Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
2401.01335
41
0

Abstract
Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong LLM out of a weak one without the need for acquiring additional human-annotated data. We propose a new fine-tuning method called Self-Play fIne-tuNing (SPIN), which starts from a supervised fine-tuned model. At the heart of SPIN lies a self-play mechanism, where the LLM refines its capability by playing against instances of itself. More specifically, the LLM generates its own training data from its previous iterations, refining its policy by discerning these self-generated responses from those obtained from human-annotated data. Our method progressively elevates the LLM from a nascent model to a formidable one, unlocking the full potential of human-annotated demonstration data for SFT. Theoretically, we prove that the global optimum to the training objective function of our method is achieved only when the LLM policy aligns with the target data distribution. Empirically, we evaluate our method on several benchmark datasets including the HuggingFace Open LLM Leaderboard, MT-Bench, and datasets from Big-Bench. Our results show that SPIN can significantly improve the LLM's performance across a variety of benchmarks and even outperform models trained through direct preference optimization (DPO) supplemented with extra GPT-4 preference data. This sheds light on the promise of self-play, enabling the achievement of human-level performance in LLMs without the need for expert opponents. Codes are available at https://github.com/uclaml/SPIN.
Create account to get full access
Overview
- This paper explores a novel approach called "self-play fine-tuning" that can transform weak language models into strong, high-performing ones.
- The authors demonstrate how this technique can effectively train language models to exhibit strong reasoning abilities, outperforming alternative fine-tuning methods.
- The research provides insights into how language models can be optimized for tasks requiring advanced reasoning skills, which has significant implications for developing more capable and versatile AI systems.
Plain English Explanation
The researchers in this study were interested in finding ways to make language models, which are AI systems that can understand and generate human language, become better at reasoning and problem-solving. Typically, language models are trained on large datasets of text, which allows them to learn the patterns and structures of language. However, this approach can result in models that struggle with tasks that require deeper reasoning or more advanced cognitive abilities.
To address this, the researchers developed a technique called "self-play fine-tuning." The core idea is to have the language model engage in a sort of "dialogue" with itself, where it takes on different roles and perspectives to solve complex problems. By going through this self-play process, the model can learn to reason more effectively and develop stronger problem-solving skills.
The researchers found that this self-play fine-tuning approach was able to transform weak language models - models that were not very good at reasoning - into much stronger and more capable models. These improved models were able to outperform other fine-tuning methods on a variety of tasks that required advanced reasoning abilities.
This research is significant because it provides a way to develop more versatile and capable AI systems that can excel at a wider range of tasks, including those that demand higher-level cognitive skills. By optimizing language models for reasoning, the researchers have taken an important step towards creating AI that can truly understand and engage with the world in more meaningful and intelligent ways.
Technical Explanation
The paper introduces a novel technique called "self-play fine-tuning" that can effectively convert weak language models into strong, high-performing models. The key idea is to have the language model engage in a self-directed dialogue, where it takes on different roles and perspectives to solve complex problems. This self-play process allows the model to learn more effective reasoning strategies, which can then be leveraged to improve its performance on a variety of tasks.
To evaluate this approach, the researchers conducted experiments comparing self-play fine-tuning to alternative fine-tuning methods, such as those used in Investigating Regularization and Optimization for Self-Play Language Models, Optimizing Language Models for Reasoning Abilities with Weak Supervision, and Self-Evolution: Fine-Tuning and Policy Optimization. The results showed that self-play fine-tuning was able to transform weak language models into significantly stronger performers, outpacing the other fine-tuning approaches on a range of tasks that required advanced reasoning skills.
The researchers also drew connections to related work in Self-Play Preference Optimization for Language Model Alignment and Teaching Language Models to Self-Improve by Interacting with Humans, which explore similar ideas of using self-directed interactions to enhance language model capabilities.
Critical Analysis
The paper presents a compelling approach to improving language model performance, particularly on tasks that require strong reasoning abilities. The self-play fine-tuning technique is a clever and innovative way to leverage the model's own internal "dialogue" to drive learning and development.
