Self-Distillation Improves DNA Sequence Inference

0
🤯
Sign in to get full access
Overview
- Self-supervised pretraining (SSP) is a method used to enhance prediction accuracy in various downstream tasks.
- However, its effectiveness for DNA sequences has been somewhat limited, as most existing SSP approaches in genomics focus on masked language modeling of individual sequences, overlooking the crucial aspect of encoding statistics across multiple sequences.
- To address this challenge, the researchers introduce a deep neural network model that incorporates collaborative learning between a 'student' and a 'teacher' subnetwork.
Plain English Explanation
The paper presents a new approach to self-supervised pretraining for DNA sequences. Traditional methods have focused on training models to predict missing parts of individual DNA sequences, but this can miss important information about how DNA sequences behave as a population.
The researchers' model instead has two parts: a 'student' network that learns to predict missing DNA bases, and a 'teacher' network that guides the student's learning. The student and teacher work together, with the student constantly updating its parameters to match the teacher's. Additionally, both networks try to learn contrasting representations of the DNA sequences, allowing them to capture both the individual context and the broader statistical patterns in the data.
This self-distillation process enables the model to effectively learn from both the individual DNA sequences and the overall distribution of sequences, leading to significant performance improvements on a variety of downstream tasks related to DNA analysis.
Technical Explanation
The key innovation in this paper is the use of a collaborative learning approach between a student and teacher subnetwork. The student subnetwork employs masked learning on the nucleotides in the DNA sequences, progressively adapting its parameters to match those of the teacher subnetwork through an exponential moving average.
Concurrently, both the student and teacher subnetworks engage in contrastive learning, deriving insights from two augmented representations of the input DNA sequences. This self-distillation process allows the model to effectively capture both the contextual information from individual sequences and the distributional data across the sequence population.
The researchers validated their approach by first pretraining the model on the human reference genome, and then applying it to 20 downstream inference tasks. The empirical results demonstrate that this novel method significantly boosts inference performance across the majority of these tasks compared to previous approaches.
Critical Analysis
The paper addresses an important limitation in existing self-supervised pretraining methods for DNA sequences, which have primarily focused on individual sequences rather than the broader distributional patterns. The collaborative learning approach between the student and teacher subnetworks is a clever way to capture both contextual and statistical information from the data.
However, the paper does not provide a detailed analysis of the model's performance on specific downstream tasks or the relative contributions of the different components (e.g., masked learning, contrastive learning, self-distillation) to the overall improvements. Additionally, the generalizability of the approach to other types of biological sequences or datasets is not fully explored.
Further research could investigate the model's behavior on a wider range of downstream tasks, as well as comparisons to other self-supervised pretraining techniques in genomics. Exploring the scalability and computational efficiency of the approach would also be valuable.
Conclusion
This paper presents a novel self-supervised pretraining method for DNA sequences that leverages collaborative learning between student and teacher subnetworks. By capturing both individual sequence context and distributional patterns, the model achieves significant performance improvements on a variety of downstream inference tasks related to DNA analysis. The approach offers a promising direction for enhancing the effectiveness of self-supervised learning in the field of genomics, with potential applications in areas such as disease prediction, drug discovery, and evolutionary biology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Self-Distillation Improves DNA Sequence Inference
Tong Yu, Lei Cheng, Ruslan Khalitov, Erland Brandser Olsson, Zhirong Yang
Self-supervised pretraining (SSP) has been recognized as a method to enhance prediction accuracy in various downstream tasks. However, its efficacy for DNA sequences remains somewhat constrained. This limitation stems primarily from the fact that most existing SSP approaches in genomics focus on masked language modeling of individual sequences, neglecting the crucial aspect of encoding statistics across multiple sequences. To overcome this challenge, we introduce an innovative deep neural network model, which incorporates collaborative learning between a `student' and a `teacher' subnetwork. In this model, the student subnetwork employs masked learning on nucleotides and progressively adapts its parameters to the teacher subnetwork through an exponential moving average approach. Concurrently, both subnetworks engage in contrastive learning, deriving insights from two augmented representations of the input sequences. This self-distillation process enables our model to effectively assimilate both contextual information from individual sequences and distributional data across the sequence population. We validated our approach with preliminary pretraining using the human reference genome, followed by applying it to 20 downstream inference tasks. The empirical results from these experiments demonstrate that our novel method significantly boosts inference performance across the majority of these tasks. Our code is available at https://github.com/wiedersehne/FinDNA.
