate self-cognition in large language models. They used several state-of-the-art LLMs, including GPT-3, InstructGPT, and Megatron-LM, and designed tasks that tested the models' ability to understand and reason about their own capabilities and decision-making processes.
One experiment involved asking the LLMs to evaluate their own performance on a question-answering task. The models were presented with questions and asked to rate their confidence in their responses on a scale from 1 to 5. The researchers found that the models were often overconfident, rating their responses as highly confident even when they were incorrect.
In another experiment, the LLMs were asked to identify their own mistakes and explain their reasoning. The models struggled to accurately pinpoint their errors and frequently failed to provide meaningful explanations for their decisions.
The researchers also explored the models' ability to self-train and self-evaluate their own knowledge and capabilities. They found that while the LLMs could to some extent self-assess their performance, they often exhibited significant biases and limitations in their self-evaluations.
Overall, the findings suggest that while LLMs can develop a certain degree of self-awareness and self-evaluation capabilities, they are far from achieving human-like self-cognition. The researchers highlight the need for further research and development to address the current limitations and enable LLMs to better understand and reason about their own inner workings.
Critical Analysis
The paper provides a valuable contribution to the emerging field of self-cognition in LLMs, but it also acknowledges several important caveats and limitations.
One key limitation is the relatively narrow scope of the experiments, which focused primarily on question-answering tasks and self-evaluation. The researchers note that self-cognition in LLMs is a complex and multifaceted phenomenon, and the current study may not capture the full breadth of the models' self-awareness capabilities.
Additionally, the study relied on a limited set of LLM architectures, and it's unclear how the findings might generalize to other state-of-the-art models or future developments in the field. The researchers encourage further exploration of self-cognition across a wider range of LLM systems and task domains.
Another potential issue is the inherent challenge of accurately measuring and assessing self-cognition in AI systems. The researchers acknowledge that their experimental design and evaluation metrics may not fully capture the nuances of how LLMs comprehend and reason about their own inner workings.
Despite these limitations, the paper provides valuable insights and serves as an important starting point for further research in this emerging area of AI development. By shedding light on the current capabilities and limitations of LLMs in terms of self-cognition, the study can help guide future efforts to create more transparent, accountable, and trustworthy AI systems.
Conclusion
This exploratory study on self-cognition in large language models (LLMs) offers a valuable contribution to the growing body of research on the inner workings and self-awareness capabilities of these powerful AI systems.
The findings suggest that while LLMs can develop some level of self-awareness and self-evaluation skills, they are far from achieving human-like self-cognition. The models often exhibit overconfidence and struggle to accurately identify their own mistakes or knowledge gaps.