One potential limitation of the study is the reliance on synthetic tasks and datasets to evaluate the model's reasoning skills. While these controlled experiments provide valuable insights, it would be important to also assess the model's performance on real-world, naturalistic tasks that capture the full complexity of human reasoning and problem-solving.
Additionally, the paper does not delve deeply into the specific mechanisms or dynamics underlying the self-play process. A more detailed exploration of how the model's internal representations and decision-making evolve during this fine-tuning could yield further insights and potentially inform the design of even more effective training approaches.
It would also be interesting to see how the self-play fine-tuning technique might interact with or complement other recent advancements in language model optimization, such as prompt engineering, knowledge distillation, or continual learning. Investigating these synergies could lead to even more powerful and versatile AI systems.
Conclusion
This research represents an important step forward in the development of more capable and reasoning-oriented language models. The self-play fine-tuning approach demonstrated in this paper has the potential to significantly enhance the problem-solving and cognitive abilities of AI systems, with wide-ranging implications for various applications that require advanced reasoning skills.
By unlocking more powerful language models through self-directed learning, the researchers have opened up new avenues for creating AI systems that can better understand and engage with the complexities of the world around them. As this field of research continues to evolve, we can expect to see even more impressive advancements in the capabilities of language models and their broader impact on society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Investigating Regularization of Self-Play Language Models
Reda Alami, Abdalgader Abubaker, Mastane Achab, Mohamed El Amine Seddik, Salem Lahlou
0
0
This paper explores the effects of various forms of regularization in the context of language model alignment via self-play. While both reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) require to collect costly human-annotated pairwise preferences, the self-play fine-tuning (SPIN) approach replaces the rejected answers by data generated from the previous iterate. However, the SPIN method presents a performance instability issue in the learning phase, which can be mitigated by playing against a mixture of the two previous iterates. In the same vein, we propose in this work to address this issue from two perspectives: first, by incorporating an additional Kullback-Leibler (KL) regularization to stay at the proximity of the reference policy; second, by using the idea of fictitious play which smoothens the opponent policy across all previous iterations. In particular, we show that the KL-based regularizer boils down to replacing the previous policy by its geometric mixture with the base policy inside of the SPIN loss function. We finally discuss empirical results on MT-Bench as well as on the Hugging Face Open LLM Leaderboard.
4/9/2024
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
Self-Evolution Fine-Tuning for Policy Optimization
Ruijun Chen, Jiehao Liang, Shiping Gao, Fanqi Wan, Xiaojun Quan
0
0
The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
6/18/2024
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
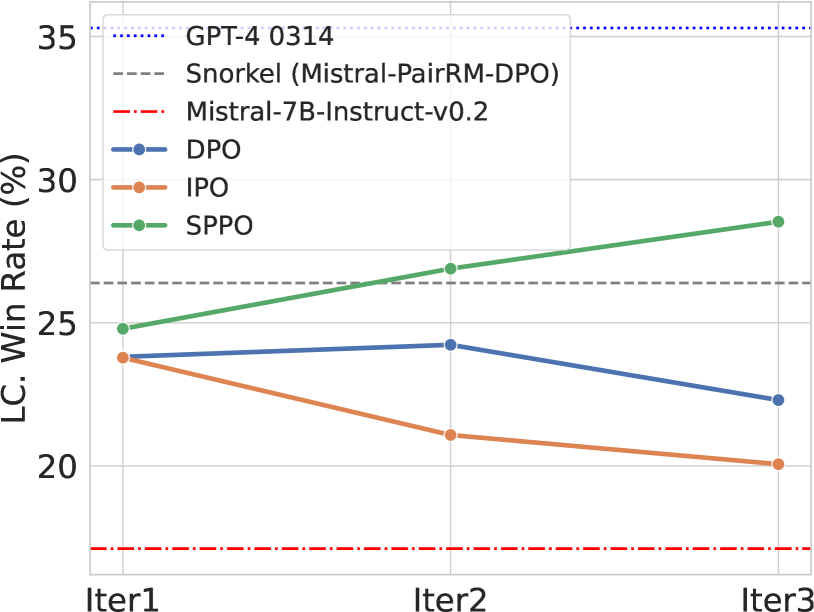
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
6/17/2024