Read more5/15/2024
🧠
0
Self-Distillation Learning Based on Temporal-Spatial Consistency for Spiking Neural Networks
Lin Zuo, Yongqi Ding, Mengmeng Jing, Kunshan Yang, Yunqian Yu
Spiking neural networks (SNNs) have attracted considerable attention for their event-driven, low-power characteristics and high biological interpretability. Inspired by knowledge distillation (KD), recent research has improved the performance of the SNN model with a pre-trained teacher model. However, additional teacher models require significant computational resources, and it is tedious to manually define the appropriate teacher network architecture. In this paper, we explore cost-effective self-distillation learning of SNNs to circumvent these concerns. Without an explicit defined teacher, the SNN generates pseudo-labels and learns consistency during training. On the one hand, we extend the timestep of the SNN during training to create an implicit temporal ``teacher that guides the learning of the original ``student, i.e., the temporal self-distillation. On the other hand, we guide the output of the weak classifier at the intermediate stage by the final output of the SNN, i.e., the spatial self-distillation. Our temporal-spatial self-distillation (TSSD) learning method does not introduce any inference overhead and has excellent generalization ability. Extensive experiments on the static image datasets CIFAR10/100 and ImageNet as well as the neuromorphic datasets CIFAR10-DVS and DVS-Gesture validate the superior performance of the TSSD method. This paper presents a novel manner of fusing SNNs with KD, providing insights into high-performance SNN learning methods.
Read more6/13/2024
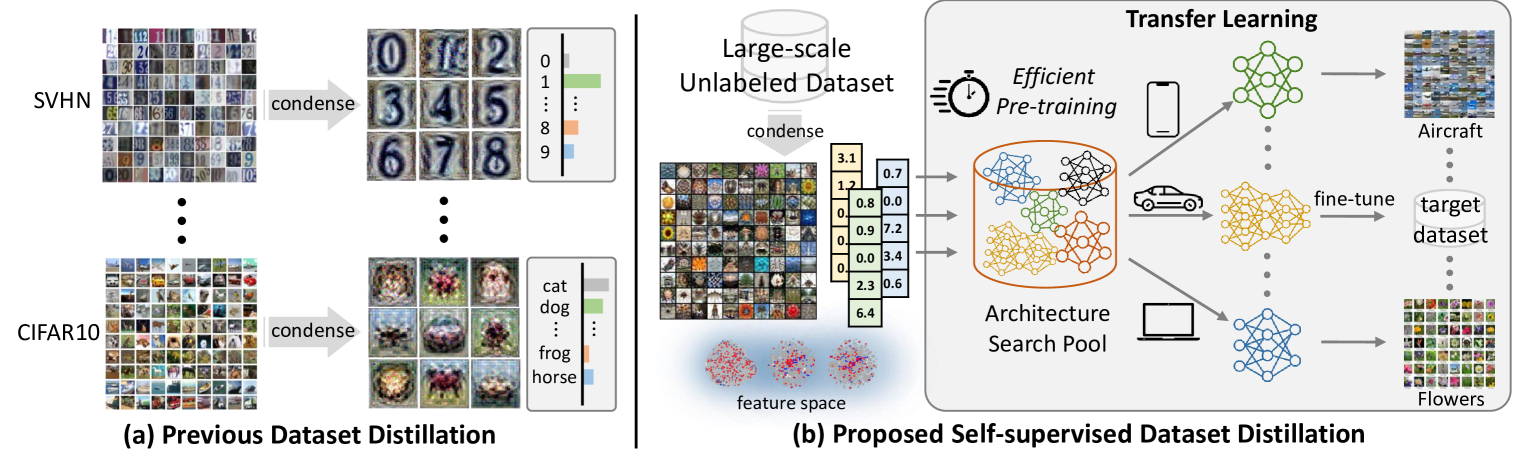
0
Self-Supervised Dataset Distillation for Transfer Learning
Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, Sung Ju Hwang
Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
Read more4/15/2024

0
Leave No One Behind: Online Self-Supervised Self-Distillation for Sequential Recommendation
Shaowei Wei, Zhengwei Wu, Xin Li, Qintong Wu, Zhiqiang Zhang, Jun Zhou, Lihong Gu, Jinjie Gu
Sequential recommendation methods play a pivotal role in modern recommendation systems. A key challenge lies in accurately modeling user preferences in the face of data sparsity. To tackle this challenge, recent methods leverage contrastive learning (CL) to derive self-supervision signals by maximizing the mutual information of two augmented views of the original user behavior sequence. Despite their effectiveness, CL-based methods encounter a limitation in fully exploiting self-supervision signals for users with limited behavior data, as users with extensive behaviors naturally offer more information. To address this problem, we introduce a novel learning paradigm, named Online Self-Supervised Self-distillation for Sequential Recommendation ($S^4$Rec), effectively bridging the gap between self-supervised learning and self-distillation methods. Specifically, we employ online clustering to proficiently group users by their distinct latent intents. Additionally, an adversarial learning strategy is utilized to ensure that the clustering procedure is not affected by the behavior length factor. Subsequently, we employ self-distillation to facilitate the transfer of knowledge from users with extensive behaviors (teachers) to users with limited behaviors (students). Experiments conducted on four real-world datasets validate the effectiveness of the proposed methodfootnote{Code is available at https://github.com/xjaw/S4Rec
Read more4/12/2024