Improving self-cognition in LLMs could have significant implications for making these systems more transparent, reliable, and trustworthy. By better understanding their own strengths, weaknesses, and decision-making processes, LLMs could become more accountable and better aligned with human values and goals.
However, the development of robust self-cognition in LLMs is a complex and challenging task, and further research is needed to overcome the current limitations. The paper provides a valuable starting point for exploring this important aspect of AI development and highlights the need for continued exploration and innovation in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
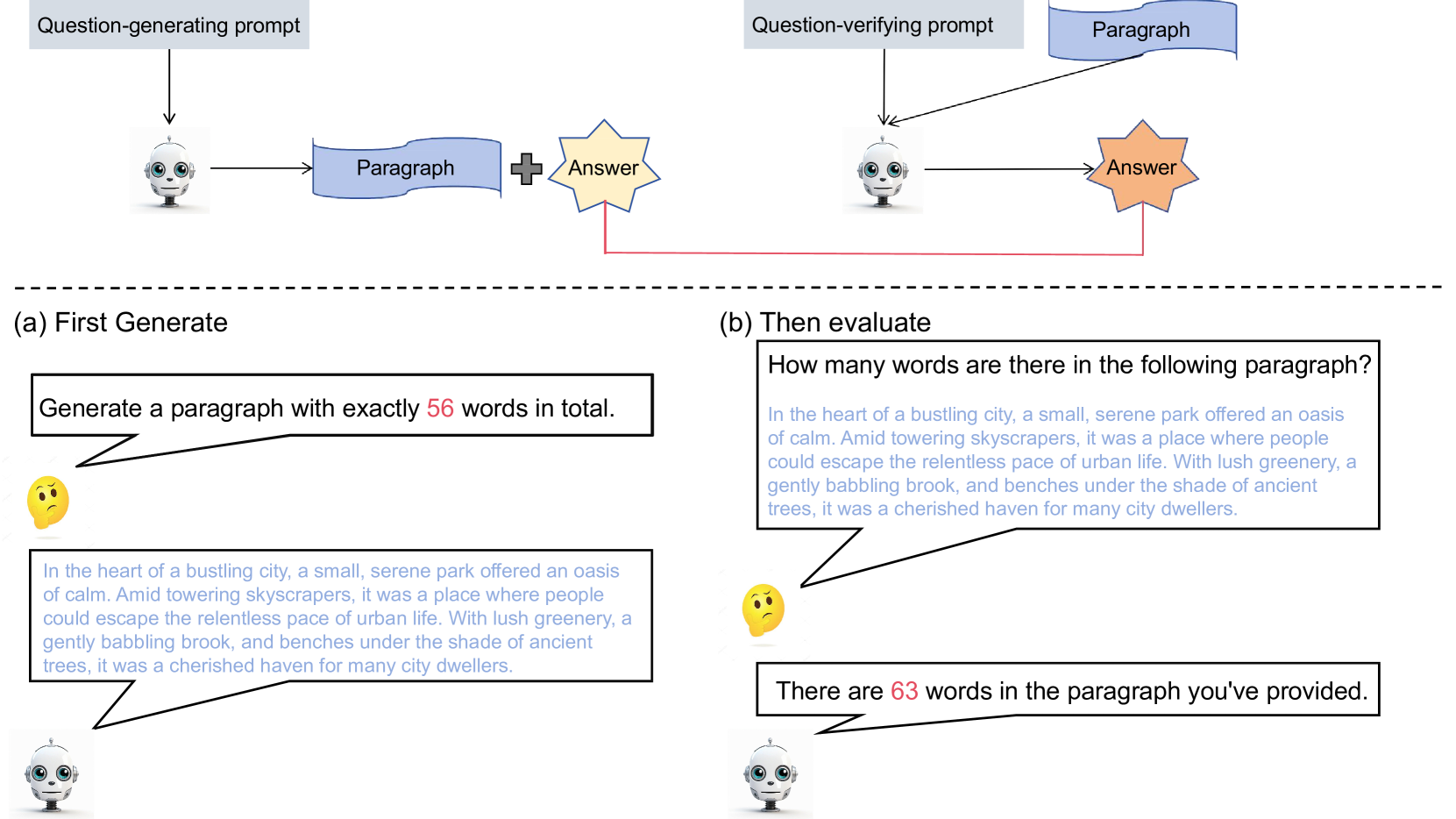
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Zhiquan Tan, Lai Wei, Jindong Wang, Xing Xie, Weiran Huang
0
0
Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
6/11/2024
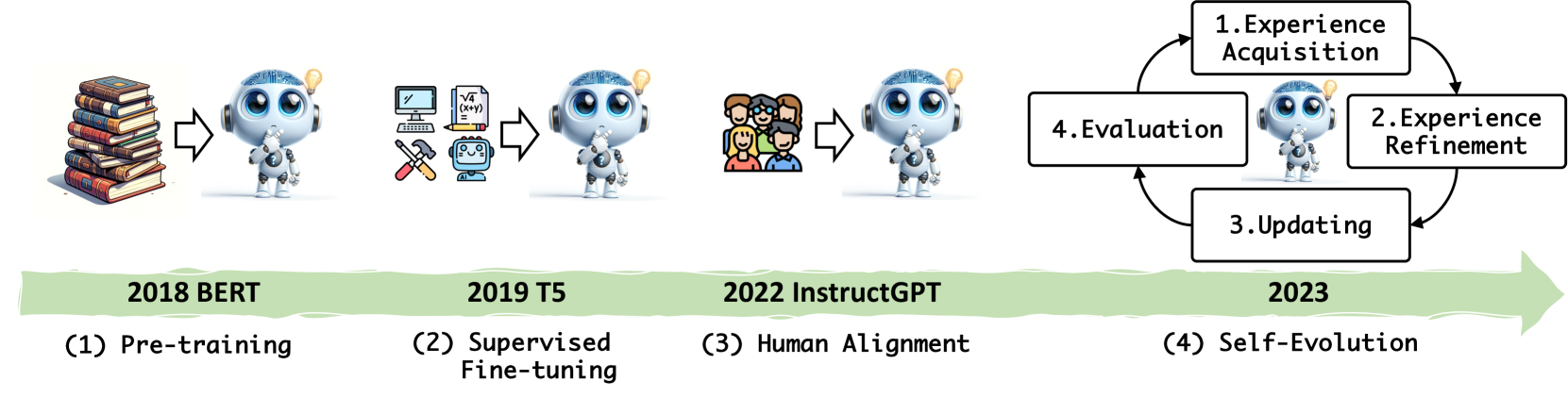
A Survey on Self-Evolution of Large Language Models
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou
0
0
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs. Our corresponding GitHub repository is available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
6/4/2024
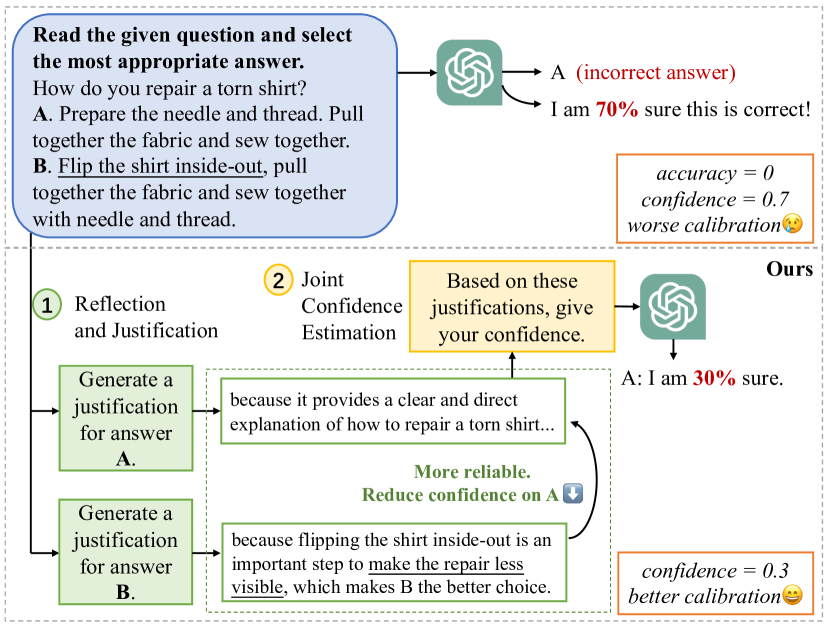
Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, Tat-Seng Chua
0
0
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
6/5/2024
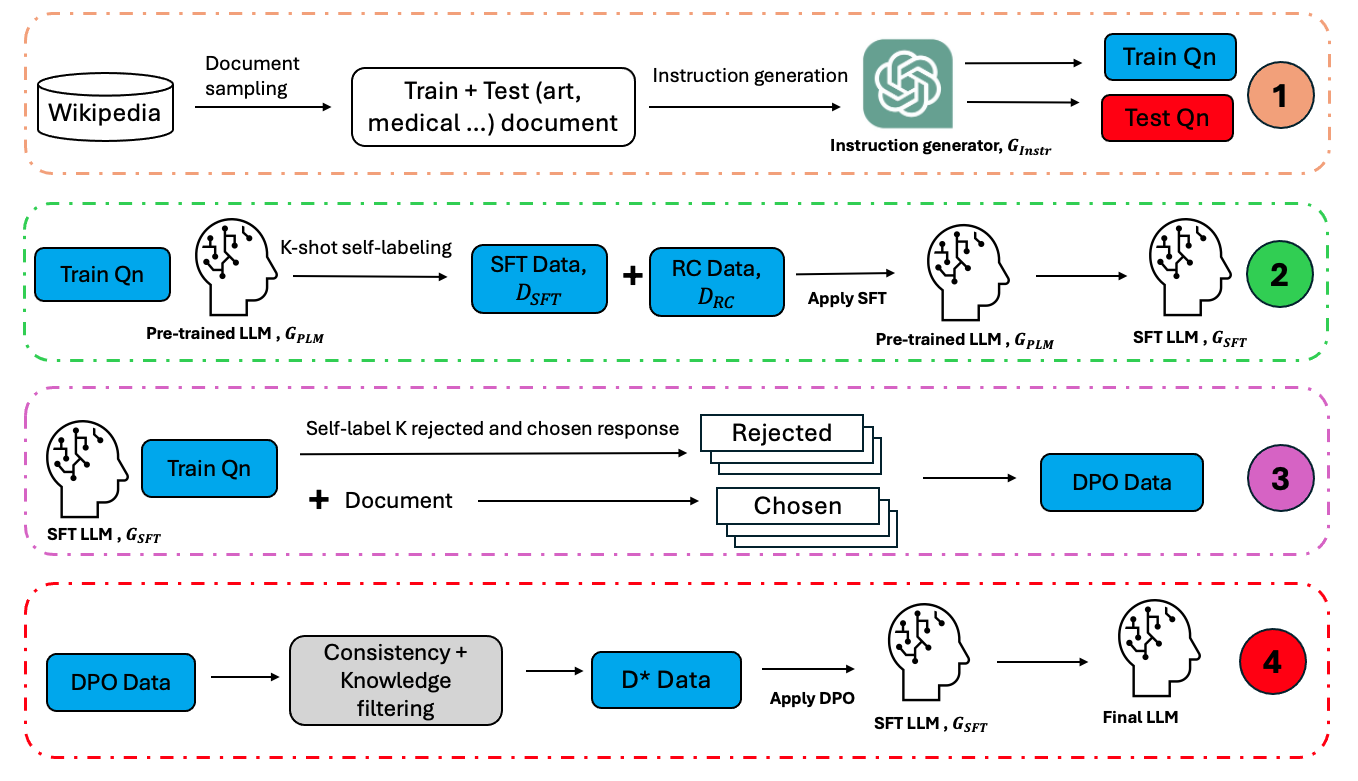
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
0
0
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
6/18/2024